Accurate and Reliable Predictions with Mutual-Transport Ensemble
2405.19656
0
0

Abstract
Deep Neural Networks (DNNs) have achieved remarkable success in a variety of tasks, especially when it comes to prediction accuracy. However, in complex real-world scenarios, particularly in safety-critical applications, high accuracy alone is not enough. Reliable uncertainty estimates are crucial. Modern DNNs, often trained with cross-entropy loss, tend to be overconfident, especially with ambiguous samples. To improve uncertainty calibration, many techniques have been developed, but they often compromise prediction accuracy. To tackle this challenge, we propose the ``mutual-transport ensemble'' (MTE). This approach introduces a co-trained auxiliary model and adaptively regularizes the cross-entropy loss using Kullback-Leibler (KL) divergence between the prediction distributions of the primary and auxiliary models. We conducted extensive studies on various benchmarks to validate the effectiveness of our method. The results show that MTE can simultaneously enhance both accuracy and uncertainty calibration. For example, on the CIFAR-100 dataset, our MTE method on ResNet34/50 achieved significant improvements compared to previous state-of-the-art method, with absolute accuracy increases of 2.4%/3.7%, relative reductions in ECE of $42.3%/29.4%, and relative reductions in classwise-ECE of 11.6%/15.3%.
Create account to get full access
Overview
- This paper presents a new ensemble technique called Mutual-Transport Ensemble (MTE) that can produce accurate and reliable predictions.
- MTE leverages the mutual information between ensemble members to improve performance, addressing limitations of existing ensemble methods.
- The authors demonstrate the effectiveness of MTE on various datasets and tasks, showing improvements over state-of-the-art baselines.
Plain English Explanation
The paper introduces a new approach called Mutual-Transport Ensemble (MTE) that can make accurate and trustworthy predictions. Existing ensemble techniques, where multiple models are combined, often struggle to fully leverage the information shared between the individual models. MTE addresses this by explicitly modeling the relationships between the ensemble members using mutual information, a measure of how much one variable depends on another.
By capturing these interdependencies, MTE is able to produce more reliable predictions that outperform other state-of-the-art ensemble methods. The authors test MTE on a variety of datasets and tasks, demonstrating its versatility and strong performance compared to other techniques.
The key idea behind MTE is to go beyond simply averaging the outputs of the ensemble members. Instead, it learns how the individual models interact and uses this understanding to make better overall predictions. This allows MTE to unlock more of the potential of ensemble learning, leading to more accurate and trustworthy results.
Technical Explanation
The paper introduces a new ensemble technique called Mutual-Transport Ensemble (MTE) that can produce more accurate and reliable predictions compared to existing ensemble methods.
MTE addresses limitations of prior ensemble approaches by explicitly modeling the mutual information between the ensemble members. Mutual information is a measure of how much one variable depends on another, and by capturing these interdependencies, MTE can better leverage the complementary strengths of the individual models.
The key technical components of MTE are:
-
Mutual Information Estimation: MTE uses a neural network to estimate the mutual information between the outputs of the ensemble members. This allows it to quantify the relationships between the models.
-
Mutual-Transport Mechanism: MTE then uses this mutual information to transport information between the ensemble members, updating their predictions in a coordinated way. This enhances the complementarity of the models.
-
Ensemble Aggregation: Finally, MTE aggregates the updated predictions from the ensemble members to produce the final output, taking into account their interdependencies.
The authors extensively evaluate MTE on a range of datasets and tasks, including image classification, time series forecasting, and medical diagnosis. The results demonstrate that MTE outperforms various state-of-the-art ensemble techniques, achieving higher accuracy and reliability.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the proposed Mutual-Transport Ensemble (MTE) approach. The authors carefully compare MTE to a diverse set of baseline ensemble methods across multiple datasets and tasks, providing a comprehensive assessment of its capabilities.
One potential limitation of the work is that it focuses primarily on demonstrating the performance improvements of MTE, without delving deeply into the underlying reasons for its success. While the mutual information modeling concept is clearly a key driver, additional analysis of how MTE's unique characteristics lead to better predictions could further strengthen the contribution.
Additionally, the paper does not explore the computational complexity or training time of MTE compared to the baseline approaches. Understanding the tradeoffs in terms of efficiency and scalability would be valuable for assessing the practicality of deploying MTE in real-world applications.
Finally, while the experiments cover a diverse set of tasks, they are still limited to relatively standard machine learning benchmarks. Evaluating MTE on more challenging or domain-specific problems, where ensemble methods may be particularly beneficial, could provide additional insights into its strengths and limitations.
Overall, the Mutual-Transport Ensemble technique presented in this paper represents an interesting and promising advance in ensemble learning. With its strong empirical performance and solid technical foundation, MTE is certainly worthy of further exploration and refinement by the research community.
Conclusion
This paper introduces a novel ensemble learning approach called Mutual-Transport Ensemble (MTE) that can produce more accurate and reliable predictions compared to existing ensemble methods. MTE addresses limitations of prior techniques by explicitly modeling the mutual information between ensemble members, allowing it to better leverage their complementary strengths.
The authors demonstrate the effectiveness of MTE across a range of datasets and tasks, showing consistent improvements over state-of-the-art baselines. This work represents an important step forward in ensemble learning, unlocking new ways to combine multiple models to achieve superior performance.
Looking ahead, further research on the underlying mechanisms of MTE, its computational efficiency, and its applicability to more challenging real-world problems could help solidify its position as a valuable tool in the machine learning practitioner's toolkit.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
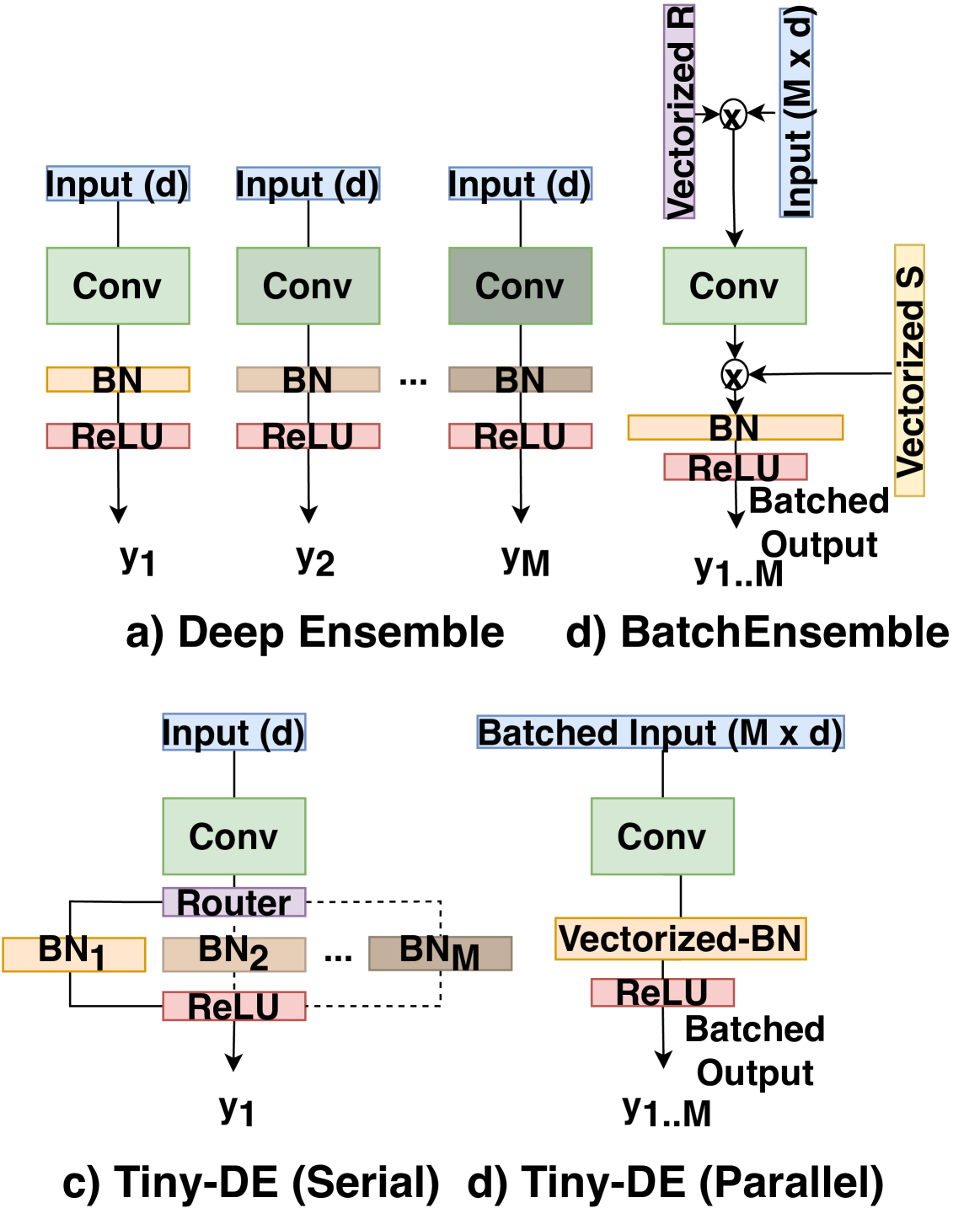
Tiny Deep Ensemble: Uncertainty Estimation in Edge AI Accelerators via Ensembling Normalization Layers with Shared Weights
Soyed Tuhin Ahmed, Michael Hefenbrock, Mehdi B. Tahoori
0
0
The applications of artificial intelligence (AI) are rapidly evolving, and they are also commonly used in safety-critical domains, such as autonomous driving and medical diagnosis, where functional safety is paramount. In AI-driven systems, uncertainty estimation allows the user to avoid overconfidence predictions and achieve functional safety. Therefore, the robustness and reliability of model predictions can be improved. However, conventional uncertainty estimation methods, such as the deep ensemble method, impose high computation and, accordingly, hardware (latency and energy) overhead because they require the storage and processing of multiple models. Alternatively, Monte Carlo dropout (MC-dropout) methods, although having low memory overhead, necessitate numerous ($sim 100$) forward passes, leading to high computational overhead and latency. Thus, these approaches are not suitable for battery-powered edge devices with limited computing and memory resources. In this paper, we propose the Tiny-Deep Ensemble approach, a low-cost approach for uncertainty estimation on edge devices. In our approach, only normalization layers are ensembled $M$ times, with all ensemble members sharing common weights and biases, leading to a significant decrease in storage requirements and latency. Moreover, our approach requires only one forward pass in a hardware architecture that allows batch processing for inference and uncertainty estimation. Furthermore, it has approximately the same memory overhead compared to a single model. Therefore, latency and memory overhead are reduced by a factor of up to $sim Mtimes$. Nevertheless, our method does not compromise accuracy, with an increase in inference accuracy of up to $sim 1%$ and a reduction in RMSE of $17.17%$ in various benchmark datasets, tasks, and state-of-the-art architectures.
5/10/2024
🧠
Affine Invariant Ensemble Transform Methods to Improve Predictive Uncertainty in Neural Networks
Diksha Bhandari, Jakiw Pidstrigach, Sebastian Reich
0
0
We consider the problem of performing Bayesian inference for logistic regression using appropriate extensions of the ensemble Kalman filter. Two interacting particle systems are proposed that sample from an approximate posterior and prove quantitative convergence rates of these interacting particle systems to their mean-field limit as the number of particles tends to infinity. Furthermore, we apply these techniques and examine their effectiveness as methods of Bayesian approximation for quantifying predictive uncertainty in neural networks.
7/2/2024

Enabling Uncertainty Estimation in Iterative Neural Networks
Nikita Durasov, Doruk Oner, Jonathan Donier, Hieu Le, Pascal Fua
0
0
Turning pass-through network architectures into iterative ones, which use their own output as input, is a well-known approach for boosting performance. In this paper, we argue that such architectures offer an additional benefit: The convergence rate of their successive outputs is highly correlated with the accuracy of the value to which they converge. Thus, we can use the convergence rate as a useful proxy for uncertainty. This results in an approach to uncertainty estimation that provides state-of-the-art estimates at a much lower computational cost than techniques like Ensembles, and without requiring any modifications to the original iterative model. We demonstrate its practical value by embedding it in two application domains: road detection in aerial images and the estimation of aerodynamic properties of 2D and 3D shapes.
5/31/2024

Multi-modal Evidential Fusion Network for Trusted PET/CT Tumor Segmentation
Yuxuan Qi, Li Lin, Jiajun Wang, Jingya Zhang, Bin Zhang
0
0
Accurate segmentation of tumors in PET/CT images is important in computer-aided diagnosis and treatment of cancer. The key issue of such a segmentation problem lies in the effective integration of complementary information from PET and CT images. However, the quality of PET and CT images varies widely in clinical settings, which leads to uncertainty in the modality information extracted by networks. To take the uncertainty into account in multi-modal information fusion, this paper proposes a novel Multi-modal Evidential Fusion Network (MEFN) comprising a Cross-Modal Feature Learning (CFL) module and a Multi-modal Trusted Fusion (MTF) module. The CFL module reduces the domain gap upon modality conversion and highlights common tumor features, thereby alleviating the needs of the segmentation module to handle modality specificity. The MTF module utilizes mutual attention mechanisms and an uncertainty calibrator to fuse modality features based on modality uncertainty and then fuse the segmentation results under the guidance of Dempster-Shafer Theory. Besides, a new uncertainty perceptual loss is introduced to force the model focusing on uncertain features and hence improve its ability to extract trusted modality information. Extensive comparative experiments are conducted on two publicly available PET/CT datasets to evaluate the performance of our proposed method whose results demonstrate that our MEFN significantly outperforms state-of-the-art methods with improvements of 2.15% and 3.23% in DSC scores on the AutoPET dataset and the Hecktor dataset, respectively. More importantly, our model can provide radiologists with credible uncertainty of the segmentation results for their decision in accepting or rejecting the automatic segmentation results, which is particularly important for clinical applications. Our code will be available at https://github.com/QPaws/MEFN.
6/27/2024