Adaptive Feature Fusion Neural Network for Glaucoma Segmentation on Unseen Fundus Images

0
✨
Sign in to get full access
Overview
- Fundus image segmentation, the process of identifying different parts of eye images, is challenging when working with medical datasets that are small and models that are highly complex.
- To address this, the researchers propose a new method called the Adaptive Feature-fusion Neural Network (AFNN) for glaucoma segmentation on unseen image domains.
- AFNN has three main components: a domain adaptor, a feature-fusion network, and self-supervised multi-task learning.
- The method also includes a weighted dice loss to improve performance on the complex task of optic cup segmentation.
- AFNN outperforms existing fundus segmentation methods on four public glaucoma datasets.
Plain English Explanation
Fundus images are photographs of the back of the eye, and segmenting these images is important for diagnosing conditions like glaucoma. However, this task is very challenging, especially when using complex deep learning models that have been trained on small medical datasets.
The researchers developed a new approach called AFNN to address this problem. AFNN has three key parts. First, it has a "domain adaptor" that helps the pre-trained model quickly adapt from other image domains (like everyday photos) to the specific medical fundus image domain. Second, it uses a "feature-fusion network" and "self-supervised multi-task learning" to improve the model's ability to generalize to new, unseen image domains. Finally, it includes a specialized loss function, called "weighted dice loss," that helps the model better segment the complex optic cup region of the eye.
By combining these innovations, the AFNN method is able to outperform existing fundus segmentation approaches on several public datasets. This is an important advancement, as accurate and generalizable fundus image segmentation can aid in the early detection and monitoring of eye diseases like glaucoma.
Technical Explanation
The core of the proposed AFNN method is its three main modules:
-
Domain Adaptor: This component helps the pre-trained model quickly adapt from other image domains (e.g. natural images) to the target medical fundus image domain. This is crucial, as deep learning models trained on small medical datasets often struggle to generalize.
-
Feature-Fusion Network: This network combines features from different layers of the model's encoder and decoder components. This helps the model learn more robust and generalizable representations.
-
Self-Supervised Multi-Task Learning: The model is trained not only on the primary task of fundus segmentation, but also on auxiliary self-supervised tasks. This encourages the model to learn more meaningful and transferable features.
Additionally, the researchers designed a Weighted Dice Loss function to better optimize the model's performance on the challenging optic cup segmentation task. The optic cup is a small, complex region of the fundus image that is crucial for glaucoma diagnosis.
The researchers evaluated AFNN on four public glaucoma datasets and found that it outperformed existing state-of-the-art fundus segmentation methods. This demonstrates the effectiveness of the proposed domain adaptation, feature-fusion, and multi-task learning approach, as well as the benefits of the specialized loss function.
Critical Analysis
The key strength of this research is its comprehensive approach to addressing the challenging problem of fundus image segmentation on unseen domains. By incorporating domain adaptation, feature fusion, and multi-task learning, the researchers have developed a method that is more robust and generalizable than previous techniques.
However, the paper does not provide much detail on the specific architectural choices and hyperparameter settings used for the AFNN model. Additionally, the evaluation is limited to four public datasets, and it would be helpful to see how the method performs on a wider range of real-world medical data.
Furthermore, the paper does not discuss potential limitations or failure cases of the AFNN approach. It would be valuable to understand the scenarios in which the method might struggle, such as with particularly low-quality or atypical fundus images.
Despite these minor limitations, the AFNN method represents a significant advancement in the field of fundus image segmentation, and the researchers' innovative use of domain adaptation and multi-task learning techniques is a promising direction for future research.
Conclusion
The Adaptive Feature-fusion Neural Network (AFNN) proposed in this paper addresses the critical challenge of fundus image segmentation on unseen medical domains. By leveraging domain adaptation, feature fusion, and self-supervised multi-task learning, the method demonstrates state-of-the-art performance on several public glaucoma datasets.
This work is an important step forward in developing robust and generalizable deep learning models for medical image analysis, which can ultimately aid in the early detection and monitoring of eye diseases like glaucoma. The researchers' innovative approach to combining multiple techniques provides a valuable blueprint for future advancements in this field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
✨
0
Adaptive Feature Fusion Neural Network for Glaucoma Segmentation on Unseen Fundus Images
Jiyuan Zhong, Hu Ke, Ming Yan
Fundus image segmentation on unseen domains is challenging, especially for the over-parameterized deep models trained on the small medical datasets. To address this challenge, we propose a method named Adaptive Feature-fusion Neural Network (AFNN) for glaucoma segmentation on unseen domains, which mainly consists of three modules: domain adaptor, feature-fusion network, and self-supervised multi-task learning. Specifically, the domain adaptor helps the pretrained-model fast adapt from other image domains to the medical fundus image domain. Feature-fusion network and self-supervised multi-task learning for the encoder and decoder are introduced to improve the domain generalization ability. In addition, we also design the weighted-dice-loss to improve model performance on complex optic-cup segmentation tasks. Our proposed method achieves a competitive performance over existing fundus segmentation methods on four public glaucoma datasets.
Read more4/3/2024

0
Graph-Guided Test-Time Adaptation for Glaucoma Diagnosis using Fundus Photography
Qian Zeng, Le Zhang, Yipeng Liu, Ce Zhu, Fan Zhang
Glaucoma is a leading cause of irreversible blindness worldwide. While deep learning approaches using fundus images have largely improved early diagnosis of glaucoma, variations in images from different devices and locations (known as domain shifts) challenge the use of pre-trained models in real-world settings. To address this, we propose a novel Graph-guided Test-Time Adaptation (GTTA) framework to generalize glaucoma diagnosis models to unseen test environments. GTTA integrates the topological information of fundus images into the model training, enhancing the model's transferability and reducing the risk of learning spurious correlation. During inference, GTTA introduces a novel test-time training objective to make the source-trained classifier progressively adapt to target patterns with reliable class conditional estimation and consistency regularization. Experiments on cross-domain glaucoma diagnosis benchmarks demonstrate the superiority of the overall framework and individual components under different backbone networks.
Read more7/11/2024
✨
0
Domain-Adaptive Full-Face Gaze Estimation via Novel-View-Synthesis and Feature Disentanglement
Jiawei Qin, Takuru Shimoyama, Xucong Zhang, Yusuke Sugano
Along with the recent development of deep neural networks, appearance-based gaze estimation has succeeded considerably when training and testing within the same domain. Compared to the within-domain task, the variance of different domains makes the cross-domain performance drop severely, preventing gaze estimation deployment in real-world applications. Among all the factors, ranges of head pose and gaze are believed to play significant roles in the final performance of gaze estimation, while collecting large ranges of data is expensive. This work proposes an effective model training pipeline consisting of a training data synthesis and a gaze estimation model for unsupervised domain adaptation. The proposed data synthesis leverages the single-image 3D reconstruction to expand the range of the head poses from the source domain without requiring a 3D facial shape dataset. To bridge the inevitable gap between synthetic and real images, we further propose an unsupervised domain adaptation method suitable for synthetic full-face data. We propose a disentangling autoencoder network to separate gaze-related features and introduce background augmentation consistency loss to utilize the characteristics of the synthetic source domain. Through comprehensive experiments, it shows that the model using only our synthetic training data can perform comparably to real data extended with a large label range. Our proposed domain adaptation approach further improves the performance on multiple target domains. The code and data will be available at https://github.com/ut-vision/AdaptiveGaze.
Read more7/9/2024
0
Unsupervised Domain Adaptation for Pediatric Brain Tumor Segmentation
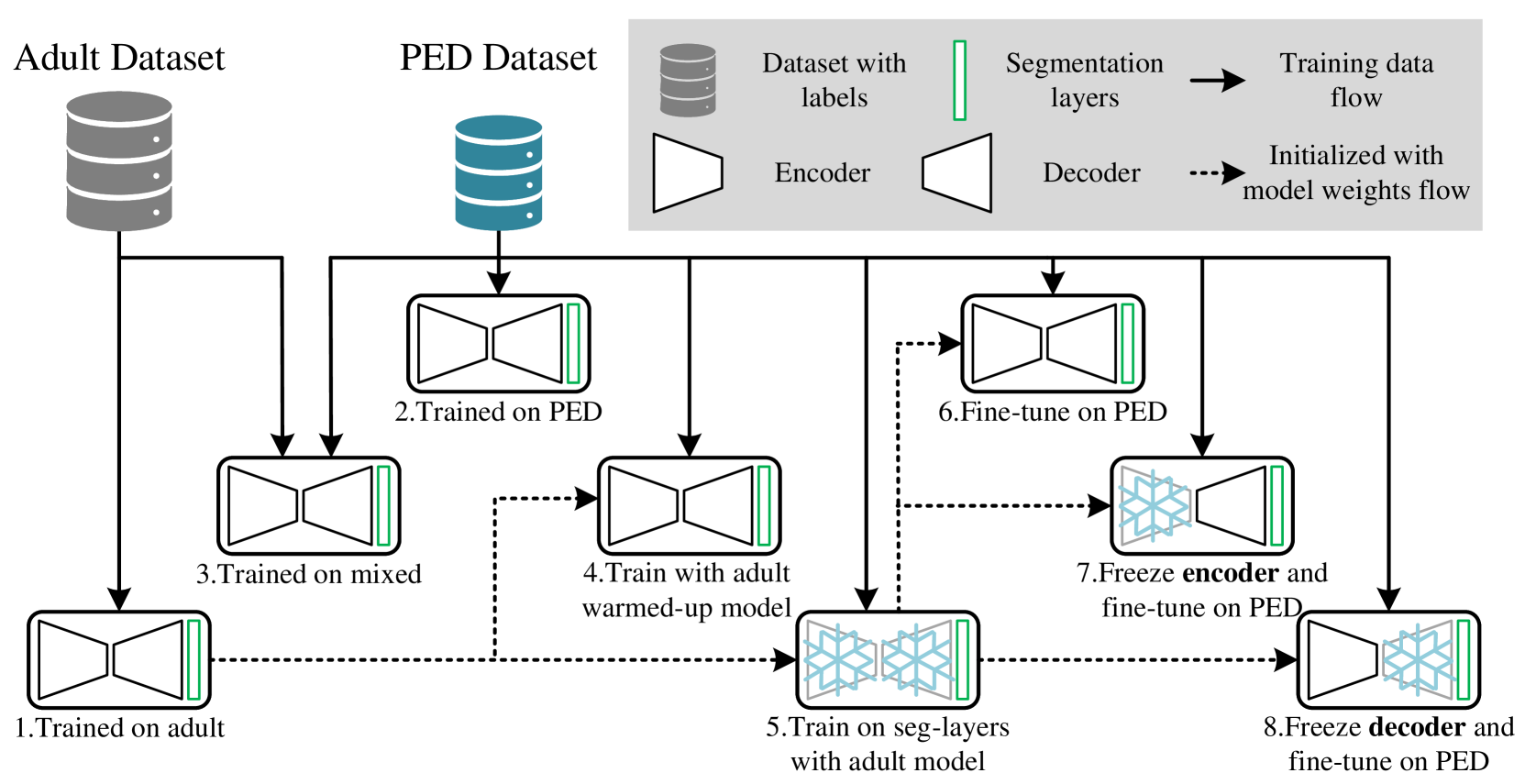
Jingru Fu, Simone Bendazzoli, Orjan Smedby, Rodrigo Moreno
Significant advances have been made toward building accurate automatic segmentation models for adult gliomas. However, the performance of these models often degrades when applied to pediatric glioma due to their imaging and clinical differences (domain shift). Obtaining sufficient annotated data for pediatric glioma is typically difficult because of its rare nature. Also, manual annotations are scarce and expensive. In this work, we propose Domain-Adapted nnU-Net (DA-nnUNet) to perform unsupervised domain adaptation from adult glioma (source domain) to pediatric glioma (target domain). Specifically, we add a domain classifier connected with a gradient reversal layer (GRL) to a backbone nnU-Net. Once the classifier reaches a very high accuracy, the GRL is activated with the goal of transferring domain-invariant features from the classifier to the segmentation model while preserving segmentation accuracy on the source domain. The accuracy of the classifier slowly degrades to chance levels. No annotations are used in the target domain. The method is compared to 8 different supervised models using BraTS-Adult glioma (N=1251) and BraTS-PED glioma data (N=99). The proposed method shows notable performance enhancements in the tumor core (TC) region compared to the model that only uses adult data: ~32% better Dice scores and ~20 better 95th percentile Hausdorff distances. Moreover, our unsupervised approach shows no statistically significant difference compared to the practical upper bound model using manual annotations from both datasets in TC region. The code is shared at https://github.com/Fjr9516/DA_nnUNet.
Read more6/26/2024