A 65nm 36nJ/Decision Bio-inspired Temporal-Sparsity-Aware Digital Keyword Spotting IC with 0.6V Near-Threshold SRAM
2405.03905
0
0
Abstract
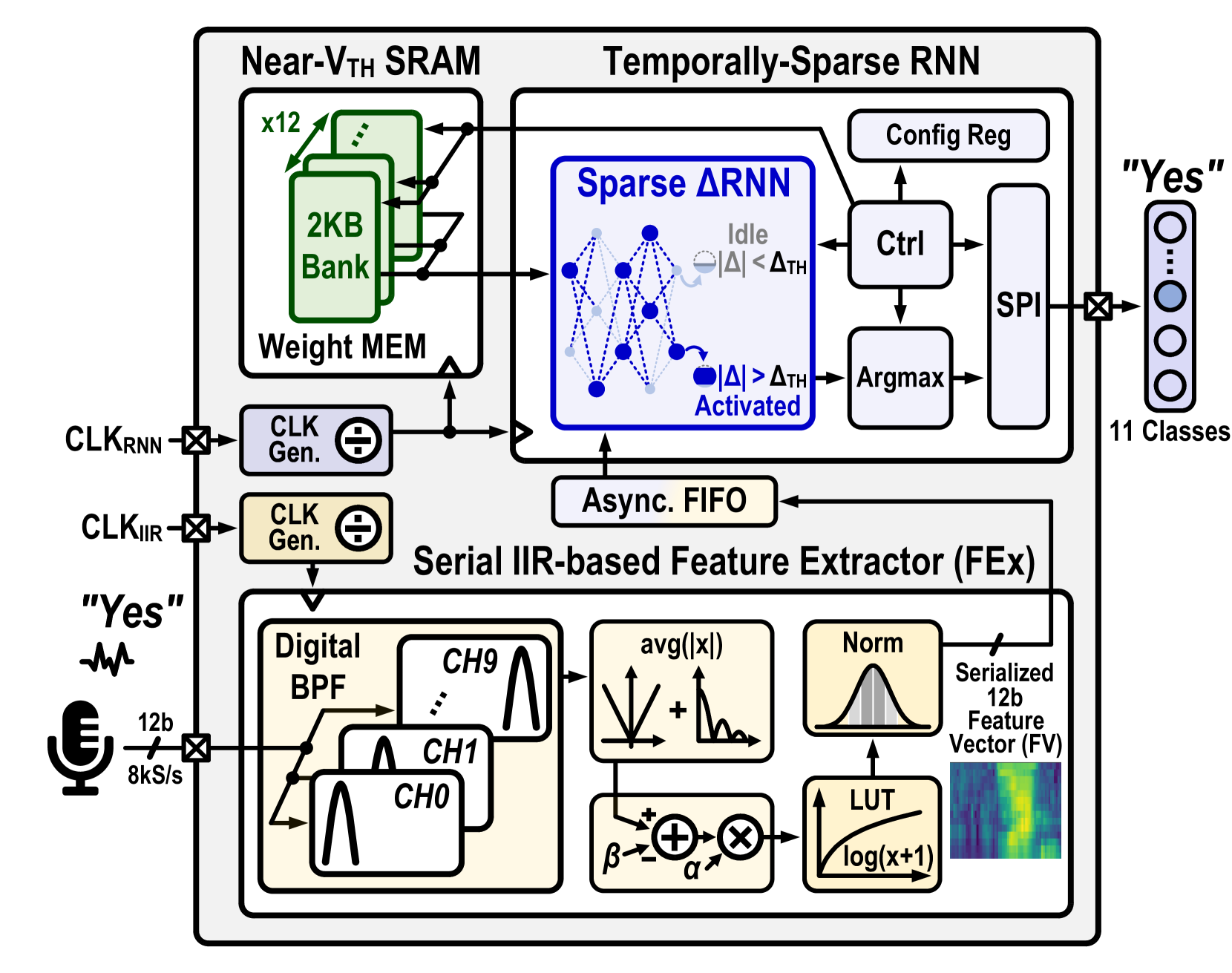
This paper introduces, to the best of the authors' knowledge, the first fine-grained temporal sparsity-aware keyword spotting (KWS) IC leveraging temporal similarities between neighboring feature vectors extracted from input frames and network hidden states, eliminating unnecessary operations and memory accesses. This KWS IC, featuring a bio-inspired delta-gated recurrent neural network ({Delta}RNN) classifier, achieves an 11-class Google Speech Command Dataset (GSCD) KWS accuracy of 90.5% and energy consumption of 36nJ/decision. At 87% temporal sparsity, computing latency and energy per inference are reduced by 2.4$times$/3.4$times$, respectively. The 65nm design occupies 0.78mm$^2$ and features two additional blocks, a compact 0.084mm$^2$ digital infinite-impulse-response (IIR)-based band-pass filter (BPF) audio feature extractor (FEx) and a 24kB 0.6V near-Vth weight SRAM with 6.6$times$ lower read power compared to the standard SRAM.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper presents a 65nm bio-inspired digital keyword spotting integrated circuit (IC) that achieves high energy efficiency.
- The IC leverages temporal sparsity and near-threshold SRAM to reduce power consumption.
- Key features include a 36nJ/decision energy efficiency, 0.6V near-threshold SRAM, and bio-inspired temporal-sparsity-aware design.
Plain English Explanation
This research describes the development of a specialized computer chip that can efficiently detect spoken keywords. The chip is designed to be energy-efficient, using techniques inspired by how the human brain processes information.
One key innovation is the use of "temporal sparsity", which means the chip only performs computations when necessary, rather than running continuously. This helps reduce the overall power consumption. The chip also operates at a low voltage (0.6V) near the minimum threshold required for the transistors to function, further improving efficiency.
The researchers claim this chip can detect keywords using only 36 nanojoules (nJ) of energy per decision, which is very low. This makes it well-suited for applications like voice-controlled devices that need to run on battery power. By taking inspiration from how the brain works, the researchers were able to create a highly efficient speech recognition system in a small, low-power chip.
Technical Explanation
The researchers developed a 65nm bio-inspired digital keyword spotting IC that achieves 36nJ/decision energy efficiency by leveraging temporal sparsity and a 0.6V near-threshold SRAM.
The system uses a bio-inspired neural network architecture that only performs computations when necessary, rather than running continuously. This temporal sparsity reduces overall power consumption. The chip also operates at a low supply voltage (0.6V) near the minimum threshold required for the transistors to function, further improving energy efficiency.
Experiments show the proposed IC can detect keywords with 36nJ/decision, a significant improvement over prior work. The researchers attribute this efficiency to the combination of temporal sparsity and near-threshold operation.
Critical Analysis
The paper provides a compelling demonstration of how bio-inspired design principles can lead to highly energy-efficient hardware for speech recognition. The use of temporal sparsity and near-threshold SRAM are novel techniques that appear to offer substantial benefits in terms of power consumption.
However, the paper does not discuss potential limitations or areas for further research. For example, it's unclear how the system would perform on more complex speech recognition tasks beyond simple keyword spotting. There may also be challenges in scaling the approach to larger neural network models or deploying it in real-world noisy environments.
Additionally, the researchers do not compare their system to other recent advances in efficient speech recognition, such as quantized neural networks or specialized hardware accelerators. Further benchmarking against state-of-the-art techniques would help contextualize the significance of the proposed IC.
Conclusion
This paper presents an innovative 65nm bio-inspired digital keyword spotting IC that achieves impressive energy efficiency of 36nJ/decision. By leveraging temporal sparsity and near-threshold SRAM operation, the researchers were able to create a highly power-efficient speech recognition system suitable for battery-powered applications.
While the paper demonstrates the potential of bio-inspired design principles, further research is needed to understand the broader applicability and limitations of this approach. Comparing the system to other recent advancements in efficient speech recognition would also help solidify the contribution of this work to the field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛸
Multi-Sample Dynamic Time Warping for Few-Shot Keyword Spotting
Kevin Wilkinghoff, Alessia Cornaggia-Urrigshardt
0
0
In multi-sample keyword spotting, each keyword class is represented by multiple spoken instances, called samples. A naive approach to detect keywords in a target sequence consists of querying all samples of all classes using sub-sequence dynamic time warping. However, the resulting processing time increases linearly with respect to the number of samples belonging to each class. Alternatively, only a single Fr'echet mean can be queried for each class, resulting in reduced processing time but usually also in worse detection performance as the variability of the query samples is not captured sufficiently well. In this work, multi-sample dynamic time warping is proposed to compute class-specific cost-tensors that include the variability of all query samples. To significantly reduce the computational complexity during inference, these cost tensors are converted to cost matrices before applying dynamic time warping. In experimental evaluations for few-shot keyword spotting, it is shown that this method yields a very similar performance as using all individual query samples as templates while having a runtime that is only slightly slower than when using Fr'echet means.
4/24/2024
🌐
A 65nm 8b-Activation 8b-Weight SRAM-Based Charge-Domain Computing-in-Memory Macro Using A Fully-Parallel Analog Adder Network and A Single-ADC Interface
Guodong Yin, Mufeng Zhou, Yiming Chen, Wenjun Tang, Zekun Yang, Mingyen Lee, Xirui Du, Jinshan Yue, Jiaxin Liu, Huazhong Yang, Yongpan Liu, Xueqing Li
0
0
Performing data-intensive tasks in the von Neumann architecture is challenging to achieve both high performance and power efficiency due to the memory wall bottleneck. Computing-in-memory (CiM) is a promising mitigation approach by enabling parallel in-situ multiply-accumulate (MAC) operations within the memory with support from the peripheral interface and datapath. SRAM-based charge-domain CiM (CD-CiM) has shown its potential of enhanced power efficiency and computing accuracy. However, existing SRAM-based CD-CiM faces scaling challenges to meet the throughput requirement of high-performance multi-bit-quantization applications. This paper presents an SRAM-based high-throughput ReLU-optimized CD-CiM macro. It is capable of completing MAC and ReLU of two signed 8b vectors in one CiM cycle with only one A/D conversion. Along with non-linearity compensation for the analog computing and A/D conversion interfaces, this work achieves 51.2GOPS throughput and 10.3TOPS/W energy efficiency, while showing 88.6% accuracy in the CIFAR-10 dataset.
4/3/2024
🧠
Quantized Context Based LIF Neurons for Recurrent Spiking Neural Networks in 45nm
Sai Sukruth Bezugam, Yihao Wu, JaeBum Yoo, Dmitri Strukov, Bongjin Kim
0
0
In this study, we propose the first hardware implementation of a context-based recurrent spiking neural network (RSNN) emphasizing on integrating dual information streams within the neocortical pyramidal neurons specifically Context- Dependent Leaky Integrate and Fire (CLIF) neuron models, essential element in RSNN. We present a quantized version of the CLIF neuron (qCLIF), developed through a hardware-software codesign approach utilizing the sparse activity of RSNN. Implemented in a 45nm technology node, the qCLIF is compact (900um^2) and achieves a high accuracy of 90% despite 8 bit quantization on DVS gesture classification dataset. Our analysis spans a network configuration from 10 to 200 qCLIF neurons, supporting up to 82k synapses within a 1.86 mm^2 footprint, demonstrating scalability and efficiency
4/30/2024

LitE-SNN: Designing Lightweight and Efficient Spiking Neural Network through Spatial-Temporal Compressive Network Search and Joint Optimization
Qianhui Liu, Jiaqi Yan, Malu Zhang, Gang Pan, Haizhou Li
0
0
Spiking Neural Networks (SNNs) mimic the information-processing mechanisms of the human brain and are highly energy-efficient, making them well-suited for low-power edge devices. However, the pursuit of accuracy in current studies leads to large, long-timestep SNNs, conflicting with the resource constraints of these devices. In order to design lightweight and efficient SNNs, we propose a new approach named LitE-SNN that incorporates both spatial and temporal compression into the automated network design process. Spatially, we present a novel Compressive Convolution block (CompConv) to expand the search space to support pruning and mixed-precision quantization. Temporally, we are the first to propose a compressive timestep search to identify the optimal number of timesteps under specific computation cost constraints. Finally, we formulate a joint optimization to simultaneously learn the architecture parameters and spatial-temporal compression strategies to achieve high performance while minimizing memory and computation costs. Experimental results on CIFAR-10, CIFAR-100, and Google Speech Command datasets demonstrate our proposed LitE-SNNs can achieve competitive or even higher accuracy with remarkably smaller model sizes and fewer computation costs.
5/14/2024