AdaMoE: Token-Adaptive Routing with Null Experts for Mixture-of-Experts Language Models
2406.13233
0
0

Abstract
Mixture of experts (MoE) has become the standard for constructing production-level large language models (LLMs) due to its promise to boost model capacity without causing significant overheads. Nevertheless, existing MoE methods usually enforce a constant top-k routing for all tokens, which is arguably restrictive because various tokens (e.g., vs. apple) may require various numbers of experts for feature abstraction. Lifting such a constraint can help make the most of limited resources and unleash the potential of the model for downstream tasks. In this sense, we introduce AdaMoE to realize token-adaptive routing for MoE, where different tokens are permitted to select a various number of experts. AdaMoE makes minimal modifications to the vanilla MoE with top-k routing -- it simply introduces a fixed number of null experts, which do not consume any FLOPs, to the expert set and increases the value of k. AdaMoE does not force each token to occupy a fixed number of null experts but ensures the average usage of the null experts with a load-balancing loss, leading to an adaptive number of null/true experts used by each token. AdaMoE exhibits a strong resemblance to MoEs with expert choice routing while allowing for trivial auto-regressive modeling. AdaMoE is easy to implement and can be effectively applied to pre-trained (MoE-)LLMs. Extensive studies show that AdaMoE can reduce average expert load (FLOPs) while achieving superior performance. For example, on the ARC-C dataset, applying our method to fine-tuning Mixtral-8x7B can reduce FLOPs by 14.5% while increasing accuracy by 1.69%.
Create account to get full access
Overview
- The paper introduces 𝒜daMoE, a novel Mixture-of-Experts (MoE) language model that uses a token-adaptive routing mechanism with null experts.
- 𝒜daMoE aims to improve the efficiency and performance of large language models by dynamically routing tokens to the most relevant experts.
- The key innovations include a token-adaptive routing method and the use of null experts to handle difficult-to-route tokens.
Plain English Explanation
The paper describes a new type of language model called 𝒜daMoE that is designed to be more efficient and effective than traditional language models. Language models are machine learning models that can generate human-like text and are used in a variety of applications, such as chatbots and text generation.
𝒜daMoE is a Mixture-of-Experts (MoE) model, which means it has multiple specialized "expert" sub-models that each focus on a different aspect of language. The key innovation in 𝒜daMoE is that it uses a "token-adaptive routing" mechanism to dynamically assign each input token (e.g., a word) to the most relevant expert model. This allows the model to better handle the diverse range of language tasks it might encounter.
Additionally, 𝒜daMoE introduces the concept of "null experts," which are expert models that are specifically designed to handle tokens that are difficult to route to the other experts. This helps the model maintain high performance even on challenging language tasks.
The authors of the paper show that 𝒜daMoE outperforms traditional language models on a variety of benchmarks, while also being more efficient and requiring fewer computational resources. This could make 𝒜daMoE a valuable tool for applications that require high-performance language modeling, such as [link to LOCMOE paper] or [link to LOCMOE-Enhanced paper].
Technical Explanation
The paper introduces 𝒜daMoE, a novel Mixture-of-Experts (MoE) language model that uses a token-adaptive routing mechanism with null experts. MoE models are a type of large language model that consists of multiple specialized "expert" sub-models, each of which is responsible for a different aspect of language.
The key innovations in 𝒜daMoE include:
-
Token-Adaptive Routing: Instead of using a fixed routing mechanism, 𝒜daMoE dynamically assigns each input token to the most relevant expert model based on the token's features. This allows the model to better handle the diverse range of language tasks it might encounter.
-
Null Experts: 𝒜daMoE introduces the concept of "null experts," which are expert models that are specifically designed to handle tokens that are difficult to route to the other experts. This helps the model maintain high performance even on challenging language tasks.
The authors evaluate 𝒜daMoE on a variety of language modeling benchmarks and show that it outperforms traditional language models in terms of both performance and efficiency. They also discuss the potential implications of 𝒜daMoE for applications that require high-performance language modeling, such as [link to LOCMOE paper] or [link to LOCMOE-Enhanced paper].
Critical Analysis
The paper presents a well-designed and thorough evaluation of the 𝒜daMoE model, including comparisons to state-of-the-art language models and ablation studies to understand the contributions of the key innovations. The authors also discuss several limitations and potential areas for future research, such as the need for further investigation into the behavior of null experts and the scalability of the token-adaptive routing mechanism.
One aspect that could be explored further is the interpretability of the 𝒜daMoE model. While the token-adaptive routing mechanism is a promising approach, it may be challenging to understand the reasoning behind the model's decisions, particularly for complex language tasks. Providing more insight into the internal workings of 𝒜daMoE could help researchers and practitioners better understand its strengths and limitations.
Additionally, the paper does not address the potential ethical implications of large language models, such as the risk of generating biased or harmful content. As 𝒜daMoE is a powerful language model, it will be important for future research to consider these important societal concerns.
Conclusion
The 𝒜daMoE paper presents a novel Mixture-of-Experts language model that uses a token-adaptive routing mechanism and null experts to improve efficiency and performance. The key innovations, including the dynamic routing and null expert components, have the potential to advance the state of the art in large language models and enable more efficient and effective natural language processing applications.
While the paper provides a thorough technical evaluation, there are opportunities for further research into the interpretability and ethical implications of 𝒜daMoE. Overall, the 𝒜daMoE model represents an interesting and promising development in the field of language modeling that warrants further investigation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

LocMoE+: Enhanced Router with Token Feature Awareness for Efficient LLM Pre-Training
Jing Li, Zhijie Sun, Dachao Lin, Xuan He, Yi Lin, Binfan Zheng, Li Zeng, Rongqian Zhao, Xin Chen
0
0
Mixture-of-Experts (MoE) architectures have recently gained increasing popularity within the domain of large language models (LLMs) due to their ability to significantly reduce training and inference overhead. However, MoE architectures face challenges, such as significant disparities in the number of tokens assigned to each expert and a tendency toward homogenization among experts, which adversely affects the model's semantic generation capabilities. In this paper, we introduce LocMoE+, a refined version of the low-overhead LocMoE, incorporating the following enhancements: (1) Quantification and definition of the affinity between experts and tokens. (2) Implementation of a global-level adaptive routing strategy to rearrange tokens based on their affinity scores. (3) Reestimation of the lower bound for expert capacity, which has been shown to progressively decrease as the token feature distribution evolves. Experimental results demonstrate that, without compromising model convergence or efficacy, the number of tokens each expert processes can be reduced by over 60%. Combined with communication optimizations, this leads to an average improvement in training efficiency ranging from 5.4% to 46.6%. After fine-tuning, LocMoE+ exhibits a performance improvement of 9.7% to 14.1% across the GDAD, C-Eval, and TeleQnA datasets.
6/4/2024
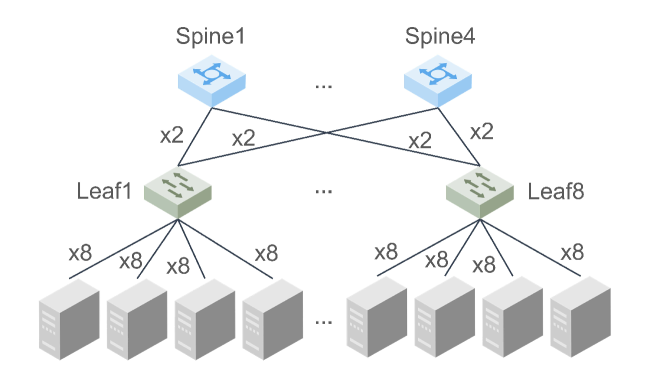
LocMoE: A Low-Overhead MoE for Large Language Model Training
Jing Li, Zhijie Sun, Xuan He, Li Zeng, Yi Lin, Entong Li, Binfan Zheng, Rongqian Zhao, Xin Chen
0
0
The Mixtures-of-Experts (MoE) model is a widespread distributed and integrated learning method for large language models (LLM), which is favored due to its ability to sparsify and expand models efficiently. However, the performance of MoE is limited by load imbalance and high latency of All-to-All communication, along with relatively redundant computation owing to large expert capacity. Load imbalance may result from existing routing policies that consistently tend to select certain experts. The frequent inter-node communication in the All-to-All procedure also significantly prolongs the training time. To alleviate the above performance problems, we propose a novel routing strategy that combines load balance and locality by converting partial inter-node communication to that of intra-node. Notably, we elucidate that there is a minimum threshold for expert capacity, calculated through the maximal angular deviation between the gating weights of the experts and the assigned tokens. We port these modifications on the PanGu-Sigma model based on the MindSpore framework with multi-level routing and conduct experiments on Ascend clusters. The experiment results demonstrate that the proposed LocMoE reduces training time per epoch by 12.68% to 22.24% compared to classical routers, such as hash router and switch router, without impacting the model accuracy.
5/24/2024
👀
Routers in Vision Mixture of Experts: An Empirical Study
Tianlin Liu, Mathieu Blondel, Carlos Riquelme, Joan Puigcerver
0
0
Mixture-of-Experts (MoE) models are a promising way to scale up model capacity without significantly increasing computational cost. A key component of MoEs is the router, which decides which subset of parameters (experts) process which feature embeddings (tokens). In this paper, we present a comprehensive study of routers in MoEs for computer vision tasks. We introduce a unified MoE formulation that subsumes different MoEs with two parametric routing tensors. This formulation covers both sparse MoE, which uses a binary or hard assignment between experts and tokens, and soft MoE, which uses a soft assignment between experts and weighted combinations of tokens. Routers for sparse MoEs can be further grouped into two variants: Token Choice, which matches experts to each token, and Expert Choice, which matches tokens to each expert. We conduct head-to-head experiments with 6 different routers, including existing routers from prior work and new ones we introduce. We show that (i) many routers originally developed for language modeling can be adapted to perform strongly in vision tasks, (ii) in sparse MoE, Expert Choice routers generally outperform Token Choice routers, and (iii) soft MoEs generally outperform sparse MoEs with a fixed compute budget. These results provide new insights regarding the crucial role of routers in vision MoE models.
4/22/2024

MEMoE: Enhancing Model Editing with Mixture of Experts Adaptors
Renzhi Wang, Piji Li
0
0
Model editing aims to efficiently alter the behavior of Large Language Models (LLMs) within a desired scope, while ensuring no adverse impact on other inputs. Recent years have witnessed various model editing methods been proposed. However, these methods either exhibit poor overall performance or struggle to strike a balance between generalization and locality. We propose MEMoE, a model editing adapter utilizing a Mixture of Experts (MoE) architecture with a knowledge anchor routing strategy. MEMoE updates knowledge using a bypass MoE structure, keeping the original parameters unchanged to preserve the general ability of LLMs. And, the knowledge anchor routing ensures that inputs requiring similar knowledge are routed to the same expert, thereby enhancing the generalization of the updated knowledge. Experimental results show the superiority of our approach over both batch editing and sequential batch editing tasks, exhibiting exceptional overall performance alongside outstanding balance between generalization and locality. Our code will be available.
6/4/2024