Tiny Deep Ensemble: Uncertainty Estimation in Edge AI Accelerators via Ensembling Normalization Layers with Shared Weights
2405.05286
0
0
Abstract
The applications of artificial intelligence (AI) are rapidly evolving, and they are also commonly used in safety-critical domains, such as autonomous driving and medical diagnosis, where functional safety is paramount. In AI-driven systems, uncertainty estimation allows the user to avoid overconfidence predictions and achieve functional safety. Therefore, the robustness and reliability of model predictions can be improved. However, conventional uncertainty estimation methods, such as the deep ensemble method, impose high computation and, accordingly, hardware (latency and energy) overhead because they require the storage and processing of multiple models. Alternatively, Monte Carlo dropout (MC-dropout) methods, although having low memory overhead, necessitate numerous ($sim 100$) forward passes, leading to high computational overhead and latency. Thus, these approaches are not suitable for battery-powered edge devices with limited computing and memory resources. In this paper, we propose the Tiny-Deep Ensemble approach, a low-cost approach for uncertainty estimation on edge devices. In our approach, only normalization layers are ensembled $M$ times, with all ensemble members sharing common weights and biases, leading to a significant decrease in storage requirements and latency. Moreover, our approach requires only one forward pass in a hardware architecture that allows batch processing for inference and uncertainty estimation. Furthermore, it has approximately the same memory overhead compared to a single model. Therefore, latency and memory overhead are reduced by a factor of up to $sim Mtimes$. Nevertheless, our method does not compromise accuracy, with an increase in inference accuracy of up to $sim 1%$ and a reduction in RMSE of $17.17%$ in various benchmark datasets, tasks, and state-of-the-art architectures.
Create account to get full access
Overview
- This paper introduces a novel approach called "Tiny Deep Ensemble" for uncertainty estimation in edge AI accelerators, which is an important capability for safety-critical applications.
- The method leverages an ensemble of normalization layers with shared weights to capture model uncertainty, resulting in a compact and efficient solution that can be deployed on resource-constrained edge devices.
- The authors demonstrate the effectiveness of Tiny Deep Ensemble on various benchmark datasets, showing that it can achieve comparable or better uncertainty estimation performance compared to existing techniques like MC-Dropout and Deep Ensembles, while being significantly more efficient.
Plain English Explanation
The paper proposes a new way to estimate the uncertainty of artificial intelligence (AI) models running on edge devices, which are small, low-power computers like smartphones or smart home assistants. Uncertainty estimation is important for safety-critical applications, like self-driving cars or medical diagnostics, where the AI system needs to be able to recognize when it's unsure about its predictions.
The key idea is to use an "ensemble" of slightly different versions of the AI model, all running in parallel. Each version has its own set of "normalization layers" that help the model learn features from the input data. By ensembling these normalization layers, the system can capture the model's uncertainty without needing to run multiple full copies of the model, which would be too computationally expensive for edge devices.
The authors show that this "Tiny Deep Ensemble" approach works well on a variety of machine learning benchmark tasks, providing uncertainty estimates that are as good as or better than more complex techniques, but using much less computational resources. This makes it a promising solution for deploying reliable and safe AI systems on smartphones, smart home devices, and other edge computing platforms.
Technical Explanation
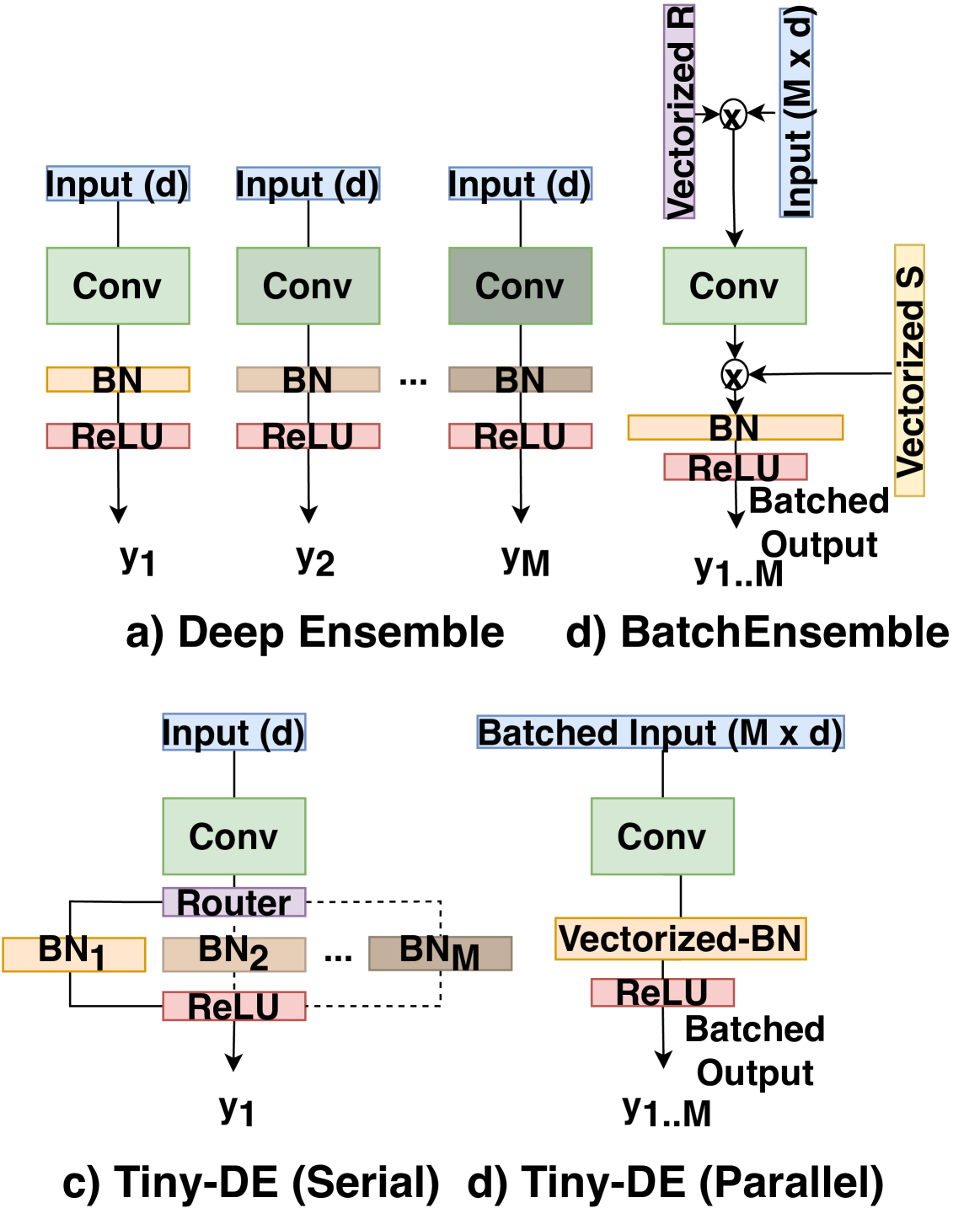
The paper introduces a novel uncertainty estimation technique called "Tiny Deep Ensemble" that is tailored for deployment on resource-constrained edge AI accelerators. The core idea is to ensemble normalization layers with shared weights, rather than ensembling full neural network models, which is the standard approach used in Deep Ensembles.
Normalization layers are an important component of modern neural networks, as they help stabilize the training process and improve model performance. By ensembling these normalization layers, the authors are able to capture model uncertainty in a compact and efficient manner, without the need to run multiple full copies of the neural network.
Specifically, the Tiny Deep Ensemble architecture consists of a shared feature extractor backbone, followed by an ensemble of normalization layers and separate prediction heads. This allows the model to learn a shared representation while maintaining diversity in the normalization statistics, which is key for effective uncertainty estimation.
The authors evaluate Tiny Deep Ensemble on various computer vision and regression benchmarks, including CIFAR-10, CIFAR-100, and Regression UCI datasets. They show that the method can achieve comparable or better uncertainty estimation performance compared to MC-Dropout and Deep Ensembles, while being significantly more parameter-efficient and computationally lightweight, making it well-suited for deployment on edge AI accelerators.
Critical Analysis
The Tiny Deep Ensemble approach proposed in this paper is a clever and promising technique for improving the reliability of AI systems running on resource-constrained edge devices. By ensembling normalization layers rather than full neural networks, the authors have found a way to capture model uncertainty in a compact and efficient manner.
One potential limitation of the method is that it may not be able to capture as diverse a range of uncertainties as approaches that ensemble full models, such as Deep Ensembles. The authors acknowledge this in the paper, noting that there may be some trade-offs between the efficiency of Tiny Deep Ensemble and the expressiveness of the uncertainty estimates.
Additionally, the authors only evaluate their method on a limited number of benchmark datasets. It would be valuable to see how Tiny Deep Ensemble performs on a wider range of applications, particularly in more safety-critical domains like autonomous driving or medical diagnosis.
Another area for further research could be exploring ways to further compress and accelerate the Tiny Deep Ensemble architecture, potentially through techniques like model distillation or weight sharing. This could unlock even greater efficiency improvements for deployment on the most resource-constrained edge devices.
Conclusion
The "Tiny Deep Ensemble" approach presented in this paper is a novel and compelling solution for enabling reliable uncertainty estimation in edge AI accelerators. By ensembling normalization layers rather than full neural network models, the authors have found a way to capture model uncertainty in a compact and efficient manner, making it well-suited for deployment on resource-constrained devices.
The results demonstrate that Tiny Deep Ensemble can achieve comparable or better uncertainty estimation performance compared to existing techniques, while being significantly more parameter-efficient and computationally lightweight. This is a promising step forward in making AI systems safer and more reliable, particularly for safety-critical applications on edge devices.
As the use of AI continues to expand into more domains, including those with high-stakes consequences, the ability to quantify and reason about model uncertainty will become increasingly important. The Tiny Deep Ensemble approach offers a compelling solution that could help unlock the full potential of edge AI while ensuring the necessary reliability and robustness.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛠️
QUTE: Quantifying Uncertainty in TinyML models with Early-exit-assisted ensembles
Nikhil P Ghanathe, Steve Wilton
0
0
Existing methods for uncertainty quantification incur massive memory and compute overhead, often requiring multiple models/inferences. Hence they are impractical on ultra-low-power KB-sized TinyML devices. To reduce overhead, prior works have proposed the use of early-exit networks as ensembles to quantify uncertainty in a single forward-pass. However, they still have a prohibitive cost for tinyML. To address these challenges, we propose QUTE, a novel resource-efficient early-exit-assisted ensemble architecture optimized for tinyML models. QUTE adds additional output blocks at the final exit of the base network and distills the knowledge of early-exits into these blocks to create a diverse and lightweight ensemble architecture. Our results show that QUTE outperforms popular prior works, and improves the quality of uncertainty estimates by 6% with 3.1x lower model size on average compared to the most relevant prior work. Furthermore, we demonstrate that QUTE is also effective in detecting co-variate shifted and out-of-distribution inputs, and shows competitive performance relative to G-ODIN, a state-of-the-art generalized OOD detector.
4/22/2024

Accurate and Reliable Predictions with Mutual-Transport Ensemble
Han Liu, Peng Cui, Bingning Wang, Jun Zhu, Xiaolin Hu
0
0
Deep Neural Networks (DNNs) have achieved remarkable success in a variety of tasks, especially when it comes to prediction accuracy. However, in complex real-world scenarios, particularly in safety-critical applications, high accuracy alone is not enough. Reliable uncertainty estimates are crucial. Modern DNNs, often trained with cross-entropy loss, tend to be overconfident, especially with ambiguous samples. To improve uncertainty calibration, many techniques have been developed, but they often compromise prediction accuracy. To tackle this challenge, we propose the ``mutual-transport ensemble'' (MTE). This approach introduces a co-trained auxiliary model and adaptively regularizes the cross-entropy loss using Kullback-Leibler (KL) divergence between the prediction distributions of the primary and auxiliary models. We conducted extensive studies on various benchmarks to validate the effectiveness of our method. The results show that MTE can simultaneously enhance both accuracy and uncertainty calibration. For example, on the CIFAR-100 dataset, our MTE method on ResNet34/50 achieved significant improvements compared to previous state-of-the-art method, with absolute accuracy increases of 2.4%/3.7%, relative reductions in ECE of $42.3%/29.4%, and relative reductions in classwise-ECE of 11.6%/15.3%.
5/31/2024
🤯
ZigZag: Universal Sampling-free Uncertainty Estimation Through Two-Step Inference
Nikita Durasov, Nik Dorndorf, Hieu Le, Pascal Fua
0
0
Whereas the ability of deep networks to produce useful predictions has been amply demonstrated, estimating the reliability of these predictions remains challenging. Sampling approaches such as MC-Dropout and Deep Ensembles have emerged as the most popular ones for this purpose. Unfortunately, they require many forward passes at inference time, which slows them down. Sampling-free approaches can be faster but suffer from other drawbacks, such as lower reliability of uncertainty estimates, difficulty of use, and limited applicability to different types of tasks and data. In this work, we introduce a sampling-free approach that is generic and easy to deploy, while producing reliable uncertainty estimates on par with state-of-the-art methods at a significantly lower computational cost. It is predicated on training the network to produce the same output with and without additional information about it. At inference time, when no prior information is given, we use the network's own prediction as the additional information. We then take the distance between the predictions with and without prior information as our uncertainty measure. We demonstrate our approach on several classification and regression tasks. We show that it delivers results on par with those of Ensembles but at a much lower computational cost.
5/28/2024

Enabling Uncertainty Estimation in Iterative Neural Networks
Nikita Durasov, Doruk Oner, Jonathan Donier, Hieu Le, Pascal Fua
0
0
Turning pass-through network architectures into iterative ones, which use their own output as input, is a well-known approach for boosting performance. In this paper, we argue that such architectures offer an additional benefit: The convergence rate of their successive outputs is highly correlated with the accuracy of the value to which they converge. Thus, we can use the convergence rate as a useful proxy for uncertainty. This results in an approach to uncertainty estimation that provides state-of-the-art estimates at a much lower computational cost than techniques like Ensembles, and without requiring any modifications to the original iterative model. We demonstrate its practical value by embedding it in two application domains: road detection in aerial images and the estimation of aerodynamic properties of 2D and 3D shapes.
5/31/2024