AdapTable: Test-Time Adaptation for Tabular Data via Shift-Aware Uncertainty Calibrator and Label Distribution Handler

0

Sign in to get full access
Overview
- The paper proposes "AdapTable," a framework for test-time adaptation on tabular data that addresses challenges like dataset shift and label distribution change.
- AdapTable uses a "Shift-Aware Uncertainty Calibrator" to calibrate model uncertainty and a "Label Distribution Handler" to adapt to changes in the label distribution.
- The framework is designed to be general and applicable to a wide range of tabular datasets and models.
Plain English Explanation
When machine learning models are deployed in the real world, the data they encounter may be different from the data they were trained on. This "dataset shift" can cause the model's performance to degrade. Improving Entropy-Based Test-Time Adaptation from Tabular Data and Active Test-Time Adaptation: Theoretical Analyses and Algorithm have explored techniques to adapt models to these shifts.
The AdapTable framework builds on this prior work to address the specific challenges of test-time adaptation for tabular data. Tabular data, which is structured in rows and columns, is common in many business and scientific applications. AdapTable uses two key components to adapt the model:
- Shift-Aware Uncertainty Calibrator: This component calibrates the model's confidence in its predictions, allowing it to recognize when it is uncertain and may need to adapt.
- Label Distribution Handler: This component tracks changes in the distribution of labels (the target variable) in the new data and adjusts the model's predictions accordingly.
By using these two components, AdapTable can effectively adapt a pre-trained model to handle dataset shift and label distribution changes, improving its performance on new, unseen tabular data. This can be especially useful in Evaluation of Test-Time Adaptation under Computational Time and Memory Constraints and Channel-Selective Normalization for Label Shift Robust Test-Time Adaptation scenarios where models need to adapt quickly and efficiently.
Technical Explanation
The AdapTable framework consists of two key components:
-
Shift-Aware Uncertainty Calibrator: This component uses a meta-model to estimate the model's uncertainty on new data. The meta-model is trained to predict the model's calibrated uncertainty based on features of the input data and the model's raw predictions. This allows AdapTable to detect when the model is uncertain and may need to adapt.
-
Label Distribution Handler: This component tracks changes in the label distribution between the training data and the new, test-time data. It then adjusts the model's predictions to match the shifted label distribution, improving the model's performance on the new data.
AdapTable is designed to be general and applicable to a wide range of tabular datasets and models. It can be easily integrated with existing machine learning pipelines, making it a practical solution for real-world deployment scenarios.
The authors evaluate AdapTable on several benchmark tabular datasets and show that it outperforms existing test-time adaptation methods, especially in the presence of significant dataset shift and label distribution changes. The Test-Time Adaptation for Geospatial Point Cloud Semantic Segmentation scenario is an example of how AdapTable can be applied to adapt models to changing data distributions.
Critical Analysis
The authors acknowledge several limitations of the AdapTable framework. First, the performance of the Shift-Aware Uncertainty Calibrator depends on the quality of the meta-model, which may be difficult to train in some cases. Second, the Label Distribution Handler assumes that the label distribution changes in a systematic way, which may not always be the case in real-world scenarios.
Additionally, the authors do not address the computational and memory overhead of the AdapTable framework. While it is designed to be efficient, the added components may still impose a significant burden, especially on resource-constrained devices.
Further research could explore ways to make the uncertainty calibration and label distribution handling more robust and efficient, as well as investigate the applicability of AdapTable to other types of tabular data beyond the benchmarks considered in the paper.
Conclusion
The AdapTable framework provides a promising approach to test-time adaptation for tabular data, addressing key challenges like dataset shift and label distribution changes. By using a Shift-Aware Uncertainty Calibrator and a Label Distribution Handler, AdapTable can effectively adapt pre-trained models to handle these issues, improving their performance on new, unseen data.
While the framework has some limitations, it represents an important step forward in the field of test-time adaptation and could have significant practical applications in real-world machine learning deployments, particularly in Evaluation of Test-Time Adaptation under Computational Time and Memory Constraints scenarios.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
AdapTable: Test-Time Adaptation for Tabular Data via Shift-Aware Uncertainty Calibrator and Label Distribution Handler
Changhun Kim, Taewon Kim, Seungyeon Woo, June Yong Yang, Eunho Yang
In real-world scenarios, tabular data often suffer from distribution shifts that threaten the performance of machine learning models. Despite its prevalence and importance, handling distribution shifts in the tabular domain remains underexplored due to the inherent challenges within the tabular data itself. In this sense, test-time adaptation (TTA) offers a promising solution by adapting models to target data without accessing source data, crucial for privacy-sensitive tabular domains. However, existing TTA methods either 1) overlook the nature of tabular distribution shifts, often involving label distribution shifts, or 2) impose architectural constraints on the model, leading to a lack of applicability. To this end, we propose AdapTable, a novel TTA framework for tabular data. AdapTable operates in two stages: 1) calibrating model predictions using a shift-aware uncertainty calibrator, and 2) adjusting these predictions to match the target label distribution with a label distribution handler. We validate the effectiveness of AdapTable through theoretical analysis and extensive experiments on various distribution shift scenarios. Our results demonstrate AdapTable's ability to handle various real-world distribution shifts, achieving up to a 16% improvement on the HELOC dataset.
Read more8/27/2024
0
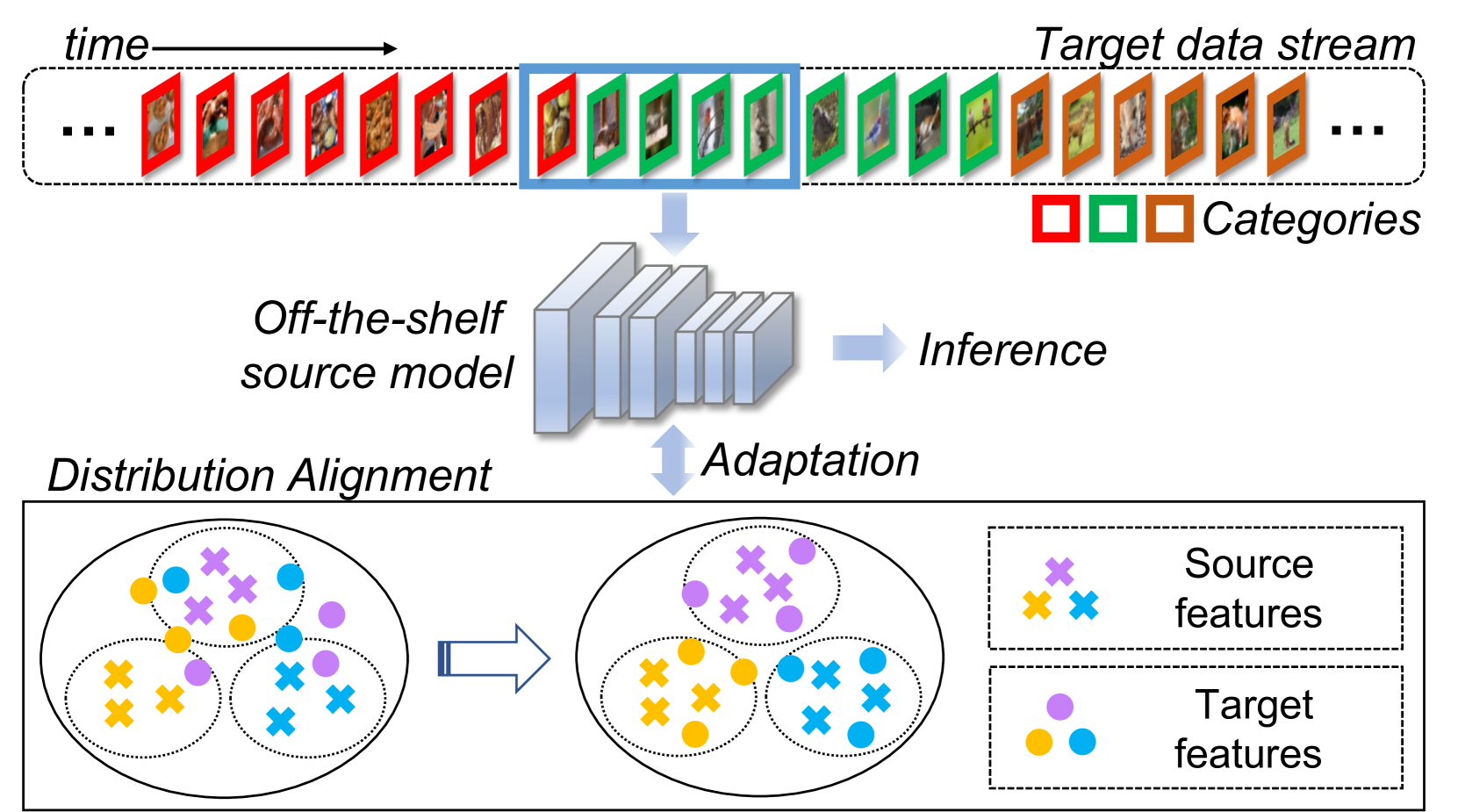
Distribution Alignment for Fully Test-Time Adaptation with Dynamic Online Data Streams
Ziqiang Wang, Zhixiang Chi, Yanan Wu, Li Gu, Zhi Liu, Konstantinos Plataniotis, Yang Wang
Given a model trained on source data, Test-Time Adaptation (TTA) enables adaptation and inference in test data streams with domain shifts from the source. Current methods predominantly optimize the model for each incoming test data batch using self-training loss. While these methods yield commendable results in ideal test data streams, where batches are independently and identically sampled from the target distribution, they falter under more practical test data streams that are not independent and identically distributed (non-i.i.d.). The data batches in a non-i.i.d. stream display prominent label shifts relative to each other. It leads to conflicting optimization objectives among batches during the TTA process. Given the inherent risks of adapting the source model to unpredictable test-time distributions, we reverse the adaptation process and propose a novel Distribution Alignment loss for TTA. This loss guides the distributions of test-time features back towards the source distributions, which ensures compatibility with the well-trained source model and eliminates the pitfalls associated with conflicting optimization objectives. Moreover, we devise a domain shift detection mechanism to extend the success of our proposed TTA method in the continual domain shift scenarios. Our extensive experiments validate the logic and efficacy of our method. On six benchmark datasets, we surpass existing methods in non-i.i.d. scenarios and maintain competitive performance under the ideal i.i.d. assumption.
Read more7/18/2024
🔗
0
Improving Entropy-Based Test-Time Adaptation from a Clustering View
Guoliang Lin, Hanjiang Lai, Yan Pan, Jian Yin
Domain shift is a common problem in the realistic world, where training data and test data follow different data distributions. To deal with this problem, fully test-time adaptation (TTA) leverages the unlabeled data encountered during test time to adapt the model. In particular, entropy-based TTA (EBTTA) methods, which minimize the prediction's entropy on test samples, have shown great success. In this paper, we introduce a new perspective on the EBTTA, which interprets these methods from a view of clustering. It is an iterative algorithm: 1) in the assignment step, the forward process of the EBTTA models is the assignment of labels for these test samples, and 2) in the updating step, the backward process is the update of the model via the assigned samples. Based on the interpretation, we can gain a deeper understanding of EBTTA. Accordingly, we offer an alternative explanation for why existing EBTTA methods are sensitive to initial assignments, nearest neighbor information, outliers, and batch size. This observation can guide us to put forward the improvement of EBTTA. We propose to use robust label assignment, locality-preserving constraint, sample selection, and gradient accumulation to alleviate the above problems. Experimental results demonstrate that our method can achieve consistent improvements on various datasets. Code is provided in the supplementary material.
Read more4/10/2024

0
Active Test-Time Adaptation: Theoretical Analyses and An Algorithm
Shurui Gui, Xiner Li, Shuiwang Ji
Test-time adaptation (TTA) addresses distribution shifts for streaming test data in unsupervised settings. Currently, most TTA methods can only deal with minor shifts and rely heavily on heuristic and empirical studies. To advance TTA under domain shifts, we propose the novel problem setting of active test-time adaptation (ATTA) that integrates active learning within the fully TTA setting. We provide a learning theory analysis, demonstrating that incorporating limited labeled test instances enhances overall performances across test domains with a theoretical guarantee. We also present a sample entropy balancing for implementing ATTA while avoiding catastrophic forgetting (CF). We introduce a simple yet effective ATTA algorithm, known as SimATTA, using real-time sample selection techniques. Extensive experimental results confirm consistency with our theoretical analyses and show that the proposed ATTA method yields substantial performance improvements over TTA methods while maintaining efficiency and shares similar effectiveness to the more demanding active domain adaptation (ADA) methods. Our code is available at https://github.com/divelab/ATTA
Read more4/9/2024