ADSumm: Annotated Ground-truth Summary Datasets for Disaster Tweet Summarization

0
Sign in to get full access
Overview
- This paper proposes a new dataset called ADSumm for disaster tweet summarization.
- The dataset provides annotated ground-truth summaries for tweets related to disaster events.
- The authors suggest that this dataset can be used to train and evaluate models for summarizing disaster-related tweets.
Plain English Explanation
The paper introduces a new dataset called ADSumm that is designed to help train and test algorithms for summarizing tweets about disaster events. When major disasters happen, people often turn to social media platforms like Twitter to share information and updates. However, this can result in a large volume of tweets that can be overwhelming to sift through. The goal of the ADSumm dataset is to provide a standardized set of example tweets and corresponding human-written summaries that can be used to develop better automated systems for summarizing disaster-related tweets. [The authors suggest that this dataset could be valuable for advancing the state-of-the-art in <a href="https://aimodels.fyi/papers/arxiv/atsumm-auxiliary-information-enhanced-approach-abstractive-disaster">disaster tweet summarization</a>.]
The key idea behind the ADSumm dataset is to provide high-quality ground-truth summaries that can serve as a benchmark for evaluating different summarization models. By having a common dataset to work with, researchers can more easily compare the performance of their models and identify areas for improvement. [The authors note that this type of standardized dataset could also benefit other text summarization tasks, such as <a href="https://aimodels.fyi/papers/arxiv/product-description-qa-assisted-self-supervised-opinion">product review summarization</a> or <a href="https://aimodels.fyi/papers/arxiv/named-entity-recognition-topic-modeling-based-solution">news article summarization</a>.]
Technical Explanation
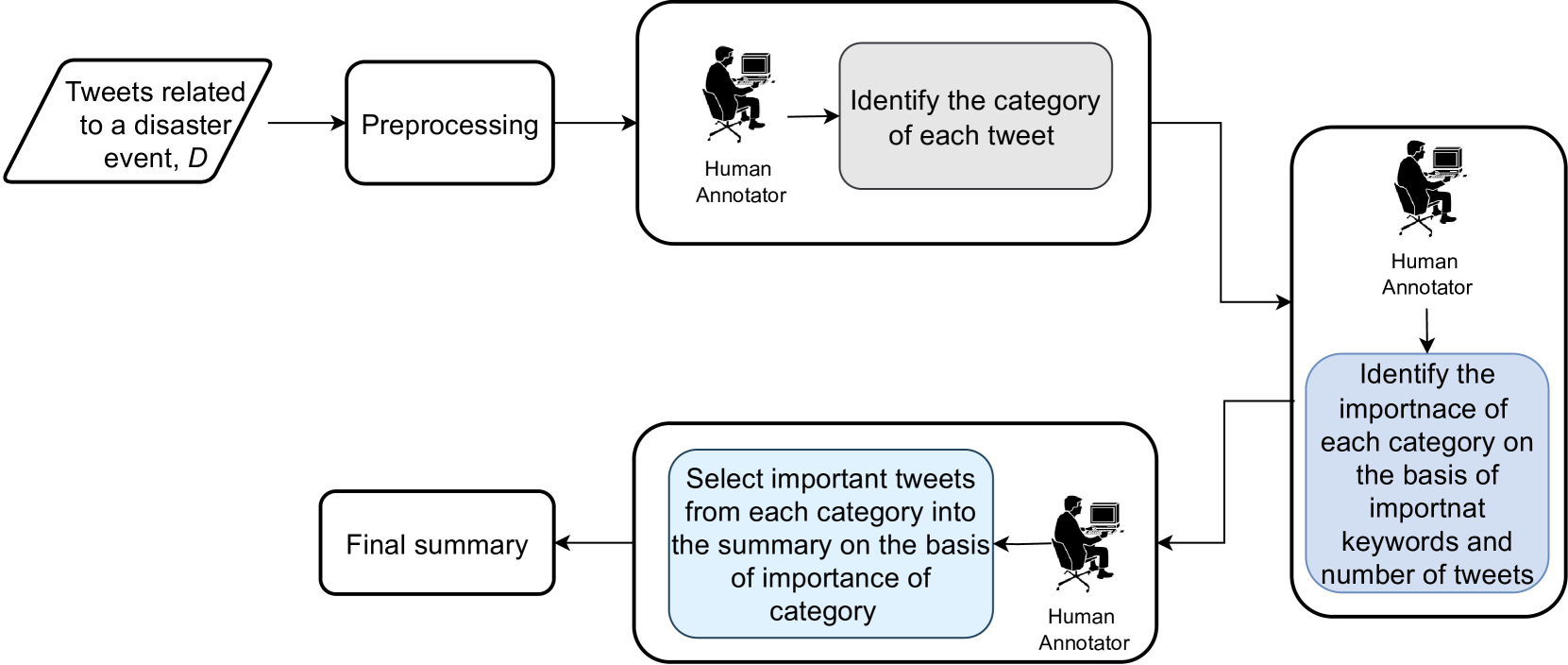
The ADSumm dataset contains over 16,000 tweets related to 41 different disaster events, each paired with a human-written summary. The tweets were collected from Twitter using disaster-related keywords, and the summaries were generated by crowdsourced annotators who were instructed to provide a concise yet comprehensive overview of the key information in each tweet.
The authors describe a rigorous annotation process to ensure the quality and consistency of the summaries. This included providing annotators with detailed guidelines, conducting multiple rounds of review, and calculating inter-annotator agreement metrics. [The authors suggest that this annotation process could serve as a model for developing other <a href="https://aimodels.fyi/papers/arxiv/reflectsumm-benchmark-course-reflection-summarization">ground-truth summary datasets</a> in the future.]
In addition to the tweet-summary pairs, the ADSumm dataset also includes various metadata about each tweet, such as the disaster event, the user's location, and the timestamp. The authors propose that these additional features could be leveraged by summarization models to improve performance. [For example, models could potentially use <a href="https://aimodels.fyi/papers/arxiv/label-free-topic-focused-summarization-using-query">topic information or user context</a> to generate more relevant and focused summaries.]
Critical Analysis
The authors acknowledge several limitations of the ADSumm dataset. For instance, the dataset is focused solely on disaster-related tweets, which may limit its applicability to other domains. Additionally, the summaries were generated by crowdsourced annotators, which could introduce some inconsistencies or biases.
Another potential issue is the inherent challenge of summarizing social media content, which is often informal, noisy, and lacking in context. The authors note that developing effective summarization models for this type of data remains an open and difficult problem.
Despite these limitations, the ADSumm dataset represents a valuable contribution to the field of text summarization. By providing a standardized benchmark for disaster tweet summarization, the dataset has the potential to drive progress in this important and rapidly evolving area of research.
Conclusion
The ADSumm dataset introduced in this paper offers a new resource for developing and evaluating models for summarizing disaster-related tweets. The high-quality, annotated summaries can serve as a benchmark to compare the performance of different summarization approaches and identify areas for improvement. While the dataset has some limitations, it has the potential to significantly advance the state-of-the-art in disaster tweet summarization and potentially other text summarization tasks as well.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
ADSumm: Annotated Ground-truth Summary Datasets for Disaster Tweet Summarization
Piyush Kumar Garg, Roshni Chakraborty, Sourav Kumar Dandapat
Online social media platforms, such as Twitter, provide valuable information during disaster events. Existing tweet disaster summarization approaches provide a summary of these events to aid government agencies, humanitarian organizations, etc., to ensure effective disaster response. In the literature, there are two types of approaches for disaster summarization, namely, supervised and unsupervised approaches. Although supervised approaches are typically more effective, they necessitate a sizable number of disaster event summaries for testing and training. However, there is a lack of good number of disaster summary datasets for training and evaluation. This motivates us to add more datasets to make supervised learning approaches more efficient. In this paper, we present ADSumm, which adds annotated ground-truth summaries for eight disaster events which consist of both natural and man-made disaster events belonging to seven different countries. Our experimental analysis shows that the newly added datasets improve the performance of the supervised summarization approaches by 8-28% in terms of ROUGE-N F1-score. Moreover, in newly annotated dataset, we have added a category label for each input tweet which helps to ensure good coverage from different categories in summary. Additionally, we have added two other features relevance label and key-phrase, which provide information about the quality of a tweet and explanation about the inclusion of the tweet into summary, respectively. For ground-truth summary creation, we provide the annotation procedure adapted in detail, which has not been described in existing literature. Experimental analysis shows the quality of ground-truth summary is very good with Coverage, Relevance and Diversity.
Read more5/13/2024
🏋️
0
ATSumm: Auxiliary information enhanced approach for abstractive disaster Tweet Summarization with sparse training data
Piyush Kumar Garg, Roshni Chakraborty, Sourav Kumar Dandapat
The abundance of situational information on Twitter poses a challenge for users to manually discern vital and relevant information during disasters. A concise and human-interpretable overview of this information helps decision-makers in implementing efficient and quick disaster response. Existing abstractive summarization approaches can be categorized as sentence-based or key-phrase-based approaches. This paper focuses on sentence-based approach, which is typically implemented as a dual-phase procedure in literature. The initial phase, known as the extractive phase, involves identifying the most relevant tweets. The subsequent phase, referred to as the abstractive phase, entails generating a more human-interpretable summary. In this study, we adopt the methodology from prior research for the extractive phase. For the abstractive phase of summarization, most existing approaches employ deep learning-based frameworks, which can either be pre-trained or require training from scratch. However, to achieve the appropriate level of performance, it is imperative to have substantial training data for both methods, which is not readily available. This work presents an Abstractive Tweet Summarizer (ATSumm) that effectively addresses the issue of data sparsity by using auxiliary information. We introduced the Auxiliary Pointer Generator Network (AuxPGN) model, which utilizes a unique attention mechanism called Key-phrase attention. This attention mechanism incorporates auxiliary information in the form of key-phrases and their corresponding importance scores from the input tweets. We evaluate the proposed approach by comparing it with 10 state-of-the-art approaches across 13 disaster datasets. The evaluation results indicate that ATSumm achieves superior performance compared to state-of-the-art approaches, with improvement of 4-80% in ROUGE-N F1-score.
Read more5/13/2024

0
SurveySum: A Dataset for Summarizing Multiple Scientific Articles into a Survey Section
Leandro Car'isio Fernandes, Gustavo Bartz Guedes, Thiago Soares Laitz, Thales Sales Almeida, Rodrigo Nogueira, Roberto Lotufo, Jayr Pereira
Document summarization is a task to shorten texts into concise and informative summaries. This paper introduces a novel dataset designed for summarizing multiple scientific articles into a section of a survey. Our contributions are: (1) SurveySum, a new dataset addressing the gap in domain-specific summarization tools; (2) two specific pipelines to summarize scientific articles into a section of a survey; and (3) the evaluation of these pipelines using multiple metrics to compare their performance. Our results highlight the importance of high-quality retrieval stages and the impact of different configurations on the quality of generated summaries.
Read more8/30/2024

0
Real-Time Summarization of Twitter
Yixin Jin, Meiqi Wang, Meng Li, Wenjing Zhou, Yi Shen, Hao Liu
In this paper, we describe our approaches to TREC Real-Time Summarization of Twitter. We focus on real time push notification scenario, which requires a system monitors the stream of sampled tweets and returns the tweets relevant and novel to given interest profiles. Dirichlet score with and with very little smoothing (baseline) are employed to classify whether a tweet is relevant to a given interest profile. Using metrics including Mean Average Precision (MAP, cumulative gain (CG) and discount cumulative gain (DCG), the experiment indicates that our approach has a good performance. It is also desired to remove the redundant tweets from the pushing queue. Due to the precision limit, we only describe the algorithm in this paper.
Read more7/12/2024