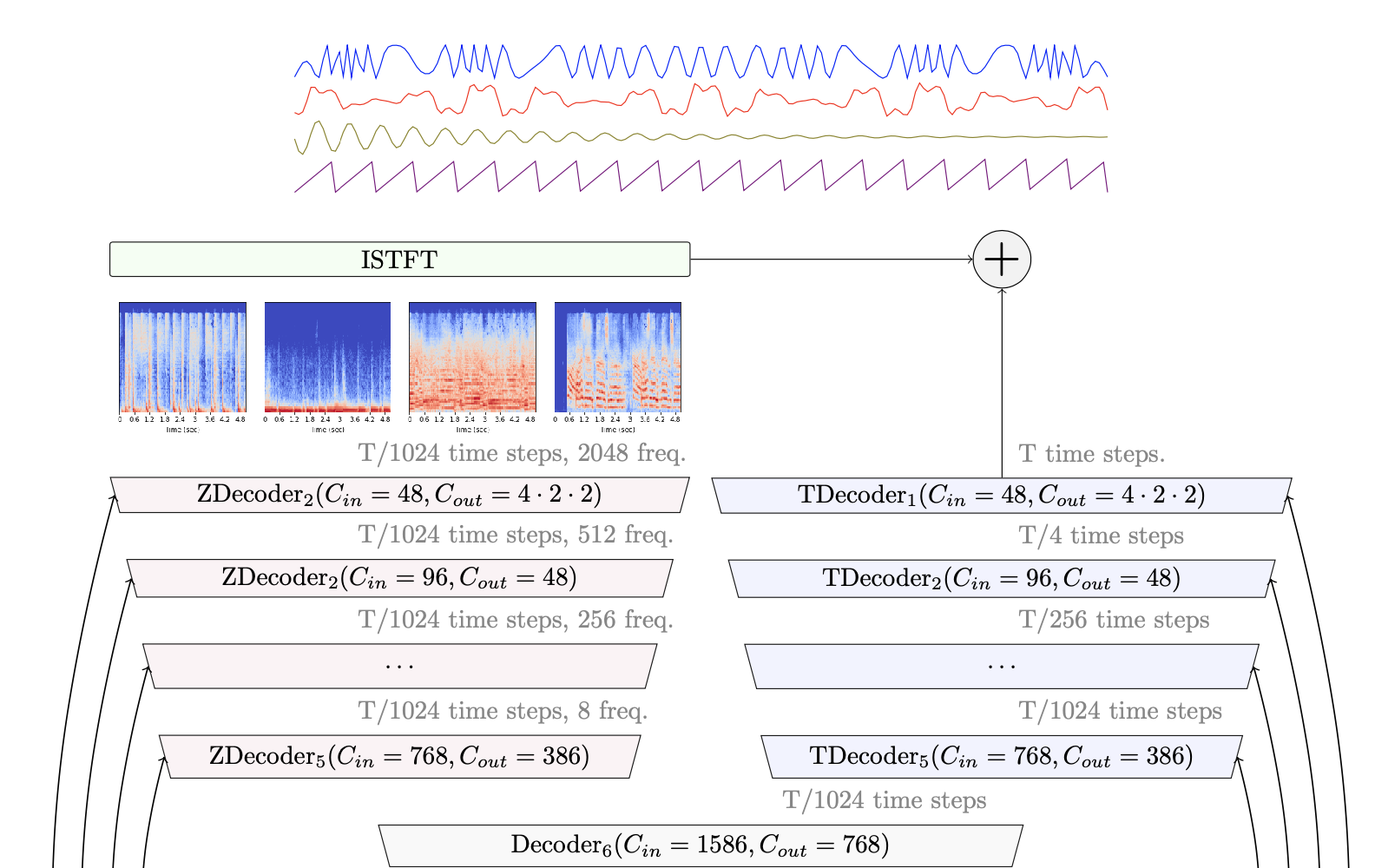
demucs
Maintainer: ryan5453

344
| Property | Value |
|---|---|
| Run this model | Run on Replicate |
| API spec | View on Replicate |
| Github link | View on Github |
| Paper link | View on Arxiv |
Create account to get full access
Model overview
Demucs is an audio source separator created by Facebook Research. It is a powerful AI model capable of separating audio into its individual components, such as vocals, drums, and instruments. Demucs can be compared to other similar models like Demucs Music Source Separation, Zero shot Sound separation by arbitrary query samples, and Separate Anything You Describe. These models all aim to extract individual audio sources from a mixed recording, allowing users to isolate and manipulate specific elements.
Model inputs and outputs
The Demucs model takes in an audio file and allows the user to customize various parameters, such as the number of parallel jobs, the stem to isolate, the specific Demucs model to use, and options related to splitting the audio, shifting, overlapping, and clipping. The model then outputs the processed audio in the user's chosen format, whether that's MP3, WAV, or another option.
Inputs
- Audio: The file to be processed
- Model: The specific Demucs model to use for separation
- Stem: The audio stem to isolate (e.g., vocals, drums, bass)
- Jobs: The number of parallel jobs to use for separation
- Split: Whether to split the audio into chunks
- Shifts: The number of random shifts for equivariant stabilization
- Overlap: The amount of overlap between prediction windows
- Segment: The segment length to use for separation
- Clip mode: The strategy for avoiding clipping
- MP3 preset: The preset for the MP3 output
- WAV format: The format for the WAV output
- MP3 bitrate: The bitrate for the MP3 output
Outputs
- The processed audio file in the user's chosen format
Capabilities
Demucs is capable of separating audio into its individual components with high accuracy. This can be useful for a variety of applications, such as music production, sound design, and audio restoration. By isolating specific elements of a mixed recording, users can more easily manipulate and enhance the audio to achieve their desired effects.
What can I use it for?
The Demucs model can be used in a wide range of projects, from music production and audio editing to sound design and post-production. For example, a musician could use Demucs to isolate the vocals from a recorded song, allowing them to adjust the volume or apply effects without affecting the other instruments. Similarly, a sound designer could use Demucs to extract specific sound elements from a complex audio file, such as the footsteps or ambiance, for use in a video game or film.
Things to try
One interesting thing to try with Demucs is experimenting with the different model options, such as the number of shifts and the overlap between prediction windows. Adjusting these parameters can have a significant impact on the separation quality and processing time, allowing users to find the optimal balance for their specific needs. Additionally, users could try combining Demucs with other audio processing tools, such as EQ or reverb, to further enhance the separated audio elements.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Models

demucs
130
demucs is a state-of-the-art music source separation model developed by researchers at Facebook AI Research. It is capable of separating drums, bass, vocals, and other accompaniment from audio tracks. The latest version, Hybrid Transformer Demucs (v4), uses a hybrid spectrogram and waveform architecture with a Transformer encoder-decoder to achieve high-quality separation performance. This builds on the previous Hybrid Demucs (v3) model, which won the Sony MDX challenge. demucs is similar to other advanced source separation models like Wave-U-Net, Open-Unmix, and D3Net, but achieves state-of-the-art results on standard benchmarks. Model inputs and outputs demucs takes as input an audio file in a variety of formats including WAV, MP3, FLAC, and more. It outputs the separated audio stems for drums, bass, vocals, and other accompaniment as individual stereo WAV or MP3 files. Users can also choose to output just the vocals or other specific stems. Inputs audio**: The input audio file to be separated stem**: The specific stem to separate (e.g. vocals, drums, bass) or "no_stem" to separate all stems model_name**: The pre-trained model to use for separation, such as htdemucs, htdemucs_ft, or mdx_extra shifts**: The number of random shifts to use for equivariant stabilization, which improves quality but increases inference time overlap**: The amount of overlap between prediction windows clip_mode**: The strategy for avoiding clipping in the output, either "rescale" or "clamp" float32**: Whether to output the audio as 32-bit float instead of 16-bit integer mp3_bitrate**: The bitrate to use when outputting the audio as MP3 Outputs drums.wav**: The separated drums stem bass.wav**: The separated bass stem vocals.wav**: The separated vocals stem other.wav**: The separated other/accompaniment stem Capabilities demucs is a highly capable music source separation model that can extract individual instrument and vocal tracks from complex audio mixes with high accuracy. It outperforms many previous state-of-the-art models on standard benchmarks like the MUSDB18 dataset. The latest Hybrid Transformer Demucs (v4) model achieves 9.0 dB SDR, which is a significant improvement over earlier versions and other leading approaches. What can I use it for? demucs can be used for a variety of music production and audio engineering tasks. It enables users to isolate individual elements of a song, which is useful for tasks like: Karaoke or music removal - Extracting just the vocals to create a karaoke track Remixing or mash-ups - Separating the drums, bass, and other elements to remix a song Audio post-production - Cleaning up or enhancing specific elements of a mix Music education - Isolating instrument tracks for practicing or study Music information retrieval - Analyzing the individual components of a song The model's state-of-the-art performance and flexible interface make it a powerful tool for both professionals and hobbyists working with audio. Things to try Some interesting things to try with demucs include: Experimenting with the different pre-trained models to find the best fit for your audio Trying the "two-stems" mode to extract just the vocals or other specific element Utilizing the "shifts" option to improve separation quality, especially for complex mixes Applying the model to a diverse range of musical genres and styles to see how it performs The maintainer, cjwbw, has also released several other impressive audio models like audiosep, video-retalking, and voicecraft that may be of interest to explore further.
Updated Invalid Date

all-in-one-audio
4
The all-in-one-audio model is an AI-powered music analysis and stem separation tool created by erickluis00. It combines the capabilities of the Demucs and MDX-Net models to provide a comprehensive audio processing solution. The model can analyze music structure, separate audio into individual stems (such as vocals, drums, and bass), and generate sonifications and visualizations of the audio data. It is similar to other audio separation models like demucs and spleeter, but offers a more all-in-one approach. Model inputs and outputs The all-in-one-audio model takes a music input file and several optional parameters to control the analysis and separation process. The outputs include the separated audio stems, as well as sonifications and visualizations of the audio data. Inputs music_input**: An audio file to be analyzed and processed. sonify**: A boolean flag to save sonifications of the analysis results. visualize**: A boolean flag to save visualizations of the analysis results. audioSeparator**: A boolean flag to enable audio separation using the MDX-net model. include_embeddings**: A boolean flag to include audio embeddings in the analysis results. include_activations**: A boolean flag to include activations in the analysis results. audioSeparatorModel**: The name of the pre-trained model to use for audio separation. Outputs mdx_other**: An array of URIs for the separated "other" stems (such as instruments) using the MDX-net model. mdx_vocals**: A URI for the separated vocal stem using the MDX-net model. demucs_bass**: A URI for the separated bass stem using the Demucs model. demucs_drums**: A URI for the separated drum stem using the Demucs model. demucs_other**: A URI for the separated "other" stem using the Demucs model. demucs_piano**: A URI for the separated piano stem using the Demucs model. sonification**: A URI for the generated sonification of the analysis results. demucs_guitar**: A URI for the separated guitar stem using the Demucs model. demucs_vocals**: A URI for the separated vocal stem using the Demucs model. visualization**: A URI for the generated visualization of the analysis results. analyzer_result**: A URI for the overall analysis results. mdx_instrumental**: A URI for the separated instrumental stem using the MDX-net model. Capabilities The all-in-one-audio model can analyze the structure of music and separate the audio into individual stems, such as vocals, drums, and instruments. It uses the Demucs and MDX-Net models to achieve this, combining their strengths to provide a comprehensive audio processing solution. What can I use it for? The all-in-one-audio model can be used for a variety of music-related applications, such as audio editing, music production, and music analysis. It can be particularly useful for producers, musicians, and researchers who need to work with individual audio stems or analyze the structure of music. For example, you could use the model to separate the vocals from a song, create remixes or mashups, or study the relationships between different musical elements. Things to try Some interesting things to try with the all-in-one-audio model include: Experimenting with the different audio separation models (Demucs and MDX-Net) to see which one works best for your specific use case. Generating sonifications and visualizations of the audio data to gain new insights into the music. Combining the separated audio stems in creative ways to produce new musical compositions. Analyzing the structure of music to better understand the relationships between different musical elements.
Updated Invalid Date
audiosep
2
audiosep is a foundation model for open-domain sound separation with natural language queries, developed by cjwbw. It demonstrates strong separation performance and impressive zero-shot generalization ability on numerous tasks such as audio event separation, musical instrument separation, and speech enhancement. audiosep can be compared to similar models like video-retalking, openvoice, voicecraft, whisper-diarization, and depth-anything from the same maintainer, which also focus on audio and video processing tasks. Model inputs and outputs audiosep takes an audio file and a textual description as inputs, and outputs the separated audio based on the provided description. The model processes audio at a 32 kHz sampling rate. Inputs Audio File**: The input audio file to be separated. Text**: The textual description of the audio content to be separated. Outputs Separated Audio**: The output audio file with the requested components separated. Capabilities audiosep can separate a wide range of audio content, from musical instruments to speech and environmental sounds, based on natural language descriptions. It demonstrates impressive zero-shot generalization, allowing users to separate audio in novel ways beyond the training data. What can I use it for? You can use audiosep for a variety of audio processing tasks, such as music production, audio editing, speech enhancement, and audio analytics. The model's ability to separate audio based on natural language descriptions allows for highly customizable and flexible audio manipulation. For example, you could use audiosep to isolate specific instruments in a music recording, remove background noise from a speech recording, or extract environmental sounds from a complex audio scene. Things to try Try using audiosep to separate audio in novel ways, such as isolating a specific sound effect from a movie soundtrack, extracting individual vocals from a choir recording, or separating a specific bird call from a nature recording. The model's flexibility and zero-shot capabilities allow for a wide range of creative and practical applications.
Updated Invalid Date
🏅
zero_shot_audio_source_separation
39
The zero_shot_audio_source_separation model, developed by maintainer retrocirce, is a powerful AI-based tool that can separate any specified audio source from a given audio mix, without requiring the separation dataset. Instead, the model is trained on the large-scale AudioSet dataset, allowing it to generalize to a wide range of audio sources. This approach contrasts with models like spleeter, which rely on supervised training on specific source separation datasets. Model inputs and outputs The zero_shot_audio_source_separation model takes two inputs: a "mix file" containing the audio mixture to be separated, and a "query file" that specifies the audio source to be extracted. The model then outputs the separated audio source, allowing users to isolate specific elements from complex audio tracks. Inputs mix_file**: The reference audio mixture from which the source should be extracted. query_file**: The audio sample that specifies the source to be separated from the mixture. Outputs Output**: The separated audio source, extracted from the input mix file based on the provided query file. Capabilities The zero_shot_audio_source_separation model can separate a wide range of audio sources, from musical instruments like violin and guitar to vocal elements and sound effects. This flexibility is enabled by the model's ability to learn from the diverse AudioSet dataset, rather than being constrained to a specific set of sources. The model's strong performance on the MUSDB18 dataset, a popular benchmark for source separation, further demonstrates its capabilities. What can I use it for? The zero_shot_audio_source_separation model can be useful for a variety of audio-related tasks, such as music production, post-processing, and sound design. By allowing users to isolate specific elements from a complex audio mix, the model can simplify tasks like vocal removal, instrument extraction, and sound effect layering. This can be particularly valuable for content creators, audio engineers, and musicians who need to manipulate and remix audio files. Things to try One interesting aspect of the zero_shot_audio_source_separation model is its ability to separate sources that are not part of the training dataset. This means you can try using it to isolate a wide range of audio elements, from unique sound effects to obscure musical instruments. Additionally, you can experiment with different query files to see how the model responds, potentially uncovering unexpected capabilities or creative applications.
Updated Invalid Date