anydoor
Maintainer: ali-vilab

1

| Property | Value |
|---|---|
| Run this model | Run on Replicate |
| API spec | View on Replicate |
| Github link | View on Github |
| Paper link | View on Arxiv |
Create account to get full access
Model overview
anydoor is a zero-shot object-level image customization model developed by ali-vilab. It allows for fine-grained control and manipulation of specific objects within an image, a capability that sets it apart from similar models like i2vgen-xl, gfpgan, instant-id-artistic, and real-esrgan.
Model inputs and outputs
anydoor takes in a source image, a target image, and various control parameters to customize the target image. The model can manipulate the target image's background, foreground, and even the shape of objects within it.
Inputs
- Reference Image Path: The source image to be used as reference
- Reference Image Mask: The mask for the source image
- Bg Image Path: The target image to be customized
- Bg Mask Path: The mask for the target image
- Control Strength: The strength of the control over the target image
- Guidance Scale: The strength of the guidance towards the target image
- Enable Shape Control: A boolean to enable shape control of objects in the target image
- Steps: The number of steps to run the model
Outputs
- Output: The customized target image
Capabilities
anydoor can perform zero-shot object-level image customization, allowing users to fine-tune specific elements of an image without the need for extensive training or labeling. This makes it a powerful tool for tasks such as object removal, background replacement, and targeted modifications to elements within an image.
What can I use it for?
anydoor can be used in a variety of applications, such as content creation, image editing, and visual effects. Its ability to precisely control and modify objects within an image makes it particularly useful for tasks like product photography, character design, and visual storytelling. Additionally, the model's flexibility and zero-shot capabilities make it a valuable tool for researchers and developers working on image manipulation and generation projects.
Things to try
One interesting thing to try with anydoor is using it to create seamless composites by blending multiple images together. By leveraging the model's object-level control and guidance features, users can combine elements from different sources to create completely new and visually compelling images. Another intriguing use case is exploring the model's ability to generate creative and surreal imagery by pushing the boundaries of its shape control and guidance capabilities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Models

sdxl-lightning-4step
412.2K
sdxl-lightning-4step is a fast text-to-image model developed by ByteDance that can generate high-quality images in just 4 steps. It is similar to other fast diffusion models like AnimateDiff-Lightning and Instant-ID MultiControlNet, which also aim to speed up the image generation process. Unlike the original Stable Diffusion model, these fast models sacrifice some flexibility and control to achieve faster generation times. Model inputs and outputs The sdxl-lightning-4step model takes in a text prompt and various parameters to control the output image, such as the width, height, number of images, and guidance scale. The model can output up to 4 images at a time, with a recommended image size of 1024x1024 or 1280x1280 pixels. Inputs Prompt**: The text prompt describing the desired image Negative prompt**: A prompt that describes what the model should not generate Width**: The width of the output image Height**: The height of the output image Num outputs**: The number of images to generate (up to 4) Scheduler**: The algorithm used to sample the latent space Guidance scale**: The scale for classifier-free guidance, which controls the trade-off between fidelity to the prompt and sample diversity Num inference steps**: The number of denoising steps, with 4 recommended for best results Seed**: A random seed to control the output image Outputs Image(s)**: One or more images generated based on the input prompt and parameters Capabilities The sdxl-lightning-4step model is capable of generating a wide variety of images based on text prompts, from realistic scenes to imaginative and creative compositions. The model's 4-step generation process allows it to produce high-quality results quickly, making it suitable for applications that require fast image generation. What can I use it for? The sdxl-lightning-4step model could be useful for applications that need to generate images in real-time, such as video game asset generation, interactive storytelling, or augmented reality experiences. Businesses could also use the model to quickly generate product visualization, marketing imagery, or custom artwork based on client prompts. Creatives may find the model helpful for ideation, concept development, or rapid prototyping. Things to try One interesting thing to try with the sdxl-lightning-4step model is to experiment with the guidance scale parameter. By adjusting the guidance scale, you can control the balance between fidelity to the prompt and diversity of the output. Lower guidance scales may result in more unexpected and imaginative images, while higher scales will produce outputs that are closer to the specified prompt.
Updated Invalid Date

zero-shot-image-to-text
6
The zero-shot-image-to-text model is a cutting-edge AI model designed for the task of generating text descriptions from input images. Developed by researcher yoadtew, this model leverages a unique "zero-shot" approach to enable image-to-text generation without the need for task-specific fine-tuning. This sets it apart from similar models like stable-diffusion, uform-gen, and turbo-enigma which often require extensive fine-tuning for specific image-to-text tasks. Model inputs and outputs The zero-shot-image-to-text model takes in an image and produces a text description of that image. The model can handle a wide range of image types and subjects, from natural scenes to abstract concepts. Additionally, the model supports "visual-semantic arithmetic" - the ability to perform arithmetic operations on visual concepts to generate new images. Inputs Image**: The input image to be described Outputs Text Description**: A textual description of the input image Capabilities The zero-shot-image-to-text model has demonstrated impressive capabilities in generating detailed and coherent image descriptions across a diverse set of visual inputs. It can handle not only common objects and scenes, but also more complex visual reasoning tasks like understanding visual relationships and analogies. What can I use it for? The zero-shot-image-to-text model can be a valuable tool for a variety of applications, such as: Automated Image Captioning**: Generating descriptive captions for large image datasets, which can be useful for tasks like visual search, content moderation, and accessibility. Visual Question Answering**: Answering questions about the contents of an image, which can be helpful for building intelligent assistants or educational applications. Visual-Semantic Arithmetic**: Exploring and manipulating visual concepts in novel ways, which can inspire new creative applications or research directions. Things to try One interesting aspect of the zero-shot-image-to-text model is its ability to handle "visual-semantic arithmetic" - the ability to combine visual concepts in arithmetic-like operations to generate new, semantically meaningful images. For example, the model can take in images of a "woman", a "king", and a "man", and then generate a new image that represents the visual concept of "woman - king + man". This opens up fascinating possibilities for exploring the relationships between visual and semantic representations.
Updated Invalid Date
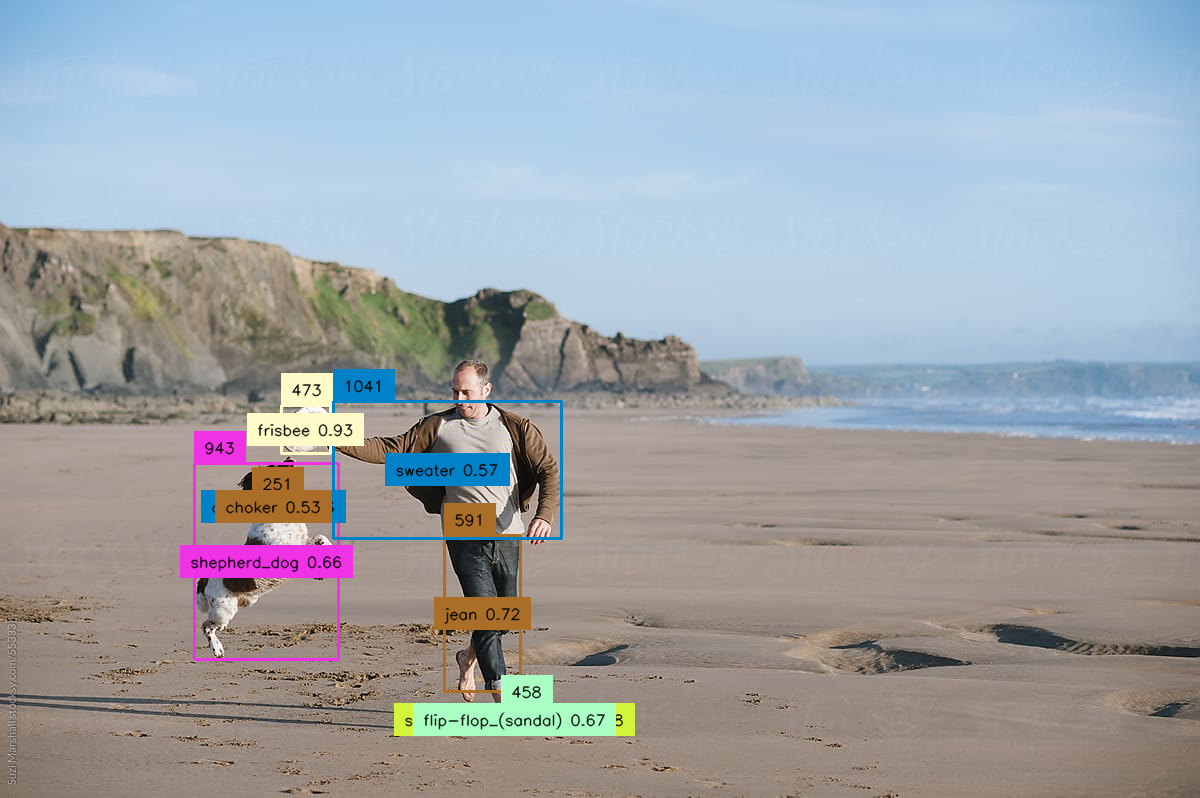
codet
1
The codet model is an object detection AI model developed by Replicate and maintained by the creator adirik. It is designed to detect objects in images with high accuracy. The codet model shares similarities with other object detection models like Marigold, which focuses on monocular depth estimation, and StyleMC, MaSaCtrl-Anything-v4-0, and MaSaCtrl-Stable-Diffusion-v1-4, which are focused on text-guided image generation and editing. Model inputs and outputs The codet model takes an input image and a confidence threshold, and outputs an array of image URIs. The input image is used for object detection, and the confidence threshold is used to filter the detected objects based on their confidence scores. Inputs Image**: The input image to be processed for object detection. Confidence**: The confidence threshold to filter the detected objects. Show Visualisation**: An optional flag to display the detection results on the input image. Outputs Array of Image URIs**: The output of the model is an array of image URIs, where each URI represents a detected object in the input image. Capabilities The codet model is capable of detecting objects in images with high accuracy. It uses a novel approach called "Co-Occurrence Guided Region-Word Alignment" to improve the model's performance on open-vocabulary object detection tasks. What can I use it for? The codet model can be useful in a variety of applications, such as: Image analysis and understanding**: The model can be used to analyze and understand the contents of images, which can be valuable in fields like e-commerce, security, and robotics. Visual search and retrieval**: The model can be used to build visual search engines or image retrieval systems, where users can search for specific objects within a large collection of images. Augmented reality and computer vision**: The model can be integrated into AR/VR applications or computer vision systems to provide real-time object detection and identification. Things to try Some ideas for things to try with the codet model include: Experiment with different confidence thresholds to see how it affects the accuracy and number of detected objects. Use the model to analyze a variety of images and see how it performs on different types of objects. Integrate the model into a larger system, such as an image-processing pipeline or a computer vision application.
Updated Invalid Date

owlvit-base-patch32
14
The owlvit-base-patch32 model is a zero-shot/open vocabulary object detection model developed by alaradirik. It shares similarities with other AI models like text-extract-ocr, which is a simple OCR model for extracting text from images, and codet, which detects objects in images. However, the owlvit-base-patch32 model goes beyond basic object detection, enabling zero-shot detection of objects based on natural language queries. Model inputs and outputs The owlvit-base-patch32 model takes three inputs: an image, a comma-separated list of object names to detect, and a confidence threshold. It outputs the detected objects with bounding boxes and confidence scores. Inputs image**: The input image to query query**: Comma-separated names of the objects to be detected in the image threshold**: Confidence level for object detection (between 0 and 1) show_visualisation**: Whether to draw and visualize bounding boxes on the image Outputs The detected objects with bounding boxes and confidence scores Capabilities The owlvit-base-patch32 model is capable of zero-shot object detection, meaning it can identify objects in an image based on natural language descriptions, without being explicitly trained on those objects. This makes it a powerful tool for open-vocabulary object detection, where you can query the model for a wide range of objects beyond its training set. What can I use it for? The owlvit-base-patch32 model can be used in a variety of applications that require object detection, such as image analysis, content moderation, and robotic vision. For example, you could use it to build a visual search engine that allows users to find images based on natural language queries, or to develop a system for automatically tagging objects in photos. Things to try One interesting aspect of the owlvit-base-patch32 model is its ability to detect objects in context. For example, you could try querying the model for "dog" and see if it correctly identifies dogs in the image, even if they are surrounded by other objects. Additionally, you could experiment with using more complex queries, such as "small red car" or "person playing soccer", to see how the model handles more specific or compositional object descriptions.
Updated Invalid Date