AceGPT, Localizing Large Language Models in Arabic
2309.12053
0
0
Abstract
This paper is devoted to the development of a localized Large Language Model (LLM) specifically for Arabic, a language imbued with unique cultural characteristics inadequately addressed by current mainstream models. Significant concerns emerge when addressing cultural sensitivity and local values. To address this, the paper proposes a comprehensive solution that includes further pre-training with Arabic texts, Supervised Fine-Tuning (SFT) utilizing native Arabic instructions, and GPT-4 responses in Arabic, alongside Reinforcement Learning with AI Feedback (RLAIF) employing a reward model attuned to local culture and values. The goal is to cultivate culturally cognizant and value-aligned Arabic LLMs capable of accommodating the diverse, application-specific needs of Arabic-speaking communities. Comprehensive evaluations reveal that the resulting model, dubbed `AceGPT', sets the state-of-the-art standard for open Arabic LLMs across various benchmarks. Codes, data, and models are in https://github.com/FreedomIntelligence/AceGPT.
Create account to get full access
Overview
- This paper describes the development of "AceGPT", a large language model trained on Arabic text to improve the performance of language AI systems for Arabic speakers.
- The researchers focused on localizing the model to better handle the complexities of the Arabic language, which has significant grammatical and lexical differences from English.
- Key aspects include the model architecture, training process, and evaluation of the localized model's performance on various Arabic language tasks.
Plain English Explanation
The researchers recognized that while large language models like GPT have revolutionized natural language processing, they are primarily trained on English text. This can make them less effective at understanding and generating Arabic text, which has a very different structure and vocabulary.
To address this, the researchers developed AceGPT, a version of a large language model that has been "localized" or specialized for the Arabic language. This involved training the model on a large corpus of Arabic text from diverse sources, allowing it to learn the nuances and complexities of the language.
The researchers paid close attention to aspects like Arabic grammar, idioms, and dialects to ensure AceGPT could handle the language effectively. They then evaluated the model's performance on a variety of Arabic language tasks, such as question answering, summarization, and text generation.
Overall, the results showed that AceGPT outperformed generic language models when working with Arabic text. This suggests that localizing large language models to specific languages and cultures can significantly improve their real-world usefulness, especially for languages quite different from English.
Technical Explanation
The researchers used a transformer-based architecture as the foundation for AceGPT, inheriting the powerful language modeling capabilities of models like GPT-3. However, they made several modifications to adapt the model for Arabic.
First, they trained AceGPT on a large corpus of Arabic text from sources like news articles, books, and websites. This allowed the model to learn the unique grammar, vocabulary, and writing styles of the language.
The researchers also incorporated techniques to handle Arabic-specific challenges, such as diacritics (vowel markings), complex morphology, and dialectal variations. This included using character-level tokenization and specialized pretraining objectives.
To evaluate AceGPT, the researchers assessed its performance on a range of Arabic NLP tasks, including question answering, text summarization, and language generation. They compared it to both generic language models and models specialized for Arabic, demonstrating significant improvements in areas like factual correctness and fluency.
Critical Analysis
The paper provides a thorough and well-designed approach to localizing a large language model for the Arabic language. The researchers thoughtfully considered the unique challenges of Arabic and implemented appropriate architectural choices and training strategies.
That said, the paper does note some limitations. The model was trained on a relatively limited corpus of Arabic text, so its performance may be constrained by the diversity and quality of the training data. Additionally, the evaluation was conducted on standard benchmarks, but real-world performance may differ.
Future work could explore further enhancements, such as incorporating more extensive dialectal and cultural knowledge, or developing novel fine-tuning techniques for specific Arabic NLP applications. Investigating the model's robustness to noisy or informal Arabic text could also be valuable.
Overall, the development of AceGPT represents an important step in making large language models more accessible and useful for Arabic speakers. The principles and techniques demonstrated in this work could inspire similar localization efforts for other non-English languages.
Conclusion
The AceGPT paper demonstrates the value of tailoring large language models to specific languages and cultural contexts. By localizing a transformer-based model for Arabic, the researchers were able to significantly improve its performance on a variety of Arabic NLP tasks compared to generic language models.
This work highlights the importance of considering language-specific nuances when developing AI systems for global audiences. As language technology continues to advance, efforts like this will be crucial for ensuring equitable access and usefulness across diverse linguistic communities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
How good are Large Language Models on African Languages?
Jessica Ojo, Kelechi Ogueji, Pontus Stenetorp, David Ifeoluwa Adelani
0
0
Recent advancements in natural language processing have led to the proliferation of large language models (LLMs). These models have been shown to yield good performance, using in-context learning, even on tasks and languages they are not trained on. However, their performance on African languages is largely understudied relative to high-resource languages. We present an analysis of four popular large language models (mT0, Aya, LLaMa 2, and GPT-4) on six tasks (topic classification, sentiment classification, machine translation, summarization, question answering, and named entity recognition) across 60 African languages, spanning different language families and geographical regions. Our results suggest that all LLMs produce lower performance for African languages, and there is a large gap in performance compared to high-resource languages (such as English) for most tasks. We find that GPT-4 has an average to good performance on classification tasks, yet its performance on generative tasks such as machine translation and summarization is significantly lacking. Surprisingly, we find that mT0 had the best overall performance for cross-lingual QA, better than the state-of-the-art supervised model (i.e. fine-tuned mT5) and GPT-4 on African languages. Similarly, we find the recent Aya model to have comparable result to mT0 in almost all tasks except for topic classification where it outperform mT0. Overall, LLaMa 2 showed the worst performance, which we believe is due to its English and code-centric~(around 98%) pre-training corpus. Our findings confirms that performance on African languages continues to remain a hurdle for the current LLMs, underscoring the need for additional efforts to close this gap.
5/1/2024
💬
Multilingual Machine Translation with Large Language Models: Empirical Results and Analysis
Wenhao Zhu, Hongyi Liu, Qingxiu Dong, Jingjing Xu, Shujian Huang, Lingpeng Kong, Jiajun Chen, Lei Li
0
0
Large language models (LLMs) have demonstrated remarkable potential in handling multilingual machine translation (MMT). In this paper, we systematically investigate the advantages and challenges of LLMs for MMT by answering two questions: 1) How well do LLMs perform in translating massive languages? 2) Which factors affect LLMs' performance in translation? We thoroughly evaluate eight popular LLMs, including ChatGPT and GPT-4. Our empirical results show that translation capabilities of LLMs are continually involving. GPT-4 has beat the strong supervised baseline NLLB in 40.91% of translation directions but still faces a large gap towards the commercial translation system like Google Translate, especially on low-resource languages. Through further analysis, we discover that LLMs exhibit new working patterns when used for MMT. First, LLM can acquire translation ability in a resource-efficient way and generate moderate translation even on zero-resource languages. Second, instruction semantics can surprisingly be ignored when given in-context exemplars. Third, cross-lingual exemplars can provide better task guidance for low-resource translation than exemplars in the same language pairs. Code will be released at: https://github.com/NJUNLP/MMT-LLM.
6/17/2024
💬
AlignGPT: Multi-modal Large Language Models with Adaptive Alignment Capability
Fei Zhao, Taotian Pang, Chunhui Li, Zhen Wu, Junjie Guo, Shangyu Xing, Xinyu Dai
0
0
Multimodal Large Language Models (MLLMs) are widely regarded as crucial in the exploration of Artificial General Intelligence (AGI). The core of MLLMs lies in their capability to achieve cross-modal alignment. To attain this goal, current MLLMs typically follow a two-phase training paradigm: the pre-training phase and the instruction-tuning phase. Despite their success, there are shortcomings in the modeling of alignment capabilities within these models. Firstly, during the pre-training phase, the model usually assumes that all image-text pairs are uniformly aligned, but in fact the degree of alignment between different image-text pairs is inconsistent. Secondly, the instructions currently used for finetuning incorporate a variety of tasks, different tasks's instructions usually require different levels of alignment capabilities, but previous MLLMs overlook these differentiated alignment needs. To tackle these issues, we propose a new multimodal large language model AlignGPT. In the pre-training stage, instead of treating all image-text pairs equally, we assign different levels of alignment capabilities to different image-text pairs. Then, in the instruction-tuning phase, we adaptively combine these different levels of alignment capabilities to meet the dynamic alignment needs of different instructions. Extensive experimental results show that our model achieves competitive performance on 12 benchmarks.
5/24/2024
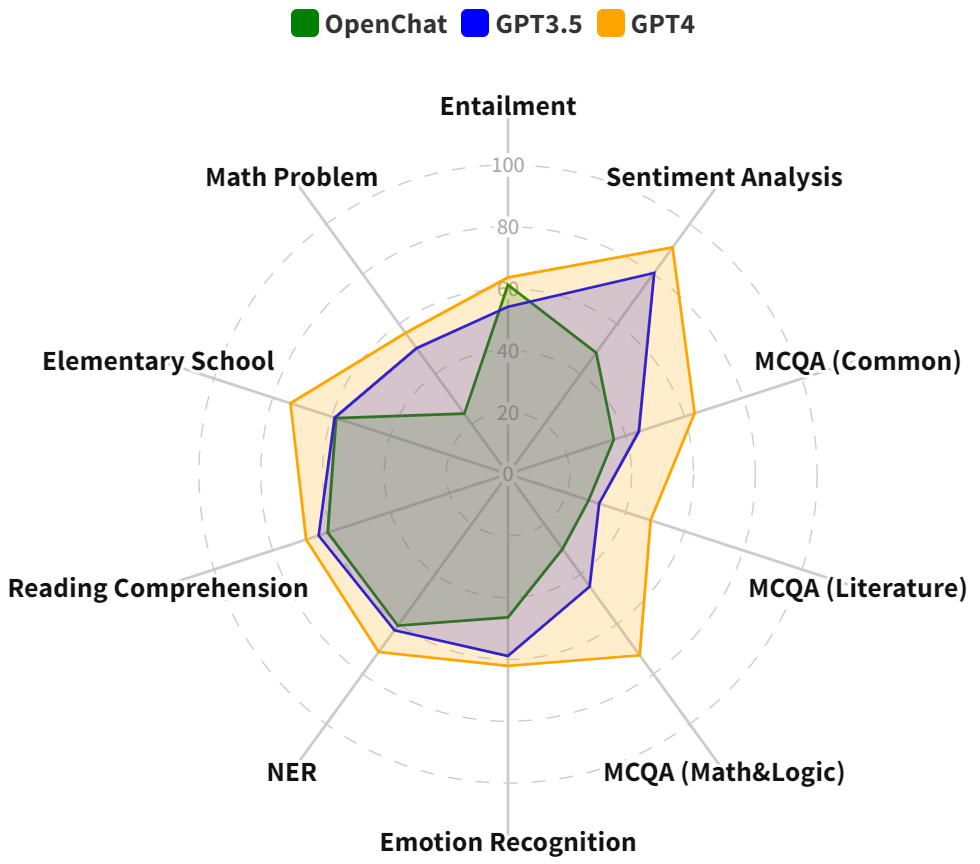
Benchmarking Large Language Models for Persian: A Preliminary Study Focusing on ChatGPT
Amirhossein Abaskohi, Sara Baruni, Mostafa Masoudi, Nesa Abbasi, Mohammad Hadi Babalou, Ali Edalat, Sepehr Kamahi, Samin Mahdizadeh Sani, Nikoo Naghavian, Danial Namazifard, Pouya Sadeghi, Yadollah Yaghoobzadeh
0
0
This paper explores the efficacy of large language models (LLMs) for Persian. While ChatGPT and consequent LLMs have shown remarkable performance in English, their efficiency for more low-resource languages remains an open question. We present the first comprehensive benchmarking study of LLMs across diverse Persian language tasks. Our primary focus is on GPT-3.5-turbo, but we also include GPT-4 and OpenChat-3.5 to provide a more holistic evaluation. Our assessment encompasses a diverse set of tasks categorized into classic, reasoning, and knowledge-based domains. To enable a thorough comparison, we evaluate LLMs against existing task-specific fine-tuned models. Given the limited availability of Persian datasets for reasoning tasks, we introduce two new benchmarks: one based on elementary school math questions and another derived from the entrance exams for 7th and 10th grades. Our findings reveal that while LLMs, especially GPT-4, excel in tasks requiring reasoning abilities and a broad understanding of general knowledge, they often lag behind smaller pre-trained models fine-tuned specifically for particular tasks. Additionally, we observe improved performance when test sets are translated to English before inputting them into GPT-3.5. These results highlight the significant potential for enhancing LLM performance in the Persian language. This is particularly noteworthy due to the unique attributes of Persian, including its distinct alphabet and writing styles.
4/4/2024