A 65nm 8b-Activation 8b-Weight SRAM-Based Charge-Domain Computing-in-Memory Macro Using A Fully-Parallel Analog Adder Network and A Single-ADC Interface
2212.04320
0
0
🌐
Abstract
Performing data-intensive tasks in the von Neumann architecture is challenging to achieve both high performance and power efficiency due to the memory wall bottleneck. Computing-in-memory (CiM) is a promising mitigation approach by enabling parallel in-situ multiply-accumulate (MAC) operations within the memory with support from the peripheral interface and datapath. SRAM-based charge-domain CiM (CD-CiM) has shown its potential of enhanced power efficiency and computing accuracy. However, existing SRAM-based CD-CiM faces scaling challenges to meet the throughput requirement of high-performance multi-bit-quantization applications. This paper presents an SRAM-based high-throughput ReLU-optimized CD-CiM macro. It is capable of completing MAC and ReLU of two signed 8b vectors in one CiM cycle with only one A/D conversion. Along with non-linearity compensation for the analog computing and A/D conversion interfaces, this work achieves 51.2GOPS throughput and 10.3TOPS/W energy efficiency, while showing 88.6% accuracy in the CIFAR-10 dataset.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Traditional computing architectures struggle to efficiently perform data-intensive tasks due to the "memory wall" bottleneck.
- Computing-in-Memory (CiM) is a promising approach that enables in-situ parallel multiply-accumulate (MAC) operations within memory.
- SRAM-based charge-domain CiM (CD-CiM) offers improved power efficiency and computing accuracy, but faces challenges in scaling to meet high-throughput requirements.
Plain English Explanation
Computers today have a hard time handling large amounts of data quickly and efficiently. This is because of a problem called the "memory wall," where the speed of memory access can't keep up with the speed of the processor.
The solution presented in this paper is a new type of computing called "Computing-in-Memory" (CiM). With CiM, the memory itself can do the math operations, like multiplication and addition, instead of sending the data back and forth between the memory and processor. This allows for much faster and more efficient data processing.
The specific CiM approach used here is called "SRAM-based charge-domain CiM (CD-CiM)." It has shown benefits in power efficiency and accuracy, but struggles to reach the very high speeds needed for some applications.
This paper introduces an improved SRAM-based CD-CiM design that can achieve much higher speeds while maintaining good accuracy. It does this by optimizing the design for a common machine learning operation called ReLU, and making some other technical improvements to the analog-to-digital conversion process.
Technical Explanation
The key innovations presented in this paper are:
-
ReLU-Optimized CD-CiM Macro: The proposed design is optimized to efficiently perform the ReLU (Rectified Linear Unit) non-linear activation function, in addition to MAC operations, within the CiM architecture. This allows for complete neural network inference in a single CiM cycle.
-
Non-Linearity Compensation: The authors develop techniques to compensate for non-linearities introduced by the analog computing and analog-to-digital conversion interfaces. This improves the overall computing accuracy.
-
High-Throughput Design: The proposed CD-CiM macro can complete MAC and ReLU operations on two signed 8-bit vectors in a single CiM cycle, using only one analog-to-digital conversion. This allows it to achieve 51.2 GOPS throughput and 10.3 TOPS/W energy efficiency.
The authors demonstrate the effectiveness of their design by achieving 88.6% accuracy on the CIFAR-10 image recognition dataset, while providing significant improvements in throughput and energy efficiency compared to prior SRAM-based CD-CiM designs.
Critical Analysis
The paper presents a compelling solution to address the memory bottleneck issue in traditional computing architectures. The ReLU-optimized CD-CiM macro shows promising results in terms of throughput and energy efficiency for high-performance machine learning applications.
However, the authors acknowledge that the proposed design still faces some scaling challenges to further increase throughput and meet the requirements of emerging high-performance multi-bit quantization applications. Additionally, the accuracy results, while impressive, may need to be improved for more complex machine learning tasks.
It would be valuable for future research to explore techniques to better mitigate the non-linearities in the analog computing and conversion interfaces, as well as investigate strategies to further scale the CD-CiM architecture without compromising power efficiency and accuracy.
Conclusion
This paper introduces an innovative SRAM-based CD-CiM design that significantly improves the throughput and energy efficiency of data-intensive computing tasks, such as neural network inference. By optimizing the architecture for the ReLU activation function and compensating for analog non-linearities, the authors have demonstrated a practical approach to overcoming the memory wall bottleneck.
The demonstrated capabilities of this CD-CiM macro suggest that computing-in-memory architectures could play a crucial role in enabling high-performance, energy-efficient computing for a wide range of data-centric applications, from machine learning to scientific simulations. As research in this area continues, we can expect to see even more advancements that push the boundaries of what's possible with traditional computing paradigms.
Related Papers
🏷️
Experimental demonstration of magnetic tunnel junction-based computational random-access memory
Yang Lv, Brandon R. Zink, Robert P. Bloom, Husrev C{i}lasun, Pravin Khanal, Salonik Resch, Zamshed Chowdhury, Ali Habiboglu, Weigang Wang, Sachin S. Sapatnekar, Ulya Karpuzcu, Jian-Ping Wang
0
0
Conventional computing paradigm struggles to fulfill the rapidly growing demands from emerging applications, especially those for machine intelligence, because much of the power and energy is consumed by constant data transfers between logic and memory modules. A new paradigm, called computational random-access memory (CRAM) has emerged to address this fundamental limitation. CRAM performs logic operations directly using the memory cells themselves, without having the data ever leave the memory. The energy and performance benefits of CRAM for both conventional and emerging applications have been well established by prior numerical studies. However, there lacks an experimental demonstration and study of CRAM to evaluate its computation accuracy, which is a realistic and application-critical metrics for its technological feasibility and competitiveness. In this work, a CRAM array based on magnetic tunnel junctions (MTJs) is experimentally demonstrated. First, basic memory operations as well as 2-, 3-, and 5-input logic operations are studied. Then, a 1-bit full adder with two different designs is demonstrated. Based on the experimental results, a suite of modeling has been developed to characterize the accuracy of CRAM computation. Further analysis of scalar addition, multiplication, and matrix multiplication shows promising results. These results are then applied to a complete application: a neural network based handwritten digit classifier, as an example to show the connection between the application performance and further MTJ development. The classifier achieved almost-perfect classification accuracy, with reasonable projections of future MTJ development. With the confirmation of MTJ-based CRAM's accuracy, there is a strong case that this technology will have a significant impact on power- and energy-demanding applications of machine intelligence.
4/8/2024
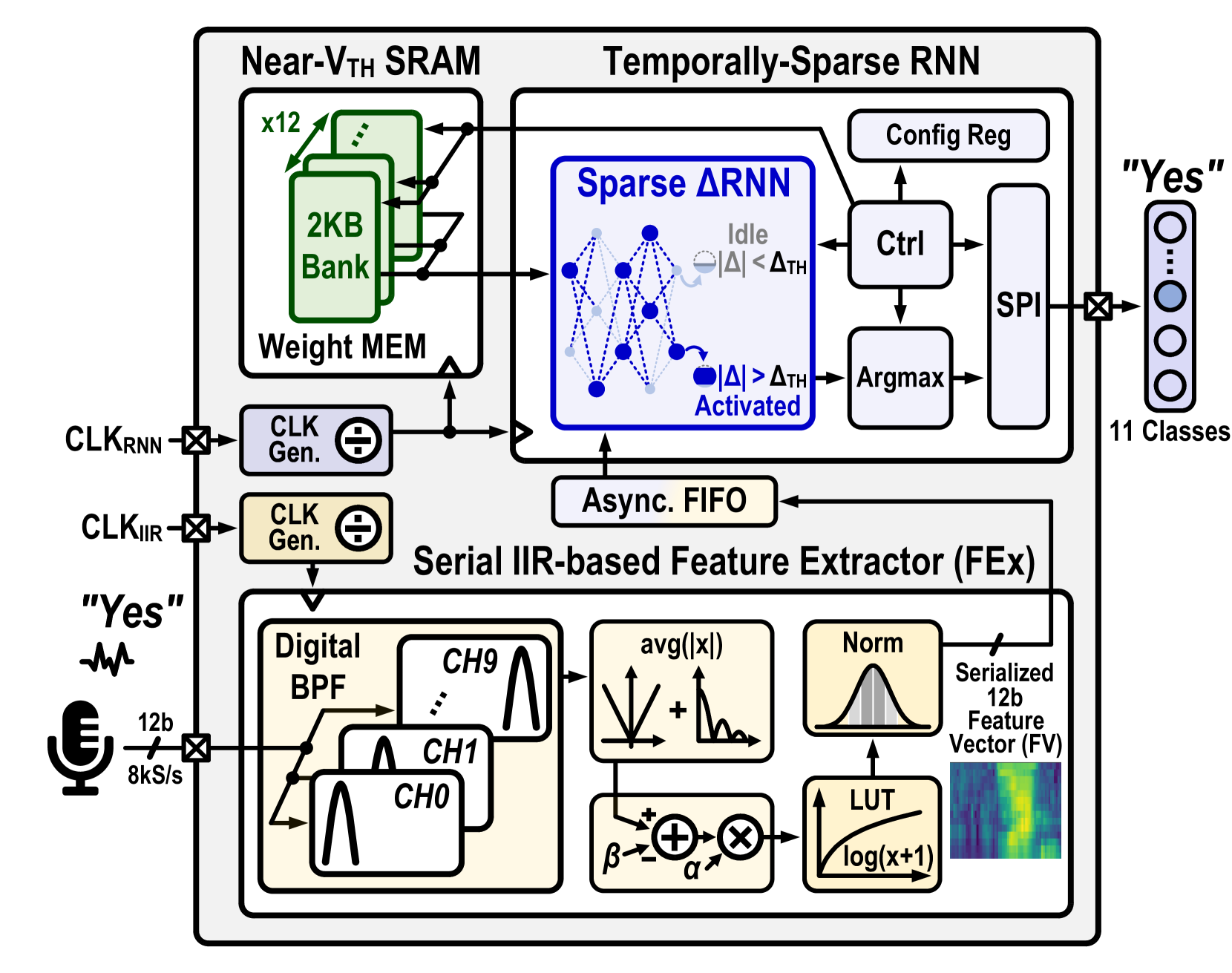
A 65nm 36nJ/Decision Bio-inspired Temporal-Sparsity-Aware Digital Keyword Spotting IC with 0.6V Near-Threshold SRAM
Qinyu Chen, Kwantae Kim, Chang Gao, Sheng Zhou, Taekwang Jang, Tobi Delbruck, Shih-Chii Liu
0
0
This paper introduces, to the best of the authors' knowledge, the first fine-grained temporal sparsity-aware keyword spotting (KWS) IC leveraging temporal similarities between neighboring feature vectors extracted from input frames and network hidden states, eliminating unnecessary operations and memory accesses. This KWS IC, featuring a bio-inspired delta-gated recurrent neural network ({Delta}RNN) classifier, achieves an 11-class Google Speech Command Dataset (GSCD) KWS accuracy of 90.5% and energy consumption of 36nJ/decision. At 87% temporal sparsity, computing latency and energy per inference are reduced by 2.4$times$/3.4$times$, respectively. The 65nm design occupies 0.78mm$^2$ and features two additional blocks, a compact 0.084mm$^2$ digital infinite-impulse-response (IIR)-based band-pass filter (BPF) audio feature extractor (FEx) and a 24kB 0.6V near-Vth weight SRAM with 6.6$times$ lower read power compared to the standard SRAM.
5/8/2024
L0-regularized compressed sensing with Mean-field Coherent Ising Machines
Mastiyage Don Sudeera Hasaranga Gunathilaka, Yoshitaka Inui, Satoshi Kako, Kazushi Mimura, Masato Okada, Yoshihisa Yamamoto, Toru Aonishi
0
0
Coherent Ising Machine (CIM) is a network of optical parametric oscillators that solves combinatorial optimization problems by finding the ground state of an Ising Hamiltonian. As a practical application of CIM, Aonishi et al. proposed a quantum-classical hybrid system to solve optimization problems of L0-regularization-based compressed sensing (L0RBCS). Gunathilaka et al. has further enhanced the accuracy of the system. However, the computationally expensive CIM's stochastic differential equations (SDEs) limit the use of digital hardware implementations. As an alternative to Gunathilaka et al.'s CIM SDEs used previously, we propose using the mean-field CIM (MF-CIM) model, which is a physics-inspired heuristic solver without quantum noise. MF-CIM surmounts the high computational cost due to the simple nature of the differential equations (DEs). Furthermore, our results indicate that the proposed model has similar performance to physically accurate SDEs in both artificial and magnetic resonance imaging data, paving the way for implementing CIM-based L0RBCS on digital hardware such as Field Programmable Gate Arrays (FPGAs).
5/2/2024
🎲
Functionally-Complete Boolean Logic in Real DRAM Chips: Experimental Characterization and Analysis
Ismail Emir Yuksel, Yahya Can Tugrul, Ataberk Olgun, F. Nisa Bostanci, A. Giray Yaglikci, Geraldo F. Oliveira, Haocong Luo, Juan G'omez-Luna, Mohammad Sadrosadati, Onur Mutlu
0
0
Processing-using-DRAM (PuD) is an emerging paradigm that leverages the analog operational properties of DRAM circuitry to enable massively parallel in-DRAM computation. PuD has the potential to reduce or eliminate costly data movement between processing elements and main memory. Prior works experimentally demonstrate three-input MAJ (MAJ3) and two-input AND and OR operations in commercial off-the-shelf (COTS) DRAM chips. Yet, demonstrations on COTS DRAM chips do not provide a functionally complete set of operations. We experimentally demonstrate that COTS DRAM chips are capable of performing 1) functionally-complete Boolean operations: NOT, NAND, and NOR and 2) many-input (i.e., more than two-input) AND and OR operations. We present an extensive characterization of new bulk bitwise operations in 256 off-the-shelf modern DDR4 DRAM chips. We evaluate the reliability of these operations using a metric called success rate: the fraction of correctly performed bitwise operations. Among our 19 new observations, we highlight four major results. First, we can perform the NOT operation on COTS DRAM chips with a 98.37% success rate on average. Second, we can perform up to 16-input NAND, NOR, AND, and OR operations on COTS DRAM chips with high reliability (e.g., 16-input NAND, NOR, AND, and OR with an average success rate of 94.94%, 95.87%, 94.94%, and 95.85%, respectively). Third, data pattern only slightly affects bitwise operations. Our results show that executing NAND, NOR, AND, and OR operations with random data patterns decreases the success rate compared to all logic-1/logic-0 patterns by 1.39%, 1.97%, 1.43%, and 1.98%, respectively. Fourth, bitwise operations are highly resilient to temperature changes, with small success rate fluctuations of at most 1.66% when the temperature is increased from 50C to 95C. We open-source our infrastructure at https://github.com/CMU-SAFARI/FCDRAM
4/23/2024