Accelerating Lattice QCD Simulations using GPUs

0
🏷️
Sign in to get full access
Overview
- The paper discusses the challenge of speeding up lattice Quantum Chromodynamics (QCD) simulations using graphics processing units (GPUs).
- The researchers developed a solver program called DDalphaAMG and explored ways to leverage GPUs to accelerate its computations.
- The paper provides insights into the challenges of porting a memory-bound CPU implementation to GPUs and the potential benefits of using GPUs for large-scale lattice QCD simulations.
Plain English Explanation
Solving the Dirac equation, a key part of lattice Quantum Chromodynamics (QCD) simulations, takes a significant amount of time on high-performance computing (HPC) clusters. To speed up these simulations, many HPC clusters use graphics processing units (GPUs), which can perform computations more quickly than traditional CPUs.
The researchers developed a solver program called DDalphaAMG that was previously unable to fully take advantage of GPUs to accelerate its computations. In this paper, the researchers present their efforts to make use of GPUs for DDalphaAMG.
The researchers developed a storage scheme that allows more efficient memory access on GPUs, as the same data is read from multiple tuples (collections of related data) simultaneously. This helps to address the memory-bound nature of the discrete Dirac operator implementation in DDalphaAMG.
The results show that the GPU implementation of the Wilson-Dirac operator, a key component of lattice QCD simulations, achieved a speedup of around 3 for large lattices. However, the additional overheads introduced by the GPU implementation have not yet been overcome, so the overall performance improvements are limited.
The researchers also found that a previous publication on GPU acceleration of DDalphaAMG had underrepresented the achieved speedup, as small lattices were used in the experiments. This highlights the importance of using large-scale problems to fully realize the benefits of GPUs, as they often require large amounts of data to operate efficiently.
Technical Explanation
The paper presents the researchers' efforts to leverage GPUs to accelerate the DDalphaAMG solver program, which is used in lattice Quantum Chromodynamics (QCD) simulations. Lattice QCD simulations involve solving discretized versions of the Dirac equation, a task that consumes a significant portion of the execution time in these simulations.
The researchers developed a storage scheme for multiple tuples, which allows more efficient memory access on GPUs. This is because the element at the same index is read from multiple tuples simultaneously, a common pattern in lattice QCD computations.
Despite these efforts, the researchers found that the implementation of the discrete Dirac operator in DDalphaAMG remains memory-bound, and the improvements were only achieved for large linear systems on a small number of nodes in the JUWELS cluster. The additional overheads introduced by the GPU implementation have not yet been overcome, limiting the overall performance improvements.
However, the results for the application of the Wilson-Dirac operator, a key component of lattice QCD simulations, show a speedup of around 3 for large lattices. The researchers believe that if the additional overheads can be eliminated in the future, GPUs could potentially reduce the DDalphaAMG execution time significantly for large lattices.
The paper also highlights that a previous publication on the GPU acceleration of DDalphaAMG had underrepresented the achieved speedup, as the experiments were conducted using small lattices. This observation underscores the importance of using large-scale problems to fully leverage the capabilities of GPUs, as they often perform better when dealing with large amounts of data.
Critical Analysis
The paper provides valuable insights into the challenges of porting a memory-bound CPU implementation, such as DDalphaAMG, to GPUs. The researchers' efforts to develop a storage scheme that allows more efficient memory access on GPUs are commendable and represent a step towards better GPU utilization for lattice QCD simulations.
However, the paper also highlights the limitations of the current GPU implementation, as the additional overheads have not yet been overcome. This suggests that further optimization and development work may be necessary to fully realize the potential benefits of using GPUs for this application.
One potential area for further research could be investigating alternative GPU programming models or memory management strategies that may be better suited for the specific memory access patterns and computational requirements of lattice QCD simulations. Additionally, exploring the use of mixed precision computations or other hardware-specific optimizations could potentially help to mitigate the overheads and improve the overall performance of the GPU implementation.
Furthermore, the researchers' observation that a previous publication had underrepresented the achieved speedup due to the use of small lattices is an important reminder of the importance of selecting appropriate benchmark problems when evaluating the performance of GPU-accelerated applications. This highlights the need for researchers to carefully design their experiments and choose representative problem sizes to ensure that the reported results accurately reflect the potential benefits of GPU acceleration.
Conclusion
The paper presents the researchers' efforts to leverage GPUs to accelerate the DDalphaAMG solver program, which is used in lattice Quantum Chromodynamics (QCD) simulations. The researchers developed a storage scheme to improve memory access on GPUs, but the overall implementation remains memory-bound, and the additional overheads have not yet been overcome.
Despite these challenges, the results show a significant speedup of around 3 for the application of the Wilson-Dirac operator on large lattices. This suggests that GPUs have the potential to significantly reduce the execution time of DDalphaAMG for large-scale lattice QCD simulations, provided that the additional overheads can be addressed.
The paper also highlights the importance of using large-scale problems to fully leverage the capabilities of GPUs, as they often perform better when dealing with large amounts of data. This insight can be valuable for researchers and developers working on GPU-accelerated applications in a wide range of scientific and engineering domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏷️
0
Accelerating Lattice QCD Simulations using GPUs
Tilmann Matthaei
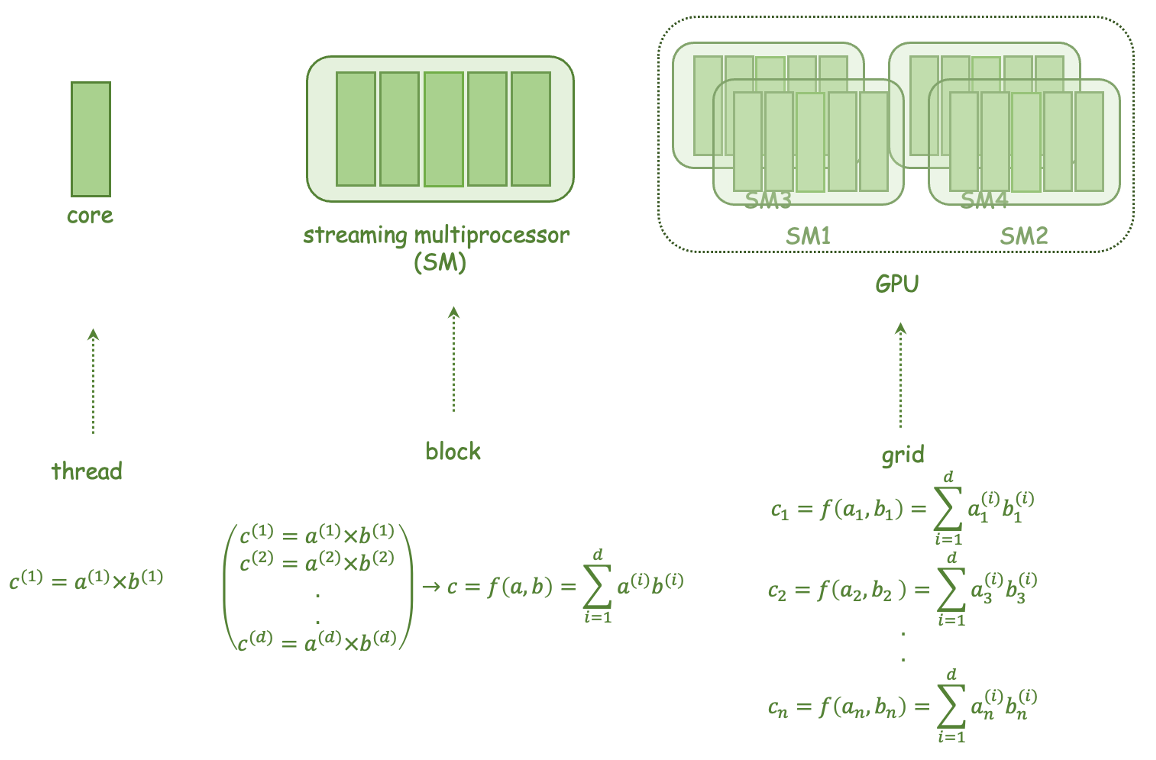
Solving discretized versions of the Dirac equation represents a large share of execution time in lattice Quantum Chromodynamics (QCD) simulations. Many high-performance computing (HPC) clusters use graphics processing units (GPUs) to offer more computational resources. Our solver program, DDalphaAMG, previously was unable to fully take advantage of GPUs to accelerate its computations. Making use of GPUs for DDalphaAMG is an ongoing development, and we will present some current progress herein. Through a detailed description of our development, this thesis should offer valuable insights into using GPUs to accelerate a memory-bound CPU implementation. We developed a storage scheme for multiple tuples, which allows much more efficient memory access on GPUs, given that the element at the same index is read from multiple tuples simultaneously. Still, our implementation of a discrete Dirac operator is memory-bound, and we only achieved improvements for large linear systems on few nodes at the JUWELS cluster. These improvements do not currently overcome additional introduced overheads. However, the results for the application of the Wilson-Dirac operator show a speedup of around 3 for large lattices. If the additional overheads can be eliminated in the future, GPUs could reduce the DDalphaAMG execution time significantly for large lattices. We also found that a previous publication on the GPU acceleration of DDalphaAMG, underrepresented the achieved speedup, because small lattices were used. This further highlights that GPUs often require large-scale problems to solve in order to be faster than CPUs
Read more7/2/2024

0
Extending DD-$alpha$AMG on heterogeneous machines
Lianhua He, Gustavo Ramirez-Hidalgo, Ke-Long Zhang
Multigrid solvers are the standard in modern scientific computing simulations. Domain Decomposition Aggregation-Based Algebraic Multigrid, also known as the DD-$alpha$AMG solver, is a successful realization of an algebraic multigrid solver for lattice quantum chromodynamics. Its CPU implementation has made it possible to construct, for some particular discretizations, simulations otherwise computationally unfeasible, and furthermore it has motivated the development and improvement of other algebraic multigrid solvers in the area. From an existing version of DD-$alpha$AMG already partially ported via CUDA to run some finest-level operations of the multigrid solver on Nvidia GPUs, we translate the CUDA code here by using HIP to run on the ORISE supercomputer. We moreover extend the smoothers available in DD-$alpha$AMG, paying particular attention to Richardson smoothing, which in our numerical experiments has led to a multigrid solver faster than smoothing with GCR and only 10% slower compared to SAP smoothing. Then we port the odd-even-preconditioned versions of GMRES and Richardson via CUDA. Finally, we extend some computationally intensive coarse-grid operations via advanced vectorization.
Read more8/6/2024
0
A Preliminary Study on Accelerating Simulation Optimization with GPU Implementation
Jinghai He, Haoyu Liu, Yuhang Wu, Zeyu Zheng, Tingyu Zhu
We provide a preliminary study on utilizing GPU (Graphics Processing Unit) to accelerate computation for three simulation optimization tasks with either first-order or second-order algorithms. Compared to the implementation using only CPU (Central Processing Unit), the GPU implementation benefits from computational advantages of parallel processing for large-scale matrices and vectors operations. Numerical experiments demonstrate computational advantages of utilizing GPU implementation in simulation optimization problems, and show that such advantage comparatively further increase as the problem scale increases.
Read more4/19/2024

0
Atlas: Hierarchical Partitioning for Quantum Circuit Simulation on GPUs (Extended Version)
Mingkuan Xu, Shiyi Cao, Xupeng Miao, Umut A. Acar, Zhihao Jia
This paper presents techniques for theoretically and practically efficient and scalable Schrodinger-style quantum circuit simulation. Our approach partitions a quantum circuit into a hierarchy of subcircuits and simulates the subcircuits on multi-node GPUs, exploiting available data parallelism while minimizing communication costs. To minimize communication costs, we formulate an Integer Linear Program that rewards simulation of nearby gates on nearby GPUs. To maximize throughput, we use a dynamic programming algorithm to compute the subcircuit simulated by each kernel at a GPU. We realize these techniques in Atlas, a distributed, multi-GPU quantum circuit simulator. Our evaluation on a variety of quantum circuits shows that Atlas outperforms state-of-the-art GPU-based simulators by more than 2$times$ on average and is able to run larger circuits via offloading to DRAM, outperforming other large-circuit simulators by two orders of magnitude.
Read more8/20/2024