MEMoE: Enhancing Model Editing with Mixture of Experts Adaptors

0

Sign in to get full access
Overview
- Enhancing Model Editing with Mixture of Experts Adaptors (MEMoE) is a research paper that proposes a new approach to model editing.
- The key idea is to use a "mixture of experts" adaptor to improve the performance of model editing tasks.
- The paper presents experiment results and technical details about the proposed MEMoE approach.
Plain English Explanation
When we have a machine learning model, sometimes we want to make changes or "edit" the model to improve its performance on a specific task. MEMoE: Enhancing Model Editing with Mixture of Experts Adaptors introduces a new way to do this editing that can lead to better results.
The key idea is to use a "mixture of experts" approach. Instead of just having one way to edit the model, the MEMoE method uses a combination of different "experts" - each with their own approach to editing. By blending these different editing techniques, the model can be adjusted more effectively.
The paper shows through experiments that this mixture of experts approach outperforms traditional model editing methods. The technical details explain how the different editing experts are trained and combined to achieve these improvements.
Overall, the MEMoE method provides a new tool for fine-tuning machine learning models to better fit specific tasks or requirements. This type of model editing is an important capability as AI systems become more widely deployed in the real world.
Technical Explanation
The MEMoE paper proposes a new approach to model editing called "Mixture of Experts Adaptors" (MEMoE). Traditional model editing techniques often rely on a single editing mechanism. In contrast, MEMoE uses a mixture of different editing "experts" that are blended together.
The key components of the MEMoE approach are:
-
Editing Experts: These are different neural network modules, each with its own specialized way of editing the base model. The experts could use techniques like adding residual connections, modifying attention patterns, or altering the activation functions.
-
Mixture Adaptor: This module learns how to optimally combine the outputs of the different editing experts to produce the final edited model. It acts as a "gating" mechanism that determines how much each expert should contribute.
-
Training Procedure: The editing experts and mixture adaptor are trained jointly on a set of model editing tasks. This allows the system to learn the most effective ways to blend the experts for different editing scenarios.
The paper demonstrates the effectiveness of MEMoE through experiments on language modeling and image classification tasks. Compared to using a single editing mechanism, the mixture of experts approach was able to achieve better performance on the edited models.
The authors also analyze the behavior of the mixture adaptor module, showing that it learns to intelligently combine the editing experts in a task-dependent manner. This flexibility is a key strength of the MEMoE framework.
Critical Analysis
The MEMoE paper presents a promising new approach to model editing, but there are a few important caveats to consider:
-
Complexity: The MEMoE framework adds significant complexity, with multiple editing experts and a learned mixture adaptor. This could make the system more computationally expensive and harder to train and deploy than simpler editing methods.
-
Interpretability: While the mixture adaptor's ability to blend editing techniques is a strength, it also makes the overall system less interpretable. It may be difficult to understand why the model is making certain editing decisions.
-
Generalization: The paper only evaluates MEMoE on a limited set of tasks. More research is needed to understand how well the approach generalizes to a wider range of model editing scenarios.
-
Editing Constraints: The paper does not address potential constraints on model editing, such as maintaining certain performance guarantees or preserving specific model behaviors. Handling such constraints may require extensions to the basic MEMoE framework.
Despite these caveats, the MEMoE approach represents an interesting and promising direction for enhancing model editing capabilities. Further research to address the limitations could lead to significant improvements in the ability to fine-tune AI systems for specific applications.
Conclusion
The MEMoE: Enhancing Model Editing with Mixture of Experts Adaptors paper introduces a new model editing technique that uses a mixture of specialized editing experts combined by a learned adaptor module. Experiments show this approach can outperform traditional single-mechanism editing methods.
While the MEMoE framework adds complexity, its ability to intelligently blend different editing techniques is a key strength. Further research to address interpretability, generalization, and editing constraints could unlock significant potential for improving the customization and fine-tuning of AI models for real-world applications.
Overall, the MEMoE paper represents an important advance in the field of model editing, providing a new tool for enhancing the performance and capabilities of machine learning systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MEMoE: Enhancing Model Editing with Mixture of Experts Adaptors
Renzhi Wang, Piji Li
Model editing aims to efficiently alter the behavior of Large Language Models (LLMs) within a desired scope, while ensuring no adverse impact on other inputs. Recent years have witnessed various model editing methods been proposed. However, these methods either exhibit poor overall performance or struggle to strike a balance between generalization and locality. We propose MEMoE, a model editing adapter utilizing a Mixture of Experts (MoE) architecture with a knowledge anchor routing strategy. MEMoE updates knowledge using a bypass MoE structure, keeping the original parameters unchanged to preserve the general ability of LLMs. And, the knowledge anchor routing ensures that inputs requiring similar knowledge are routed to the same expert, thereby enhancing the generalization of the updated knowledge. Experimental results show the superiority of our approach over both batch editing and sequential batch editing tasks, exhibiting exceptional overall performance alongside outstanding balance between generalization and locality. Our code will be available.
Read more6/4/2024
0
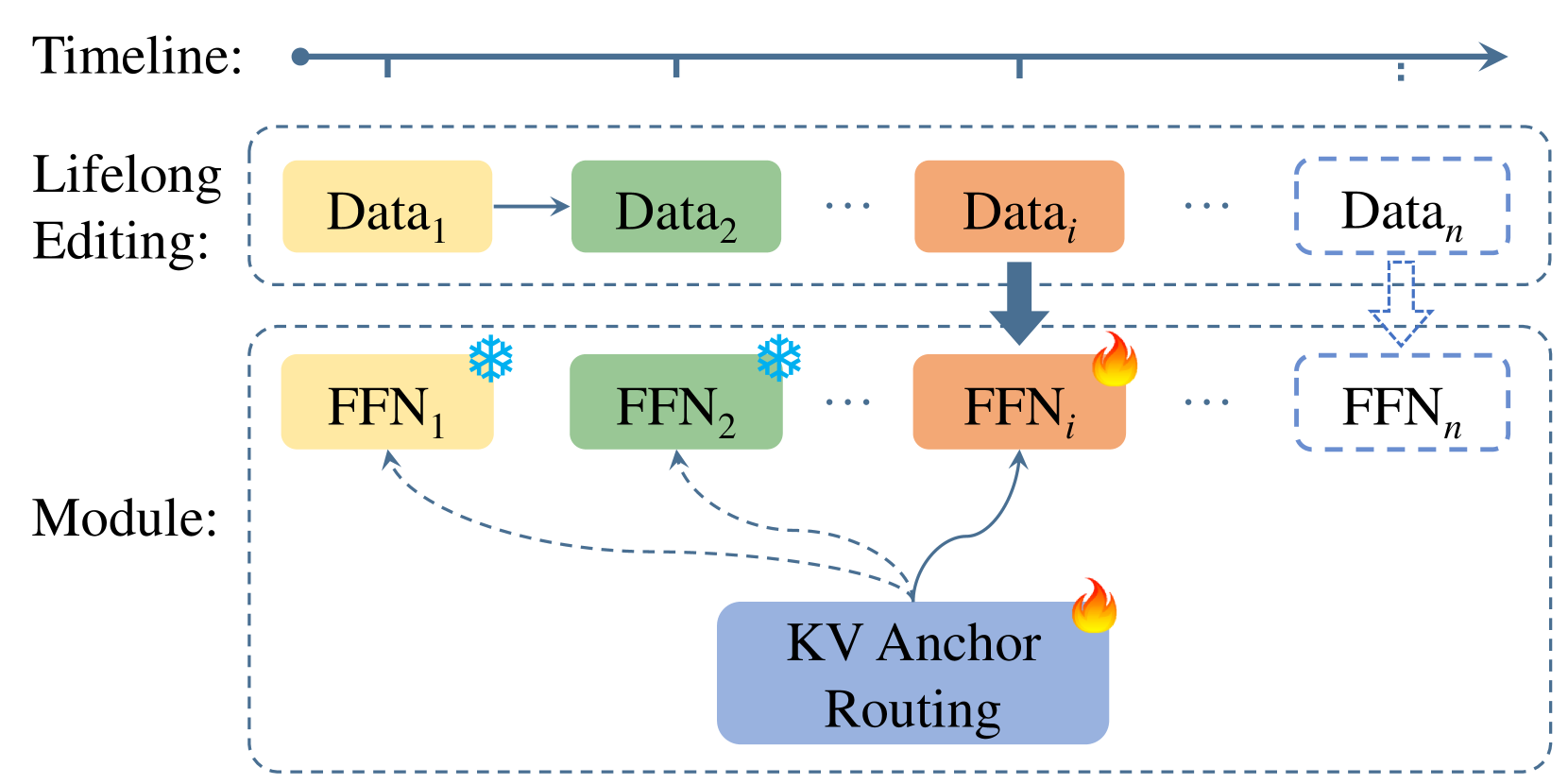
LEMoE: Advanced Mixture of Experts Adaptor for Lifelong Model Editing of Large Language Models
Renzhi Wang, Piji Li
Large language models (LLMs) require continual knowledge updates to stay abreast of the ever-changing world facts, prompting the formulation of lifelong model editing task. While recent years have witnessed the development of various techniques for single and batch editing, these methods either fail to apply or perform sub-optimally when faced with lifelong editing. In this paper, we introduce LEMoE, an advanced Mixture of Experts (MoE) adaptor for lifelong model editing. We first analyze the factors influencing the effectiveness of conventional MoE adaptor in lifelong editing, including catastrophic forgetting, inconsistent routing and order sensitivity. Based on these insights, we propose a tailored module insertion method to achieve lifelong editing, incorporating a novel KV anchor routing to enhance routing consistency between training and inference stage, along with a concise yet effective clustering-based editing order planning. Experimental results demonstrate the effectiveness of our method in lifelong editing, surpassing previous model editing techniques while maintaining outstanding performance in batch editing task. Our code will be available.
Read more7/1/2024

0
A Survey on Mixture of Experts
Weilin Cai, Juyong Jiang, Fan Wang, Jing Tang, Sunghun Kim, Jiayi Huang
Large language models (LLMs) have garnered unprecedented advancements across diverse fields, ranging from natural language processing to computer vision and beyond. The prowess of LLMs is underpinned by their substantial model size, extensive and diverse datasets, and the vast computational power harnessed during training, all of which contribute to the emergent abilities of LLMs (e.g., in-context learning) that are not present in small models. Within this context, the mixture of experts (MoE) has emerged as an effective method for substantially scaling up model capacity with minimal computation overhead, gaining significant attention from academia and industry. Despite its growing prevalence, there lacks a systematic and comprehensive review of the literature on MoE. This survey seeks to bridge that gap, serving as an essential resource for researchers delving into the intricacies of MoE. We first briefly introduce the structure of the MoE layer, followed by proposing a new taxonomy of MoE. Next, we overview the core designs for various MoE models including both algorithmic and systemic aspects, alongside collections of available open-source implementations, hyperparameter configurations and empirical evaluations. Furthermore, we delineate the multifaceted applications of MoE in practice, and outline some potential directions for future research. To facilitate ongoing updates and the sharing of cutting-edge developments in MoE research, we have established a resource repository accessible at https://github.com/withinmiaov/A-Survey-on-Mixture-of-Experts.
Read more7/10/2024
0
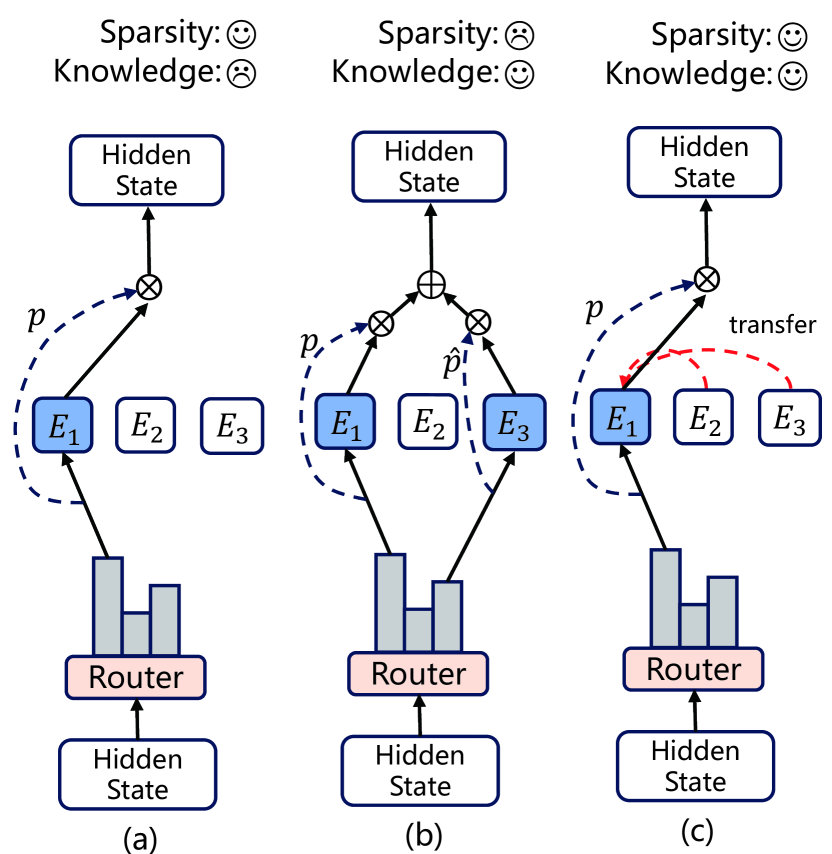
HyperMoE: Towards Better Mixture of Experts via Transferring Among Experts
Hao Zhao, Zihan Qiu, Huijia Wu, Zili Wang, Zhaofeng He, Jie Fu
The Mixture of Experts (MoE) for language models has been proven effective in augmenting the capacity of models by dynamically routing each input token to a specific subset of experts for processing. Despite the success, most existing methods face a challenge for balance between sparsity and the availability of expert knowledge: enhancing performance through increased use of expert knowledge often results in diminishing sparsity during expert selection. To mitigate this contradiction, we propose HyperMoE, a novel MoE framework built upon Hypernetworks. This framework integrates the computational processes of MoE with the concept of knowledge transferring in multi-task learning. Specific modules generated based on the information of unselected experts serve as supplementary information, which allows the knowledge of experts not selected to be used while maintaining selection sparsity. Our comprehensive empirical evaluations across multiple datasets and backbones establish that HyperMoE significantly outperforms existing MoE methods under identical conditions concerning the number of experts.
Read more7/26/2024