M1guelpf
Models by this creator

nsfw-filter

3.8K
The nsfw-filter model is a modified implementation of the example code provided in the Red-Teaming the Stable Diffusion Safety Filter paper. This model is designed to run any image through the Stable Diffusion content filter, providing a way to detect and filter out potentially NSFW (Not Safe For Work) content. The model is packaged as a Cog model, a tool that packages machine learning models as standard containers. Similar models in this space include Stable Diffusion, a latent text-to-image diffusion model capable of generating photo-realistic images, the Stable Diffusion Upscaler for upscaling images, and the Stable Diffusion 2-1-unclip Model. Model inputs and outputs The nsfw-filter model takes a single input: an image to be run through the NSFW filter. The output is a JSON object with the filtered image and a boolean value indicating whether the image is considered NSFW. Inputs Image**: The image to be run through the NSFW filter. Outputs Image**: The filtered image. Is NSFW**: A boolean value indicating whether the image is considered NSFW. Capabilities The nsfw-filter model is capable of detecting and filtering out potentially NSFW content in images. This can be useful for a variety of applications, such as content moderation, image curation, or building safe-for-work environments. What can I use it for? The nsfw-filter model can be used to build applications that require content filtering, such as social media platforms, online communities, or image-based services. By integrating this model, you can ensure that your platform or service remains safe and family-friendly. Things to try One interesting thing to try with the nsfw-filter model is to experiment with different types of images, from portraits to landscapes, to see how the model performs. You can also try using the model in combination with other Stable Diffusion-based models, such as the Stable Diffusion Upscaler or the Stable Diffusion 2-1-unclip Model, to create a comprehensive image processing pipeline.
Updated 7/4/2024
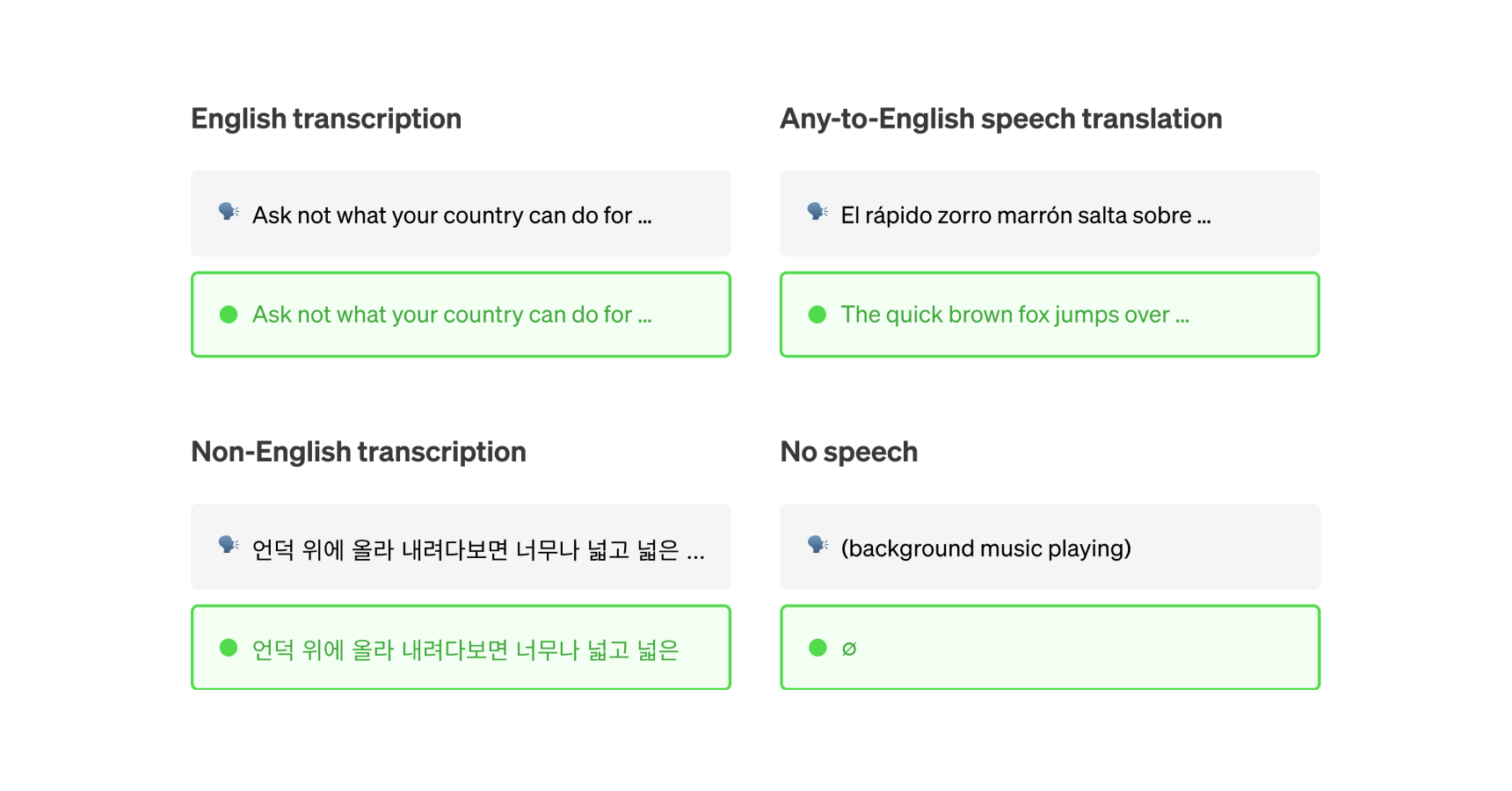
whisper-subtitles
51
The whisper-subtitles model is a variation of OpenAI's Whisper, a general-purpose speech recognition model. Like the original Whisper model, this model is capable of transcribing speech in audio files, with support for multiple languages. The key difference is that whisper-subtitles is specifically designed to generate subtitles in either SRT or VTT format, making it a convenient tool for creating captions or subtitles for audio and video content. Model inputs and outputs The whisper-subtitles model takes two main inputs: audio_path**: the path to the audio file to be transcribed model_name**: the name of the Whisper model to use, with options like tiny, base, small, medium, and large The model outputs a JSON object containing the transcribed text, with timestamps for each subtitle segment. This output can be easily converted to SRT or VTT subtitle formats. Inputs audio_path**: The path to the audio file to be transcribed model_name**: The name of the Whisper model to use, such as tiny, base, small, medium, or large format**: The subtitle format to generate, either srt or vtt Outputs text**: The transcribed text segments**: A list of dictionaries, each containing the start and end times (in seconds) and the transcribed text for a subtitle segment Capabilities The whisper-subtitles model inherits the powerful speech recognition capabilities of the original Whisper model, including support for multilingual speech, language identification, and speech translation. By generating subtitles in standardized formats like SRT and VTT, this model makes it easier to incorporate high-quality transcriptions into video and audio content. What can I use it for? The whisper-subtitles model can be useful for a variety of applications that require generating subtitles or captions for audio and video content. This could include: Automatically adding subtitles to YouTube videos, podcasts, or other multimedia content Improving accessibility by providing captions for hearing-impaired viewers Enabling multilingual content by generating subtitles in different languages Streamlining the video production process by automating the subtitle generation task Things to try One interesting aspect of the whisper-subtitles model is its ability to handle a wide range of audio file formats and quality levels. Try experimenting with different types of audio, such as low-quality recordings, noisy environments, or accented speech, to see how the model performs. You can also compare the output of the various Whisper model sizes to find the best balance of accuracy and speed for your specific use case.
Updated 7/4/2024

emoji-diffusion
2
emoji-diffusion is a Stable Diffusion-based model that allows generating emojis using text prompts. It was created by m1guelpf and is available as a Cog container through Replicate. The model is based on Valhalla's Emoji Diffusion and allows users to create custom emojis by providing a text prompt. This model can be particularly useful for those looking to generate unique emoji-style images for various applications, such as personalized emojis, social media content, or digital art projects. Model inputs and outputs The emoji-diffusion model takes in several inputs to generate the desired emoji images. These include the text prompt, the number of outputs, the image size, as well as optional parameters like a seed value and a guidance scale. The model then outputs one or more images in the specified resolution, which can be used as custom emojis or for other purposes. Inputs Prompt**: The text prompt that describes the emoji you want to generate. The prompt should include the word "emoji" for best results. Num Outputs**: The number of images to generate, up to a maximum of 10. Width/Height**: The desired size of the output images, up to a maximum of 1024x768 or 768x1024. Seed**: An optional integer value to set the random seed and ensure reproducible results. Guidance Scale**: A parameter that controls the strength of the text guidance during the image generation process. Negative Prompt**: An optional prompt to exclude certain elements from the generated image. Prompt Strength**: A parameter that controls the balance between the initial image and the text prompt when using an initial image as input. Outputs The model outputs one or more images in the specified resolution, which can be used as custom emojis or for other purposes. Capabilities emoji-diffusion can generate a wide variety of emojis based on the provided text prompt. The model is capable of creating emojis that depict various objects, animals, activities, and more. By leveraging the power of Stable Diffusion, the model is able to generate highly realistic and visually appealing emoji-style images. What can I use it for? The emoji-diffusion model can be used for a variety of applications, such as: Personalized Emojis**: Generate custom emojis that reflect your personality, interests, or local culture. Social Media Content**: Create unique emoji-based images to use as part of your social media posts, stories, or profiles. Digital Art and Design**: Incorporate the generated emojis into your digital art projects, designs, or illustrations. Educational Resources**: Use the model to create custom educational materials or interactive learning tools that incorporate emojis. Things to try One interesting thing to try with emoji-diffusion is to experiment with different prompts that combine the word "emoji" with more specific descriptions or concepts. For example, you could try prompts like "a happy emoji with a party hat" or "a spooky emoji for Halloween." This can help you explore the model's ability to generate a wide range of unique and expressive emojis.
Updated 7/4/2024

ghibli-diffusion
1
The ghibli-diffusion model is a fine-tuned Stable Diffusion model trained on images from modern anime feature films from Studio Ghibli. This model can be used to generate images in the distinct visual style of Studio Ghibli, known for its lush environments, whimsical characters, and dreamlike aesthetics. Similar models include the studio-ghibli model, which is also trained on Ghibli-style artwork, as well as the more general stable-diffusion and eimis_anime_diffusion models. Model inputs and outputs The ghibli-diffusion model takes in a text prompt and generates an image based on that prompt. The model can also take in an initial image and use that as a starting point for the generation process. The outputs are high-quality, photo-realistic images that capture the distinct visual style of Studio Ghibli. Inputs Prompt**: A text prompt describing the image you want to generate Mask**: A black and white image to use as a mask for inpainting over an initial image Seed**: A random seed value to use for image generation Width/Height**: The desired dimensions of the output image, up to 1024x768 or 768x1024 Scheduler**: The scheduler algorithm to use for image generation, such as K-LMS or PNDM Init Image**: An initial image to use as a starting point for generating variations Num Outputs**: The number of images to generate (up to 10) Guidance Scale**: The scale for classifier-free guidance, controlling the balance between the text prompt and the initial image Prompt Strength**: The strength of the text prompt when using an initial image Num Inference Steps**: The number of denoising steps to perform during image generation Outputs Output Images**: An array of generated images, with each image returned as a URI Capabilities The ghibli-diffusion model can generate a wide variety of images in the distinct Studio Ghibli style, including characters, vehicles, animals, and landscapes. The model is particularly adept at capturing the whimsical and dreamlike qualities that characterize Ghibli's visual aesthetic. What can I use it for? The ghibli-diffusion model can be used for a variety of creative and commercial applications, such as: Generating concept art or illustrations for Ghibli-inspired animation, films, or games Creating unique and visually striking social media content or marketing materials Exploring and experimenting with the Ghibli visual style for personal creative projects The model's maintainer also encourages users to support their work through Patreon, which can help fund the development of new and improved AI models. Things to try When using the ghibli-diffusion model, try experimenting with different combinations of prompts, settings, and initial images to see the wide range of outputs the model can produce. For example, you could try generating a "ghibli style magical princess with golden hair" or a "ghibli style ice field with northern lights." The model's unique ability to capture the essence of Ghibli's visual style can lead to truly captivating and imaginative results.
Updated 7/4/2024