Active Learning-based Model Predictive Coverage Control
2303.09910
0
0
📈
Abstract
The problem of coverage control, i.e., of coordinating multiple agents to optimally cover an area, arises in various applications. However, coverage applications face two major challenges: (1) dealing with nonlinear dynamics while respecting system and safety critical constraints, and (2) performing the task in an initially unknown environment. We solve the coverage problem by using a hierarchical framework, in which references are calculated at a central server and passed to the agents' local model predictive control (MPC) tracking schemes. Furthermore, to ensure that the environment is actively explored by the agents a probabilistic exploration-exploitation trade-off is deployed. In addition, we derive a control framework that avoids the hierarchical structure by integrating the reference optimization in the MPC formulation. Active learning is then performed drawing inspiration from Upper Confidence Bound (UCB) approaches. For all developed control architectures, we guarantee closed-loop constraint satisfaction and convergence to an optimal configuration. Furthermore, all methods are tested and compared on hardware using a miniature car platform.
Create account to get full access
Overview
- The research paper focuses on the problem of coverage control, which involves coordinating multiple agents to optimally cover an area.
- The paper addresses two key challenges: dealing with nonlinear dynamics while respecting system and safety constraints, and performing the task in an initially unknown environment.
- The researchers propose a hierarchical framework and an integration of reference optimization within the model predictive control (MPC) formulation to solve the coverage problem.
- The methods involve active exploration of the environment and guarantee closed-loop constraint satisfaction and convergence to an optimal configuration.
- The developed control architectures are tested and compared on a miniature car platform.
Plain English Explanation
Imagine you have a team of robots, and you want them to work together to cover as much ground as possible. This is called the coverage control problem, and it's useful in applications like search and rescue, environmental monitoring, and surveillance.
The challenge is that the robots have to deal with complex, nonlinear movement patterns, and they need to respect safety rules and constraints. On top of that, the robots are operating in an environment that they don't know much about initially.
The researchers in this paper came up with a couple of different approaches to solve this problem. One method uses a central server to calculate the best paths for the robots, and then the robots use their own control systems to follow those paths. The other method integrates the path planning directly into the robots' control systems.
Both approaches use a technique called active exploration to make sure the robots are constantly learning about the environment and adjusting their coverage accordingly. The researchers also made sure the robots could always follow the paths without violating any safety rules.
The researchers tested these methods on a small-scale platform with miniature cars, and they showed that the approaches can effectively coordinate the robots to cover an area efficiently, even in unknown environments.
Technical Explanation
The paper presents a solution to the coverage control problem, which involves coordinating multiple agents to optimally cover an area. The researchers address two key challenges: dealing with nonlinear dynamics while respecting system and safety critical constraints, and performing the task in an initially unknown environment.
To solve the coverage problem, the researchers propose a hierarchical framework, where a central server calculates reference trajectories that are then tracked by the agents' local model predictive control (MPC) schemes. This ensures the agents can respect the system and safety constraints while following the optimal coverage paths.
Additionally, to enable active exploration of the environment, the researchers deploy a probabilistic exploration-exploitation trade-off strategy. This allows the agents to balance exploring unknown areas and exploiting known information to optimize coverage.
The researchers also derive a control framework that avoids the hierarchical structure by integrating the reference optimization directly into the MPC formulation. This "integrated" approach performs active learning inspired by Upper Confidence Bound (UCB) techniques.
For both the hierarchical and integrated control architectures, the researchers guarantee closed-loop constraint satisfaction and convergence to an optimal configuration. The methods are thoroughly evaluated on a miniature car platform to validate their effectiveness.
Critical Analysis
The paper presents a comprehensive solution to the challenging coverage control problem, addressing both the nonlinear dynamics and unknown environment aspects. The proposed hierarchical and integrated control frameworks show promising results in the hardware experiments, demonstrating their practical applicability.
One potential limitation noted in the paper is the assumption of full communication between the central server and the agents in the hierarchical approach. This could be a bottleneck in larger-scale or distributed scenarios. The researchers suggest exploring decentralized approaches as future work to address this.
Additionally, the paper does not delve into the computational complexity of the proposed methods, which could be an important consideration for real-world deployments, especially as the number of agents and the size of the environment scale up.
Further research could also investigate the robustness of the approaches to sensor noise, agent failures, or other real-world uncertainties that may arise in practical applications. Exploring extensions to more heterogeneous agent teams or dynamic environments could also be valuable.
Overall, the paper presents a solid foundation for solving the coverage control problem and offers insights that could inspire future research in this important area of multi-agent coordination and control.
Conclusion
This research paper tackles the challenging problem of coverage control, where multiple agents need to coordinate to efficiently cover an unknown area while respecting system constraints. The researchers propose two control architectures - a hierarchical approach and an integrated approach - that enable active exploration of the environment and guarantee optimal coverage.
The key contributions of this work are the development of these control frameworks, the integration of active learning techniques, and the validation of the methods on a hardware platform. These advancements have the potential to enable more robust and reliable coverage control systems for a wide range of applications, from search and rescue operations to environmental monitoring and surveillance.
As the field of multi-agent coordination continues to evolve, this research provides a valuable foundation and insights that could inspire further innovations in this important area of study.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Learning Hierarchical Control For Multi-Agent Capacity-Constrained Systems
Charlott Vallon, Alessandro Pinto, Bartolomeo Stellato, Francesco Borrelli
0
0
This paper introduces a novel data-driven hierarchical control scheme for managing a fleet of nonlinear, capacity-constrained autonomous agents in an iterative environment. We propose a control framework consisting of a high-level dynamic task assignment and routing layer and low-level motion planning and tracking layer. Each layer of the control hierarchy uses a data-driven Model Predictive Control (MPC) policy, maintaining bounded computational complexity at each calculation of a new task assignment or actuation input. We utilize collected data to iteratively refine estimates of agent capacity usage, and update MPC policy parameters accordingly. Our approach leverages tools from iterative learning control to integrate learning at both levels of the hierarchy, and coordinates learning between levels in order to maintain closed-loop feasibility and performance improvement of the connected architecture.
4/12/2024
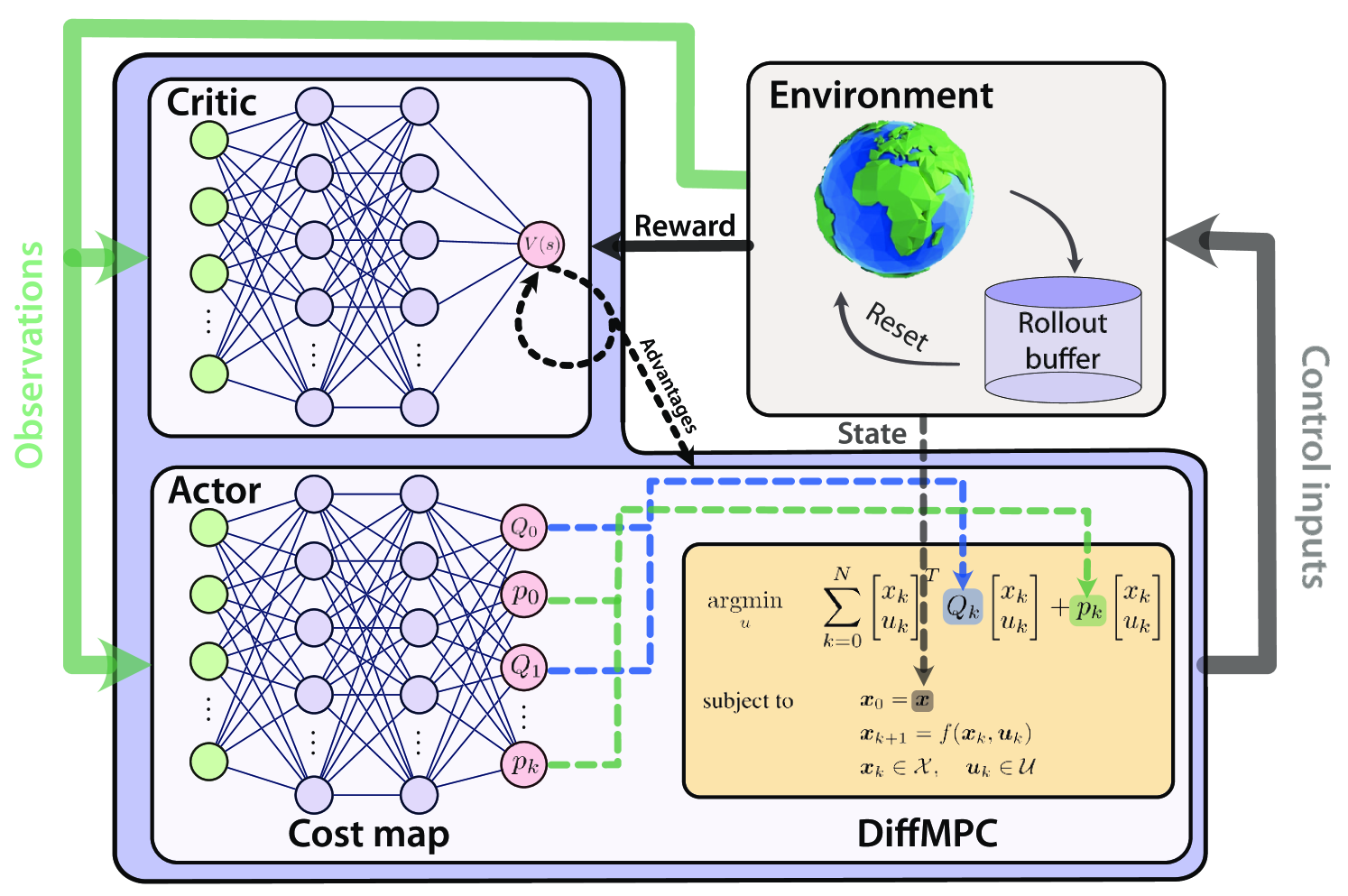
Actor-Critic Model Predictive Control
Angel Romero, Yunlong Song, Davide Scaramuzza
0
0
An open research question in robotics is how to combine the benefits of model-free reinforcement learning (RL) - known for its strong task performance and flexibility in optimizing general reward formulations - with the robustness and online replanning capabilities of model predictive control (MPC). This paper provides an answer by introducing a new framework called Actor-Critic Model Predictive Control. The key idea is to embed a differentiable MPC within an actor-critic RL framework. The proposed approach leverages the short-term predictive optimization capabilities of MPC with the exploratory and end-to-end training properties of RL. The resulting policy effectively manages both short-term decisions through the MPC-based actor and long-term prediction via the critic network, unifying the benefits of both model-based control and end-to-end learning. We validate our method in both simulation and the real world with a quadcopter platform across various high-level tasks. We show that the proposed architecture can achieve real-time control performance, learn complex behaviors via trial and error, and retain the predictive properties of the MPC to better handle out of distribution behaviour.
4/15/2024
📈
Active Learning for Control-Oriented Identification of Nonlinear Systems
Bruce D. Lee, Ingvar Ziemann, George J. Pappas, Nikolai Matni
0
0
Model-based reinforcement learning is an effective approach for controlling an unknown system. It is based on a longstanding pipeline familiar to the control community in which one performs experiments on the environment to collect a dataset, uses the resulting dataset to identify a model of the system, and finally performs control synthesis using the identified model. As interacting with the system may be costly and time consuming, targeted exploration is crucial for developing an effective control-oriented model with minimal experimentation. Motivated by this challenge, recent work has begun to study finite sample data requirements and sample efficient algorithms for the problem of optimal exploration in model-based reinforcement learning. However, existing theory and algorithms are limited to model classes which are linear in the parameters. Our work instead focuses on models with nonlinear parameter dependencies, and presents the first finite sample analysis of an active learning algorithm suitable for a general class of nonlinear dynamics. In certain settings, the excess control cost of our algorithm achieves the optimal rate, up to logarithmic factors. We validate our approach in simulation, showcasing the advantage of active, control-oriented exploration for controlling nonlinear systems.
4/16/2024
Model-Predictive Trajectory Generation for Autonomous Aerial Search and Coverage
Hugo Matias, Daniel Silvestre
0
0
This paper addresses the trajectory planning problem for search and coverage missions with an Unmanned Aerial Vehicle (UAV). The objective is to devise optimal coverage trajectories based on a utility map describing prior region information, assumed to be effectively approximated by a Gaussian Mixture Model (GMM). We introduce a Model Predictive Control (MPC) algorithm employing a relaxed formulation that promotes the exploration of the map by preventing the UAV from revisiting previously covered areas. This is achieved by penalizing intersections between the UAV's visibility regions along its trajectory. The algorithm is assessed in MATLAB and validated in Gazebo, as well as in outdoor experimental tests. The results show that the proposed strategy can generate efficient and smooth trajectories for search and coverage missions.
4/8/2024