ActPrompt: In-Domain Feature Adaptation via Action Cues for Video Temporal Grounding

0

Sign in to get full access
Overview
- This paper introduces ActPrompt, a method for improving video temporal grounding performance by adapting pre-trained visual features to the target domain using action cues.
- The key idea is to leverage action-related information to guide the adaptation process and better transfer knowledge from the source to the target domain.
- The proposed approach outperforms existing state-of-the-art methods on several video temporal grounding benchmarks.
Plain English Explanation
The paper discusses a technique called ActPrompt that helps improve the performance of video temporal grounding, which is the task of identifying the specific time period in a video that corresponds to a given textual description.
The main challenge is that the visual features learned on one dataset (the "source" domain) may not transfer well to a different dataset (the "target" domain) due to domain shift. ActPrompt addresses this by using information about the actions occurring in the video to guide the adaptation of the visual features from the source to the target domain.
The key idea is that by focusing on action-related cues, the adapted visual features will be better equipped to capture the relevant visual information for the temporal grounding task in the target domain. This approach is shown to outperform existing methods on several benchmark datasets, demonstrating its effectiveness.
Technical Explanation
The authors first observe that video temporal grounding models trained on one dataset often struggle to generalize well to other datasets due to the domain shift problem. To address this, they propose ActPrompt, a method that leverages action-related information to adapt the pre-trained visual features to the target domain.
The ActPrompt framework consists of three main components:
- Feature Extraction: A pre-trained visual backbone (e.g., a convolutional neural network) is used to extract visual features from the video frames.
- Action Prompt Adaptation: An action prompt is used to guide the adaptation of the visual features to better capture action-related information in the target domain. This is achieved by training a lightweight adapter module that maps the source domain features to the target domain features.
- Temporal Grounding: The adapted visual features are then used as input to a temporal grounding module that predicts the start and end timestamps of the relevant video segment given the textual query.
The authors demonstrate the effectiveness of ActPrompt on several video temporal grounding benchmarks, where it outperforms existing state-of-the-art methods. The key insight is that by focusing on action-related cues during the feature adaptation process, the model can better transfer knowledge from the source to the target domain, leading to improved performance on the target task.
Critical Analysis
The paper presents a well-designed and effective approach for addressing the domain shift problem in video temporal grounding. The authors' use of action-related information to guide the feature adaptation process is a clever and intuitive idea that seems to pay off in the experimental results.
One potential limitation of the work is that it relies on the availability of action annotations in the target domain, which may not always be the case. It would be interesting to see if the approach could be extended to work with weaker or noisy action information, or to automatically discover relevant action cues from the data.
Additionally, while the paper demonstrates strong performance on the video temporal grounding task, it would be valuable to investigate the generalizability of the ActPrompt approach to other video understanding tasks, such as activity recognition or video question answering. Exploring the transfer learning capabilities of the adapted visual features could further highlight the merits of the proposed technique.
Overall, the ActPrompt method presents a promising direction for addressing domain shift in video-language tasks, and the paper's insights could inspire future research in this area.
Conclusion
This paper introduces ActPrompt, a novel technique for improving video temporal grounding performance by adapting pre-trained visual features to the target domain using action-related information. The key idea is to leverage action cues to guide the feature adaptation process, which helps the model better transfer knowledge from the source to the target domain.
The experimental results show that ActPrompt outperforms existing state-of-the-art methods on several video temporal grounding benchmarks, demonstrating the effectiveness of the proposed approach. This work contributes to the ongoing efforts to develop robust and generalizable video understanding models that can adapt to diverse datasets and tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
ActPrompt: In-Domain Feature Adaptation via Action Cues for Video Temporal Grounding
Yubin Wang, Xinyang Jiang, De Cheng, Dongsheng Li, Cairong Zhao
Video temporal grounding is an emerging topic aiming to identify specific clips within videos. In addition to pre-trained video models, contemporary methods utilize pre-trained vision-language models (VLM) to capture detailed characteristics of diverse scenes and objects from video frames. However, as pre-trained on images, VLM may struggle to distinguish action-sensitive patterns from static objects, making it necessary to adapt them to specific data domains for effective feature representation over temporal grounding. We address two primary challenges to achieve this goal. Specifically, to mitigate high adaptation costs, we propose an efficient preliminary in-domain fine-tuning paradigm for feature adaptation, where downstream-adaptive features are learned through several pretext tasks. Furthermore, to integrate action-sensitive information into VLM, we introduce Action-Cue-Injected Temporal Prompt Learning (ActPrompt), which injects action cues into the image encoder of VLM for better discovering action-sensitive patterns. Extensive experiments demonstrate that ActPrompt is an off-the-shelf training framework that can be effectively applied to various SOTA methods, resulting in notable improvements. The complete code used in this study is provided in the supplementary materials.
Read more8/14/2024

0
Leveraging Temporal Contextualization for Video Action Recognition
Minji Kim, Dongyoon Han, Taekyung Kim, Bohyung Han
We propose a novel framework for video understanding, called Temporally Contextualized CLIP (TC-CLIP), which leverages essential temporal information through global interactions in a spatio-temporal domain within a video. To be specific, we introduce Temporal Contextualization (TC), a layer-wise temporal information infusion mechanism for videos, which 1) extracts core information from each frame, 2) connects relevant information across frames for the summarization into context tokens, and 3) leverages the context tokens for feature encoding. Furthermore, the Video-conditional Prompting (VP) module processes context tokens to generate informative prompts in the text modality. Extensive experiments in zero-shot, few-shot, base-to-novel, and fully-supervised action recognition validate the effectiveness of our model. Ablation studies for TC and VP support our design choices. Our project page with the source code is available at https://github.com/naver-ai/tc-clip
Read more7/25/2024

0
Spatio-Temporal Context Prompting for Zero-Shot Action Detection
Wei-Jhe Huang, Min-Hung Chen, Shang-Hong Lai
Spatio-temporal action detection encompasses the tasks of localizing and classifying individual actions within a video. Recent works aim to enhance this process by incorporating interaction modeling, which captures the relationship between people and their surrounding context. However, these approaches have primarily focused on fully-supervised learning, and the current limitation lies in the lack of generalization capability to recognize unseen action categories. In this paper, we aim to adapt the pretrained image-language models to detect unseen actions. To this end, we propose a method which can effectively leverage the rich knowledge of visual-language models to perform Person-Context Interaction. Meanwhile, our Context Prompting module will utilize contextual information to prompt labels, thereby enhancing the generation of more representative text features. Moreover, to address the challenge of recognizing distinct actions by multiple people at the same timestamp, we design the Interest Token Spotting mechanism which employs pretrained visual knowledge to find each person's interest context tokens, and then these tokens will be used for prompting to generate text features tailored to each individual. To evaluate the ability to detect unseen actions, we propose a comprehensive benchmark on J-HMDB, UCF101-24, and AVA datasets. The experiments show that our method achieves superior results compared to previous approaches and can be further extended to multi-action videos, bringing it closer to real-world applications. The code and data can be found in https://webber2933.github.io/ST-CLIP-project-page.
Read more8/30/2024
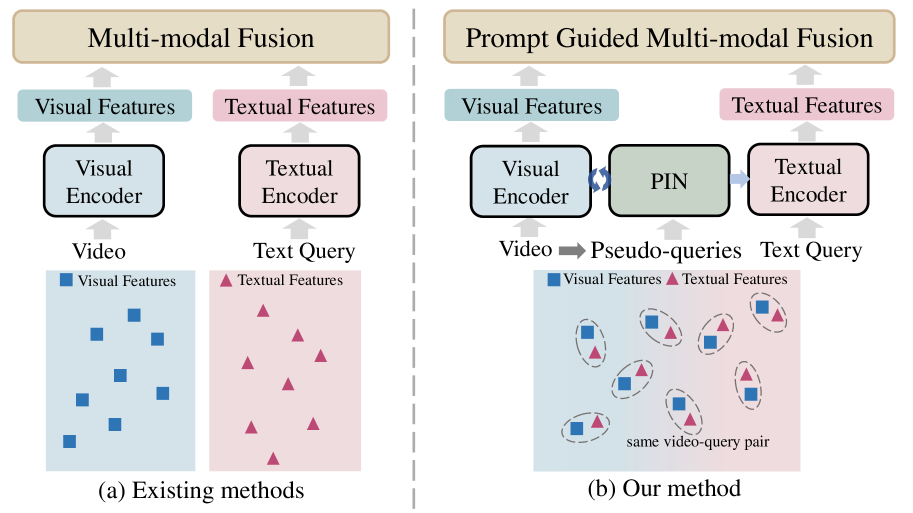
0
Video sentence grounding with temporally global textual knowledge
Cai Chen, Runzhong Zhang, Jianjun Gao, Kejun Wu, Kim-Hui Yap, Yi Wang
Temporal sentence grounding involves the retrieval of a video moment with a natural language query. Many existing works directly incorporate the given video and temporally localized query for temporal grounding, overlooking the inherent domain gap between different modalities. In this paper, we utilize pseudo-query features containing extensive temporally global textual knowledge sourced from the same video-query pair, to enhance the bridging of domain gaps and attain a heightened level of similarity between multi-modal features. Specifically, we propose a Pseudo-query Intermediary Network (PIN) to achieve an improved alignment of visual and comprehensive pseudo-query features within the feature space through contrastive learning. Subsequently, we utilize learnable prompts to encapsulate the knowledge of pseudo-queries, propagating them into the textual encoder and multi-modal fusion module, further enhancing the feature alignment between visual and language for better temporal grounding. Extensive experiments conducted on the Charades-STA and ActivityNet-Captions datasets demonstrate the effectiveness of our method.
Read more6/4/2024