Addressing Heterogeneity in Federated Learning: Challenges and Solutions for a Shared Production Environment

0

Sign in to get full access
Overview
- Federated learning enables machine learning on distributed data, but heterogeneity in the data and devices can hinder performance.
- This paper explores challenges posed by heterogeneity in federated learning and proposes solutions to address them in a shared production environment.
Plain English Explanation
Federated learning is a way of training machine learning models without centralizing all the training data. Instead, the data stays on individual devices, and the model is trained across these distributed devices. This can be very helpful when data privacy is a concern.
However, the devices and data used in federated learning can be quite different from one another. This heterogeneity can create problems for the training process and final model performance. For example, some devices may have much more powerful hardware than others, or the data on different devices may have very different statistical properties.
This paper looks at the challenges that this heterogeneity poses in a real-world, shared production environment. It then proposes several solutions to address these challenges and improve the performance of federated learning systems in the face of heterogeneity.
Technical Explanation
The paper begins by reviewing the state-of-the-art in federated learning, highlighting how heterogeneity in data and devices can degrade model performance. It then outlines the key challenges that arise in a shared production environment, including:
- Device Heterogeneity: Differences in hardware capabilities, network connectivity, and availability across devices.
- Data Heterogeneity: Variations in the statistical properties, volume, and class distributions of data on different devices.
- System Heterogeneity: Diverse software environments, system configurations, and resource constraints on devices.
To address these challenges, the paper proposes several novel techniques:
- Adaptive Model Personalization: Customizing the global model to individual devices based on their data and resources.
- Federated Distillation: Transferring knowledge from stronger to weaker devices to mitigate performance gaps.
- Federated Meta-Learning: Learning how to quickly adapt the global model to local device characteristics.
The authors evaluate these solutions on real-world industrial datasets and demonstrate significant performance improvements over baseline federated learning approaches.
Critical Analysis
The paper provides a comprehensive and insightful analysis of the heterogeneity challenges facing federated learning in production environments. The proposed solutions, such as adaptive model personalization and federated distillation, appear well-designed to address these challenges.
However, the paper does not discuss the potential computational or communication overhead introduced by these techniques. There may be trade-offs between the performance gains and the additional complexity required to implement these solutions.
Additionally, the evaluation is limited to a few specific industrial datasets. It would be valuable to see how these methods perform across a wider range of federated learning scenarios, including those with more extreme levels of heterogeneity.
Conclusion
This paper makes an important contribution by highlighting the critical role of heterogeneity in federated learning and proposing practical solutions to address it. The techniques described, such as federated meta-learning, could help enable the widespread adoption of federated learning in real-world, shared production environments. Further research is needed to fully understand the trade-offs and generalize the findings to a broader range of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Addressing Heterogeneity in Federated Learning: Challenges and Solutions for a Shared Production Environment
Tatjana Legler, Vinit Hegiste, Ahmed Anwar, Martin Ruskowski
Federated learning (FL) has emerged as a promising approach to training machine learning models across decentralized data sources while preserving data privacy, particularly in manufacturing and shared production environments. However, the presence of data heterogeneity variations in data distribution, quality, and volume across different or clients and production sites, poses significant challenges to the effectiveness and efficiency of FL. This paper provides a comprehensive overview of heterogeneity in FL within the context of manufacturing, detailing the types and sources of heterogeneity, including non-independent and identically distributed (non-IID) data, unbalanced data, variable data quality, and statistical heterogeneity. We discuss the impact of these types of heterogeneity on model training and review current methodologies for mitigating their adverse effects. These methodologies include personalized and customized models, robust aggregation techniques, and client selection techniques. By synthesizing existing research and proposing new strategies, this paper aims to provide insight for effectively managing data heterogeneity in FL, enhancing model robustness, and ensuring fair and efficient training across diverse environments. Future research directions are also identified, highlighting the need for adaptive and scalable solutions to further improve the FL paradigm in the context of Industry 4.0.
Read more8/20/2024
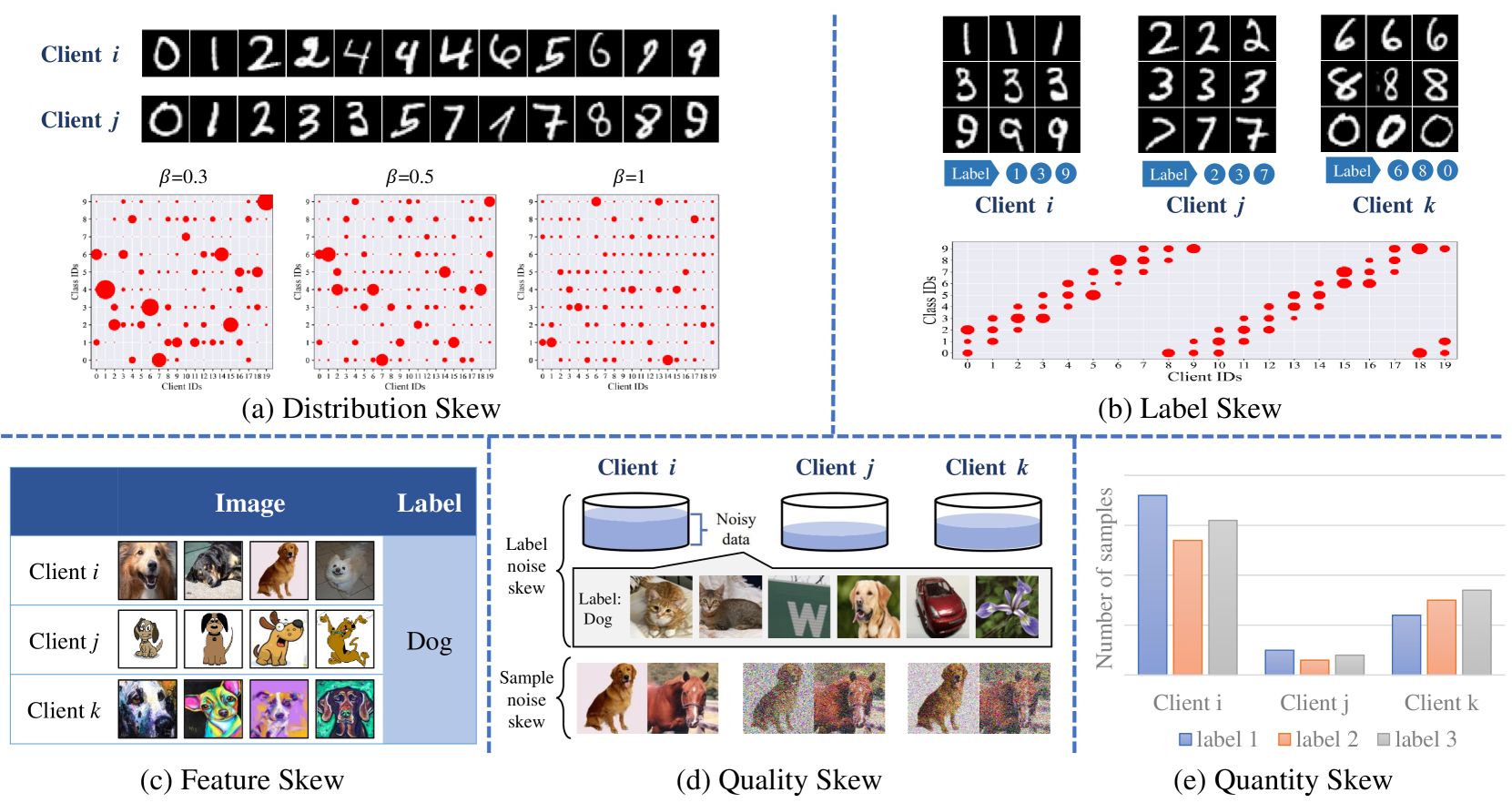
0
Advances in Robust Federated Learning: Heterogeneity Considerations
Chuan Chen, Tianchi Liao, Xiaojun Deng, Zihou Wu, Sheng Huang, Zibin Zheng
In the field of heterogeneous federated learning (FL), the key challenge is to efficiently and collaboratively train models across multiple clients with different data distributions, model structures, task objectives, computational capabilities, and communication resources. This diversity leads to significant heterogeneity, which increases the complexity of model training. In this paper, we first outline the basic concepts of heterogeneous federated learning and summarize the research challenges in federated learning in terms of five aspects: data, model, task, device, and communication. In addition, we explore how existing state-of-the-art approaches cope with the heterogeneity of federated learning, and categorize and review these approaches at three different levels: data-level, model-level, and architecture-level. Subsequently, the paper extensively discusses privacy-preserving strategies in heterogeneous federated learning environments. Finally, the paper discusses current open issues and directions for future research, aiming to promote the further development of heterogeneous federated learning.
Read more5/17/2024

0
On the Impact of Data Heterogeneity in Federated Learning Environments with Application to Healthcare Networks
Usevalad Milasheuski, Luca Barbieri, Bernardo Camajori Tedeschini, Monica Nicoli, Stefano Savazzi
Federated Learning (FL) allows multiple privacy-sensitive applications to leverage their dataset for a global model construction without any disclosure of the information. One of those domains is healthcare, where groups of silos collaborate in order to generate a global predictor with improved accuracy and generalization. However, the inherent challenge lies in the high heterogeneity of medical data, necessitating sophisticated techniques for assessment and compensation. This paper presents a comprehensive exploration of the mathematical formalization and taxonomy of heterogeneity within FL environments, focusing on the intricacies of medical data. In particular, we address the evaluation and comparison of the most popular FL algorithms with respect to their ability to cope with quantity-based, feature and label distribution-based heterogeneity. The goal is to provide a quantitative evaluation of the impact of data heterogeneity in FL systems for healthcare networks as well as a guideline on FL algorithm selection. Our research extends beyond existing studies by benchmarking seven of the most common FL algorithms against the unique challenges posed by medical data use cases. The paper targets the prediction of the risk of stroke recurrence through a set of tabular clinical reports collected by different federated hospital silos: data heterogeneity frequently encountered in this scenario and its impact on FL performance are discussed.
Read more9/6/2024

0
Algorithms for Collaborative Machine Learning under Statistical Heterogeneity
Seok-Ju Hahn
Learning from distributed data without accessing them is undoubtedly a challenging and non-trivial task. Nevertheless, the necessity for distributed training of a statistical model has been increasing, due to the privacy concerns of local data owners and the cost in centralizing the massively distributed data. Federated learning (FL) is currently the de facto standard of training a machine learning model across heterogeneous data owners, without leaving the raw data out of local silos. Nevertheless, several challenges must be addressed in order for FL to be more practical in reality. Among these challenges, the statistical heterogeneity problem is the most significant and requires immediate attention. From the main objective of FL, three major factors can be considered as starting points -- textit{parameter}, textit{mixing coefficient}, and textit{local data distributions}. In alignment with the components, this dissertation is organized into three parts. In Chapter II, a novel personalization method, texttt{SuPerFed}, inspired by the mode-connectivity is introduced. In Chapter III, an adaptive decision-making algorithm, texttt{AAggFF}, is introduced for inducing uniform performance distributions in participating clients, which is realized by online convex optimization framework. Finally, in Chapter IV, a collaborative synthetic data generation method, texttt{FedEvg}, is introduced, leveraging the flexibility and compositionality of an energy-based modeling approach. Taken together, all of these approaches provide practical solutions to mitigate the statistical heterogeneity problem in data-decentralized settings, paving the way for distributed systems and applications using collaborative machine learning methods.
Read more8/2/2024