Adaptive Utilization of Cross-scenario Information for Multi-scenario Recommendation

0

Sign in to get full access
Overview
- This paper proposes a novel model for multi-scenario recommendation that adaptively utilizes cross-scenario information.
- The model aims to improve recommendation performance by effectively leveraging knowledge gained from different user scenarios.
- Key contributions include a cross-scenario information interaction module and an adaptive information utilization mechanism.
Plain English Explanation
In today's world, users often engage with services and products across various scenarios, such as e-commerce, social media, and entertainment platforms. Recommender systems play a crucial role in these scenarios, helping users discover relevant content and items.
However, traditional recommender systems often treat each scenario in isolation, missing out on valuable insights that could be gained by considering a user's behavior and preferences across different scenarios. This paper introduces a new approach that seeks to bridge this gap.
The researchers have developed a multi-scenario recommendation model that can adaptively utilize information from various user scenarios. The key idea is to create a "cross-scenario information interaction module" that can effectively capture and leverage the relationships between a user's behaviors and preferences across different scenarios.
For example, if a user frequently purchases outdoor gear on an e-commerce platform, the model might infer that they have an interest in outdoor activities. This information could then be used to make better recommendations for related content or products on a separate entertainment platform, where the user might be interested in hiking or camping videos.
By adaptively incorporating this cross-scenario information, the model aims to provide more personalized and relevant recommendations to users, ultimately improving their overall experience and satisfaction.
Technical Explanation
The proposed cross-scenario information interaction model consists of several key components:
-
Cross-scenario information interaction module: This module is designed to capture the relationships between a user's behaviors and preferences across different scenarios. It learns to extract and fuse relevant information from multiple scenarios, enabling the model to make more informed recommendations.
-
Adaptive information utilization mechanism: This mechanism allows the model to dynamically adjust the relative importance of cross-scenario information based on the specific recommendation task and user context. This helps the model to strike a balance between leveraging cross-scenario insights and focusing on the most relevant information for a given scenario.
The researchers evaluate their model on several real-world multi-scenario recommendation datasets, demonstrating its superior performance compared to traditional methods. The results indicate that the adaptive utilization of cross-scenario information can significantly enhance the accuracy and relevance of recommendations across a variety of scenarios.
Critical Analysis
One potential limitation of this research is the reliance on the availability of diverse user data across multiple scenarios. In practice, users may not always engage with a wide range of services, which could limit the model's ability to effectively leverage cross-scenario information. Additionally, the paper does not address potential privacy concerns or data sharing challenges that may arise when aggregating user data from different sources.
Further research could explore techniques to address these challenges, such as developing privacy-preserving methods for cross-scenario information exchange or investigating ways to improve the model's performance with limited cross-scenario data. Incorporating user feedback and preferences regarding the use of their data would also be an important consideration for real-world deployment.
Conclusion
This paper presents a novel multi-scenario recommendation model that adaptively utilizes cross-scenario information to improve recommendation performance. By capturing the relationships between user behaviors and preferences across different scenarios, the model can provide more personalized and relevant recommendations, enhancing the overall user experience.
The proposed approach represents a significant step forward in the field of recommender systems, highlighting the potential benefits of leveraging cross-scenario insights. As users engage with an increasingly diverse range of digital services, this research underscores the importance of developing intelligent systems that can effectively harness the wealth of user data to deliver personalized and valuable recommendations.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Adaptive Utilization of Cross-scenario Information for Multi-scenario Recommendation
Xiufeng Shu, Ruidong Han, Xiang Li, Wei Lin
Recommender system of the e-commerce platform usually serves multiple business scenarios. Multi-scenario Recommendation (MSR) is an important topic that improves ranking performance by leveraging information from different scenarios. Recent methods for MSR mostly construct scenario shared or specific modules to model commonalities and differences among scenarios. However, when the amount of data among scenarios is skewed or data in some scenarios is extremely sparse, it is difficult to learn scenario-specific parameters well. Besides, simple sharing of information from other scenarios may result in a negative transfer. In this paper, we propose a unified model named Cross-Scenario Information Interaction (CSII) to serve all scenarios by a mixture of scenario-dominated experts. Specifically, we propose a novel method to select highly transferable features in data instances. Then, we propose an attention-based aggregator module, which can adaptively extract relative knowledge from cross-scenario. Experiments on the production dataset verify the superiority of our method. Online A/B test in Meituan Waimai APP also shows a significant performance gain, leading to an average improvement in GMV (Gross Merchandise Value) of 1.0% for overall scenarios.
Read more7/30/2024

0
LLM4MSR: An LLM-Enhanced Paradigm for Multi-Scenario Recommendation
Yuhao Wang, Yichao Wang, Zichuan Fu, Xiangyang Li, Xiangyu Zhao, Huifeng Guo, Ruiming Tang
As the demand for more personalized recommendation grows and a dramatic boom in commercial scenarios arises, the study on multi-scenario recommendation (MSR) has attracted much attention, which uses the data from all scenarios to simultaneously improve their recommendation performance. However, existing methods tend to integrate insufficient scenario knowledge and neglect learning personalized cross-scenario preferences, thus leading to suboptimal performance and inadequate interpretability. Meanwhile, though large language model (LLM) has shown great capability of reasoning and capturing semantic information, the high inference latency and high computation cost of tuning hinder its implementation in industrial recommender systems. To fill these gaps, we propose an effective efficient interpretable LLM-enhanced paradigm LLM4MSR in this work. Specifically, we first leverage LLM to uncover multi-level knowledge including scenario correlations and users' cross-scenario interests from the designed scenario- and user-level prompt without fine-tuning the LLM, then adopt hierarchical meta networks to generate multi-level meta layers to explicitly improves the scenario-aware and personalized recommendation capability. Our experiments on KuaiSAR-small, KuaiSAR, and Amazon datasets validate two significant advantages of LLM4MSR: (i) the effectiveness and compatibility with different multi-scenario backbone models (achieving 1.5%, 1%, and 40% AUC improvement on three datasets), (ii) high efficiency and deployability on industrial recommender systems, and (iii) improved interpretability. The implemented code and data is available to ease reproduction.
Read more6/19/2024

0
A Unified Search and Recommendation Framework Based on Multi-Scenario Learning for Ranking in E-commerce
Jinhan Liu, Qiyu Chen, Junjie Xu, Junjie Li, Baoli Li, Sulong Xu
Search and recommendation (S&R) are the two most important scenarios in e-commerce. The majority of users typically interact with products in S&R scenarios, indicating the need and potential for joint modeling. Traditional multi-scenario models use shared parameters to learn the similarity of multiple tasks, and task-specific parameters to learn the divergence of individual tasks. This coarse-grained modeling approach does not effectively capture the differences between S&R scenarios. Furthermore, this approach does not sufficiently exploit the information across the global label space. These issues can result in the suboptimal performance of multi-scenario models in handling both S&R scenarios. To address these issues, we propose an effective and universal framework for Unified Search and Recommendation (USR), designed with S&R Views User Interest Extractor Layer (IE) and S&R Views Feature Generator Layer (FG) to separately generate user interests and scenario-agnostic feature representations for S&R. Next, we introduce a Global Label Space Multi-Task Layer (GLMT) that uses global labels as supervised signals of auxiliary tasks and jointly models the main task and auxiliary tasks using conditional probability. Extensive experimental evaluations on real-world industrial datasets show that USR can be applied to various multi-scenario models and significantly improve their performance. Online A/B testing also indicates substantial performance gains across multiple metrics. Currently, USR has been successfully deployed in the 7Fresh App.
Read more6/13/2024
0
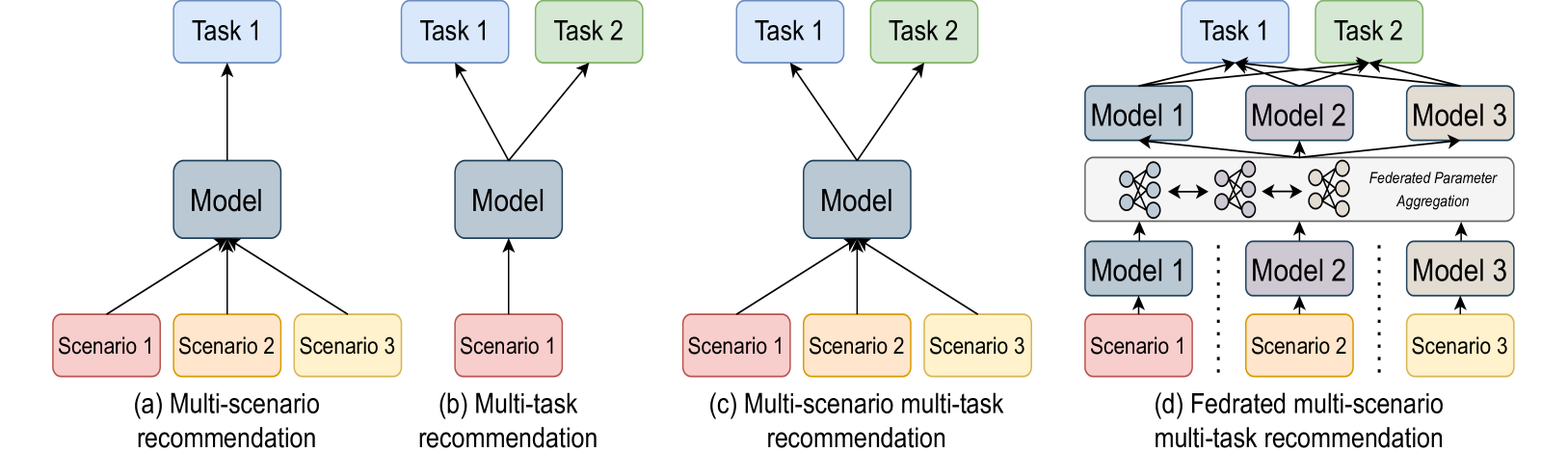
Towards Personalized Federated Multi-scenario Multi-task Recommendation
Yue Ding, Yanbiao Ji, Xun Cai, Xin Xin, Yuxiang Lu, Suizhi Huang, Chang Liu, Xiaofeng Gao, Tsuyoshi Murata, Hongtao Lu
In modern recommender systems, especially in e-commerce, predicting multiple targets such as click-through rate (CTR) and post-view conversion rate (CTCVR) is common. Multi-task recommender systems are increasingly popular in both research and practice, as they leverage shared knowledge across diverse business scenarios to enhance performance. However, emerging real-world scenarios and data privacy concerns complicate the development of a unified multi-task recommendation model. In this paper, we propose PF-MSMTrec, a novel framework for personalized federated multi-scenario multi-task recommendation. In this framework, each scenario is assigned to a dedicated client utilizing the Multi-gate Mixture-of-Experts (MMoE) structure. To address the unique challenges of multiple optimization conflicts, we introduce a bottom-up joint learning mechanism. First, we design a parameter template to decouple the expert network parameters, distinguishing scenario-specific parameters as shared knowledge for federated parameter aggregation. Second, we implement personalized federated learning for each expert network during a federated communication round, using three modules: federated batch normalization, conflict coordination, and personalized aggregation. Finally, we conduct an additional round of personalized federated parameter aggregation on the task tower network to obtain prediction results for multiple tasks. Extensive experiments on two public datasets demonstrate that our proposed method outperforms state-of-the-art approaches. The source code and datasets will be released as open-source for public access.
Read more8/21/2024