AdaNAT: Exploring Adaptive Policy for Token-Based Image Generation

0

Sign in to get full access
Overview
- Explores an Adaptive Neural Network Architecture for Token-Based Image Generation (AdaNAT)
- Leverages reinforcement learning to adaptively adjust the token generation policy during inference
- Aims to improve the efficiency and performance of non-autoregressive Transformer-based image generation models
Plain English Explanation
AdaNAT: Exploring Adaptive Policy for Token-Based Image Generation proposes a novel approach to image generation using non-autoregressive Transformer models. The key idea is to adaptively adjust the token generation policy during the inference process, rather than using a fixed policy.
Traditionally, Transformer-based image generation models use a predefined, static policy to generate tokens sequentially. AdaNAT introduces a reinforcement learning-based technique to dynamically adapt the token generation policy. This allows the model to focus on generating the most informative tokens first, potentially leading to faster and more efficient image synthesis.
The paper demonstrates that AdaNAT can outperform standard non-autoregressive Transformer models in terms of image quality and generation speed, without requiring any additional training data or model capacity.
Technical Explanation
The AdaNAT model is built upon a non-autoregressive Transformer architecture for image generation. Instead of using a fixed token generation policy, the researchers introduce an adaptive policy that is learned through reinforcement learning.
During the inference process, the model's policy network observes the current state of the generation process (e.g., the partially generated image) and decides which token to generate next. A reward function is used to guide the policy network towards generating the most informative tokens first, ultimately leading to faster and higher-quality image synthesis.
The researchers conduct experiments on various image generation benchmarks, including COCO and ImageNet. They compare the performance of AdaNAT against standard non-autoregressive Transformer models, as well as other state-of-the-art image generation approaches.
The results show that AdaNAT can achieve improved image quality and generation speed, demonstrating the benefits of using an adaptive token generation policy.
Critical Analysis
The AdaNAT paper presents a promising approach to improving the efficiency and performance of non-autoregressive Transformer-based image generation models. The use of reinforcement learning to adaptively adjust the token generation policy is a novel and interesting idea.
However, the paper does not address some potential limitations and areas for further research:
-
Stability and Convergence: The reinforcement learning-based policy adaptation may introduce additional complexity and instability during the inference process. The paper could have explored the convergence properties of the adaptive policy and its robustness to different initialization conditions.
-
Computational Overhead: Integrating the reinforcement learning component may increase the computational overhead of the model, which could impact its practical deployment. The paper could have analyzed the trade-offs between the performance gains and the additional computational requirements.
-
Generalization and Transferability: The paper focuses on evaluating AdaNAT on a limited set of image generation benchmarks. Further research could explore the model's ability to generalize to a wider range of image domains and tasks, as well as its transferability to different non-autoregressive Transformer architectures.
-
Interpretability and Explainability: The adaptive policy mechanism in AdaNAT may be difficult to interpret and understand. Providing insights into the decision-making process of the policy network could enhance the model's interpretability and increase trust in its outputs.
Conclusion
The AdaNAT paper presents an innovative approach to improving the efficiency and performance of non-autoregressive Transformer-based image generation models. By leveraging reinforcement learning to adaptively adjust the token generation policy, the model can focus on generating the most informative tokens first, leading to faster and higher-quality image synthesis.
The paper's findings demonstrate the potential benefits of incorporating adaptive mechanisms into token-based image generation models, which could have significant implications for various applications, such as computer vision, content creation, and image-based communication.
While the paper highlights the promise of AdaNAT, further research is needed to address the potential limitations and explore the model's broader applicability and robustness. Nonetheless, the work represents an important step forward in the field of efficient and adaptive image generation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
AdaNAT: Exploring Adaptive Policy for Token-Based Image Generation
Zanlin Ni, Yulin Wang, Renping Zhou, Rui Lu, Jiayi Guo, Jinyi Hu, Zhiyuan Liu, Yuan Yao, Gao Huang
Recent studies have demonstrated the effectiveness of token-based methods for visual content generation. As a representative work, non-autoregressive Transformers (NATs) are able to synthesize images with decent quality in a small number of steps. However, NATs usually necessitate configuring a complicated generation policy comprising multiple manually-designed scheduling rules. These heuristic-driven rules are prone to sub-optimality and come with the requirements of expert knowledge and labor-intensive efforts. Moreover, their one-size-fits-all nature cannot flexibly adapt to the diverse characteristics of each individual sample. To address these issues, we propose AdaNAT, a learnable approach that automatically configures a suitable policy tailored for every sample to be generated. In specific, we formulate the determination of generation policies as a Markov decision process. Under this framework, a lightweight policy network for generation can be learned via reinforcement learning. Importantly, we demonstrate that simple reward designs such as FID or pre-trained reward models, may not reliably guarantee the desired quality or diversity of generated samples. Therefore, we propose an adversarial reward design to guide the training of policy networks effectively. Comprehensive experiments on four benchmark datasets, i.e., ImageNet-256 & 512, MS-COCO, and CC3M, validate the effectiveness of AdaNAT. Code and pre-trained models will be released at https://github.com/LeapLabTHU/AdaNAT.
Read more9/14/2024

0
Revisiting Non-Autoregressive Transformers for Efficient Image Synthesis
Zanlin Ni, Yulin Wang, Renping Zhou, Jiayi Guo, Jinyi Hu, Zhiyuan Liu, Shiji Song, Yuan Yao, Gao Huang
The field of image synthesis is currently flourishing due to the advancements in diffusion models. While diffusion models have been successful, their computational intensity has prompted the pursuit of more efficient alternatives. As a representative work, non-autoregressive Transformers (NATs) have been recognized for their rapid generation. However, a major drawback of these models is their inferior performance compared to diffusion models. In this paper, we aim to re-evaluate the full potential of NATs by revisiting the design of their training and inference strategies. Specifically, we identify the complexities in properly configuring these strategies and indicate the possible sub-optimality in existing heuristic-driven designs. Recognizing this, we propose to go beyond existing methods by directly solving the optimal strategies in an automatic framework. The resulting method, named AutoNAT, advances the performance boundaries of NATs notably, and is able to perform comparably with the latest diffusion models at a significantly reduced inference cost. The effectiveness of AutoNAT is validated on four benchmark datasets, i.e., ImageNet-256 & 512, MS-COCO, and CC3M. Our code is available at https://github.com/LeapLabTHU/ImprovedNAT.
Read more6/11/2024

0
AITTI: Learning Adaptive Inclusive Token for Text-to-Image Generation
Xinyu Hou, Xiaoming Li, Chen Change Loy
Despite the high-quality results of text-to-image generation, stereotypical biases have been spotted in their generated contents, compromising the fairness of generative models. In this work, we propose to learn adaptive inclusive tokens to shift the attribute distribution of the final generative outputs. Unlike existing de-biasing approaches, our method requires neither explicit attribute specification nor prior knowledge of the bias distribution. Specifically, the core of our method is a lightweight adaptive mapping network, which can customize the inclusive tokens for the concepts to be de-biased, making the tokens generalizable to unseen concepts regardless of their original bias distributions. This is achieved by tuning the adaptive mapping network with a handful of balanced and inclusive samples using an anchor loss. Experimental results demonstrate that our method outperforms previous bias mitigation methods without attribute specification while preserving the alignment between generative results and text descriptions. Moreover, our method achieves comparable performance to models that require specific attributes or editing directions for generation. Extensive experiments showcase the effectiveness of our adaptive inclusive tokens in mitigating stereotypical bias in text-to-image generation. The code will be available at https://github.com/itsmag11/AITTI.
Read more6/21/2024
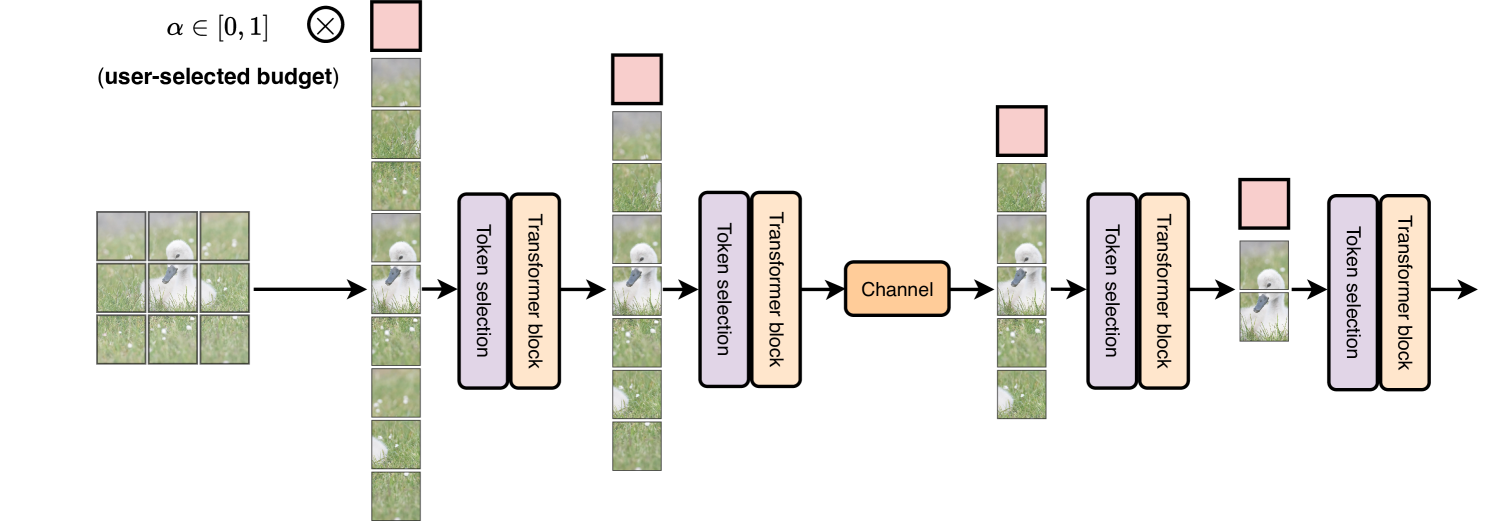
0
Adaptive Semantic Token Selection for AI-native Goal-oriented Communications
Alessio Devoto, Simone Petruzzi, Jary Pomponi, Paolo Di Lorenzo, Simone Scardapane
In this paper, we propose a novel design for AI-native goal-oriented communications, exploiting transformer neural networks under dynamic inference constraints on bandwidth and computation. Transformers have become the standard architecture for pretraining large-scale vision and text models, and preliminary results have shown promising performance also in deep joint source-channel coding (JSCC). Here, we consider a dynamic model where communication happens over a channel with variable latency and bandwidth constraints. Leveraging recent works on conditional computation, we exploit the structure of the transformer blocks and the multihead attention operator to design a trainable semantic token selection mechanism that learns to select relevant tokens (e.g., image patches) from the input signal. This is done dynamically, on a per-input basis, with a rate that can be chosen as an additional input by the user. We show that our model improves over state-of-the-art token selection mechanisms, exhibiting high accuracy for a wide range of latency and bandwidth constraints, without the need for deploying multiple architectures tailored to each constraint. Last, but not least, the proposed token selection mechanism helps extract powerful semantics that are easy to understand and explain, paving the way for interpretable-by-design models for the next generation of AI-native communication systems.
Read more5/7/2024