Adaptive Layer Splitting for Wireless LLM Inference in Edge Computing: A Model-Based Reinforcement Learning Approach

0
Sign in to get full access
Overview
- This paper proposes an adaptive layer splitting approach for efficient inference of large language models (LLMs) on edge computing devices over wireless networks.
- It uses a model-based reinforcement learning (RL) algorithm to dynamically determine the optimal layer-splitting strategy based on factors like network conditions, device capabilities, and latency requirements.
- The goal is to improve the overall inference performance and energy efficiency of LLM deployment on resource-constrained edge devices.
Plain English Explanation
The paper explores a way to run complex AI language models efficiently on edge devices like smartphones or IoT sensors, which often have limited computing power and connectivity. Modern large language models (LLMs) are very powerful but also very computationally intensive, making it challenging to use them on small devices.
The key idea is to "split" the language model across the edge device and a more powerful server in the cloud or at the network edge. The device handles some of the easier parts of the model, while the server does the heavy lifting. An adaptive reinforcement learning algorithm dynamically adjusts how the model is split based on factors like the device's capabilities, network conditions, and the user's needs. This allows the system to optimize performance and energy use.
For example, if the device has low battery and the network is slow, the model might be split so more work is done in the cloud. But if the device is powerful and the network is fast, more of the model could run locally to minimize latency. The goal is to get the best possible results from the language model while respecting the constraints of edge devices and wireless networks.
Technical Explanation
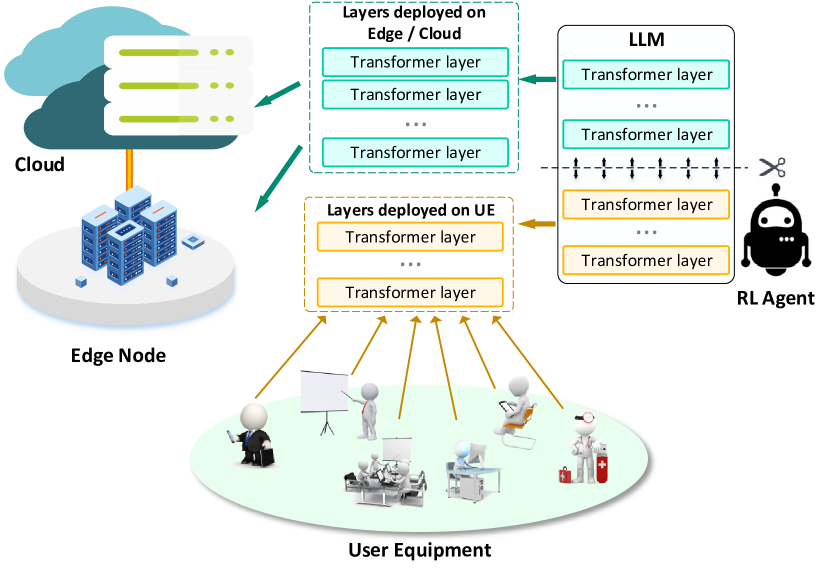
The paper presents an adaptive layer-splitting approach for efficient inference of large language models (LLMs) on resource-constrained edge devices connected over wireless networks. The key technical components are:
-
Layer Splitting: The LLM is partitioned into multiple layers, with some layers executed on the edge device and the remaining layers executed on a more powerful server.
-
Model-Based Reinforcement Learning: A model-based RL algorithm is used to dynamically determine the optimal layer-splitting strategy. The RL agent learns a predictive model of the environment (e.g., device capabilities, network conditions, latency requirements) and uses this to select the best layer-splitting configuration.
-
Adaptive Optimization: The layer-splitting strategy is continuously adapted based on changes in the environment, with the goal of optimizing inference performance and energy efficiency on the edge device.
The paper evaluates this approach using simulations and real-world experiments, comparing it to alternative edge-cloud collaboration techniques and distributed inference strategies. The results demonstrate significant improvements in latency, throughput, and energy consumption for LLM inference on edge devices.
Critical Analysis
The paper presents a well-designed and thoroughly evaluated approach for adaptive layer splitting of LLMs in edge computing environments. However, a few potential limitations and areas for further research are worth noting:
-
Generalizability: The experiments were conducted on a specific LLM (GPT-2) and a limited set of edge devices and network conditions. More research is needed to assess the generalizability of the approach to a wider range of LLMs, hardware, and deployment scenarios.
-
Practical Deployment: While the simulations and experiments demonstrate the potential benefits, the paper does not address some of the practical challenges of deploying such a system in real-world edge computing environments, such as the overhead of model partitioning, synchronization, and distributed execution.
-
Security and Privacy: The paper does not discuss the potential security and privacy implications of splitting and distributing LLM inference across edge devices and servers. Careful consideration of these aspects would be important for the practical adoption of such techniques.
-
Ethical Considerations: As large language models become more widely deployed, it is crucial to address the potential societal and ethical implications, such as the risk of biased or harmful outputs, and ensure that these systems are developed and used responsibly.
Conclusion
This paper presents a novel adaptive layer-splitting approach for efficiently running large language models on resource-constrained edge devices connected over wireless networks. By dynamically adjusting the model partitioning based on a reinforcement learning algorithm, the system can optimize for latency, throughput, and energy consumption, making it a promising solution for deploying advanced AI capabilities at the network edge. While the research shows strong technical merits, further work is needed to address practical deployment challenges and consider the broader societal implications of this technology.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Adaptive Layer Splitting for Wireless LLM Inference in Edge Computing: A Model-Based Reinforcement Learning Approach
Yuxuan Chen, Rongpeng Li, Xiaoxue Yu, Zhifeng Zhao, Honggang Zhang
Optimizing the deployment of large language models (LLMs) in edge computing environments is critical for enhancing privacy and computational efficiency. Toward efficient wireless LLM inference in edge computing, this study comprehensively analyzes the impact of different splitting points in mainstream open-source LLMs. On this basis, this study introduces a framework taking inspiration from model-based reinforcement learning (MBRL) to determine the optimal splitting point across the edge and user equipment (UE). By incorporating a reward surrogate model, our approach significantly reduces the computational cost of frequent performance evaluations. Extensive simulations demonstrate that this method effectively balances inference performance and computational load under varying network conditions, providing a robust solution for LLM deployment in decentralized settings.
Read more9/12/2024
🤯
0
EdgeShard: Efficient LLM Inference via Collaborative Edge Computing
Mingjin Zhang, Jiannong Cao, Xiaoming Shen, Zeyang Cui
Large language models (LLMs) have shown great potential in natural language processing and content generation. However, current LLMs heavily rely on cloud computing, leading to prolonged latency, high bandwidth cost, and privacy concerns. Edge computing is promising to address such concerns by deploying LLMs on edge devices, closer to data sources. Some works try to leverage model quantization to reduce the model size to fit the resource-constraint edge devices, but they lead to accuracy loss. Other works use cloud-edge collaboration, suffering from unstable network connections. In this work, we leverage collaborative edge computing to facilitate the collaboration among edge devices and cloud servers for jointly performing efficient LLM inference. We propose a general framework to partition the LLM model into shards and deploy on distributed devices. To achieve efficient LLM inference, we formulate an adaptive joint device selection and model partition problem and design an efficient dynamic programming algorithm to optimize the inference latency and throughput, respectively. Experiments of Llama2 serial models on a heterogeneous physical prototype demonstrate that EdgeShard achieves up to 50% latency reduction and 2x throughput improvement over baseline methods.
Read more5/24/2024
💬
0
Large Language Models (LLMs) Assisted Wireless Network Deployment in Urban Settings
Nurullah Sevim, Mostafa Ibrahim, Sabit Ekin
The advent of Large Language Models (LLMs) has revolutionized language understanding and human-like text generation, drawing interest from many other fields with this question in mind: What else are the LLMs capable of? Despite their widespread adoption, ongoing research continues to explore new ways to integrate LLMs into diverse systems. This paper explores new techniques to harness the power of LLMs for 6G (6th Generation) wireless communication technologies, a domain where automation and intelligent systems are pivotal. The inherent adaptability of LLMs to domain-specific tasks positions them as prime candidates for enhancing wireless systems in the 6G landscape. We introduce a novel Reinforcement Learning (RL) based framework that leverages LLMs for network deployment in wireless communications. Our approach involves training an RL agent, utilizing LLMs as its core, in an urban setting to maximize coverage. The agent's objective is to navigate the complexities of urban environments and identify the network parameters for optimal area coverage. Additionally, we integrate LLMs with Convolutional Neural Networks (CNNs) to capitalize on their strengths while mitigating their limitations. The Deep Deterministic Policy Gradient (DDPG) algorithm is employed for training purposes. The results suggest that LLM-assisted models can outperform CNN-based models in some cases while performing at least as well in others.
Read more8/12/2024
💬
0
Distributed Threat Intelligence at the Edge Devices: A Large Language Model-Driven Approach
Syed Mhamudul Hasan, Alaa M. Alotaibi, Sajedul Talukder, Abdur R. Shahid
With the proliferation of edge devices, there is a significant increase in attack surface on these devices. The decentralized deployment of threat intelligence on edge devices, coupled with adaptive machine learning techniques such as the in-context learning feature of Large Language Models (LLMs), represents a promising paradigm for enhancing cybersecurity on resource-constrained edge devices. This approach involves the deployment of lightweight machine learning models directly onto edge devices to analyze local data streams, such as network traffic and system logs, in real-time. Additionally, distributing computational tasks to an edge server reduces latency and improves responsiveness while also enhancing privacy by processing sensitive data locally. LLM servers can enable these edge servers to autonomously adapt to evolving threats and attack patterns, continuously updating their models to improve detection accuracy and reduce false positives. Furthermore, collaborative learning mechanisms facilitate peer-to-peer secure and trustworthy knowledge sharing among edge devices, enhancing the collective intelligence of the network and enabling dynamic threat mitigation measures such as device quarantine in response to detected anomalies. The scalability and flexibility of this approach make it well-suited for diverse and evolving network environments, as edge devices only send suspicious information such as network traffic and system log changes, offering a resilient and efficient solution to combat emerging cyber threats at the network edge. Thus, our proposed framework can improve edge computing security by providing better security in cyber threat detection and mitigation by isolating the edge devices from the network.
Read more5/28/2024