Adversarial Evasion Attacks Practicality in Networks: Testing the Impact of Dynamic Learning
2306.05494
0
0
🧪
Abstract
Machine Learning (ML) has become ubiquitous, and its deployment in Network Intrusion Detection Systems (NIDS) is inevitable due to its automated nature and high accuracy compared to traditional models in processing and classifying large volumes of data. However, ML has been found to have several flaws, most importantly, adversarial attacks, which aim to trick ML models into producing faulty predictions. While most adversarial attack research focuses on computer vision datasets, recent studies have explored the suitability of these attacks against ML-based network security entities, especially NIDS, due to the wide difference between different domains regarding the generation of adversarial attacks. To further explore the practicality of adversarial attacks against ML-based NIDS in-depth, this paper presents three distinct contributions: identifying numerous practicality issues for evasion adversarial attacks on ML-NIDS using an attack tree threat model, introducing a taxonomy of practicality issues associated with adversarial attacks against ML-based NIDS, and investigating how the dynamicity of some real-world ML models affects adversarial attacks against NIDS. Our experiments indicate that continuous re-training, even without adversarial training, can reduce the effectiveness of adversarial attacks. While adversarial attacks can compromise ML-based NIDSs, our aim is to highlight the significant gap between research and real-world practicality in this domain, warranting attention.
Create account to get full access
Overview
- Machine learning (ML) is widely used in network intrusion detection systems (NIDS) due to its automated processing and high accuracy.
- However, ML models can be vulnerable to adversarial attacks that trick them into making incorrect predictions.
- Most adversarial attack research has focused on computer vision, but this paper explores the practicality of such attacks against ML-based NIDS.
Plain English Explanation
Machine learning has become a common tool for automating the detection of network intrusions, as it can quickly process and classify large volumes of data with high accuracy. However, researchers have found that machine learning models can be susceptible to adversarial attacks - techniques that intentionally modify inputs to mislead the model and cause it to make incorrect predictions.
Most previous work on adversarial attacks has looked at computer vision applications, but this paper investigates how these attacks might work against machine learning-based network intrusion detection systems. The researchers wanted to understand the real-world practicality of such attacks in this domain, since network security is a critical application where faulty predictions could have serious consequences.
Technical Explanation
The paper makes three key contributions:
- It uses an attack tree threat model to identify numerous practical challenges and limitations for conducting evasion adversarial attacks against ML-based NIDS.
- It introduces a taxonomy that categorizes the different types of practicality issues associated with adversarial attacks on ML-NIDS.
- It examines how the dynamic nature of real-world ML models, such as continuous re-training, can reduce the effectiveness of adversarial attacks.
The researchers conducted experiments showing that even without special adversarial training, the practice of regularly re-training ML models for NIDS can make them more robust against adversarial attacks. While such attacks can still compromise ML-based NIDS under certain conditions, the paper highlights a significant gap between the theoretical capabilities demonstrated in research and the practical challenges of deploying these attacks in real-world network security systems.
Critical Analysis
The paper does a thorough job of mapping out the numerous practical challenges that would need to be overcome to successfully execute adversarial attacks against ML-based NIDS in practice. The taxonomy of practicality issues is a useful framework for understanding the key barriers.
However, the paper does not deeply explore all the potential limitations and caveats of its findings. For example, it acknowledges that the dynamic nature of real-world ML models can reduce attack effectiveness, but does not fully consider how an attacker might adapt their techniques in response. There may also be other real-world factors, beyond just model re-training, that could further constrain the feasibility of these attacks.
Additionally, while the paper highlights the gap between theoretical and practical adversarial attacks, it does not speculate on the broader implications of this gap for the field of network security. More discussion on the ramifications and potential future research directions would have strengthened the analysis.
Conclusion
This paper makes an important contribution by shifting the focus of adversarial attack research from the well-studied domain of computer vision to the critical area of network security. By closely examining the practical challenges of deploying such attacks against ML-based NIDS, the researchers have revealed a significant disconnect between the threats demonstrated in academic settings and the realities of real-world deployment.
While adversarial attacks can still compromise ML-NIDS under certain conditions, the paper suggests that factors like continuous model re-training can substantially mitigate the effectiveness of these attacks in practice. This insight highlights the need for network security researchers and practitioners to carefully consider the practical limitations when assessing the actual risks posed by adversarial machine learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Problem space structural adversarial attacks for Network Intrusion Detection Systems based on Graph Neural Networks
Andrea Venturi, Dario Stabili, Mirco Marchetti
0
0
Machine Learning (ML) algorithms have become increasingly popular for supporting Network Intrusion Detection Systems (NIDS). Nevertheless, extensive research has shown their vulnerability to adversarial attacks, which involve subtle perturbations to the inputs of the models aimed at compromising their performance. Recent proposals have effectively leveraged Graph Neural Networks (GNN) to produce predictions based also on the structural patterns exhibited by intrusions to enhance the detection robustness. However, the adoption of GNN-based NIDS introduces new types of risks. In this paper, we propose the first formalization of adversarial attacks specifically tailored for GNN in network intrusion detection. Moreover, we outline and model the problem space constraints that attackers need to consider to carry out feasible structural attacks in real-world scenarios. As a final contribution, we conduct an extensive experimental campaign in which we launch the proposed attacks against state-of-the-art GNN-based NIDS. Our findings demonstrate the increased robustness of the models against classical feature-based adversarial attacks, while highlighting their susceptibility to structure-based attacks.
4/24/2024
🔎
Intriguing Properties of Adversarial ML Attacks in the Problem Space [Extended Version]
Jacopo Cortellazzi, Feargus Pendlebury, Daniel Arp, Erwin Quiring, Fabio Pierazzi, Lorenzo Cavallaro
0
0
Recent research efforts on adversarial machine learning (ML) have investigated problem-space attacks, focusing on the generation of real evasive objects in domains where, unlike images, there is no clear inverse mapping to the feature space (e.g., software). However, the design, comparison, and real-world implications of problem-space attacks remain underexplored. This article makes three major contributions. Firstly, we propose a general formalization for adversarial ML evasion attacks in the problem-space, which includes the definition of a comprehensive set of constraints on available transformations, preserved semantics, absent artifacts, and plausibility. We shed light on the relationship between feature space and problem space, and we introduce the concept of side-effect features as the by-product of the inverse feature-mapping problem. This enables us to define and prove necessary and sufficient conditions for the existence of problem-space attacks. Secondly, building on our general formalization, we propose a novel problem-space attack on Android malware that overcomes past limitations in terms of semantics and artifacts. We have tested our approach on a dataset with 150K Android apps from 2016 and 2018 which show the practical feasibility of evading a state-of-the-art malware classifier along with its hardened version. Thirdly, we explore the effectiveness of adversarial training as a possible approach to enforce robustness against adversarial samples, evaluating its effectiveness on the considered machine learning models under different scenarios. Our results demonstrate that adversarial-malware as a service is a realistic threat, as we automatically generate thousands of realistic and inconspicuous adversarial applications at scale, where on average it takes only a few minutes to generate an adversarial instance.
6/28/2024
From Attack to Defense: Insights into Deep Learning Security Measures in Black-Box Settings
Firuz Juraev, Mohammed Abuhamad, Eric Chan-Tin, George K. Thiruvathukal, Tamer Abuhmed
0
0
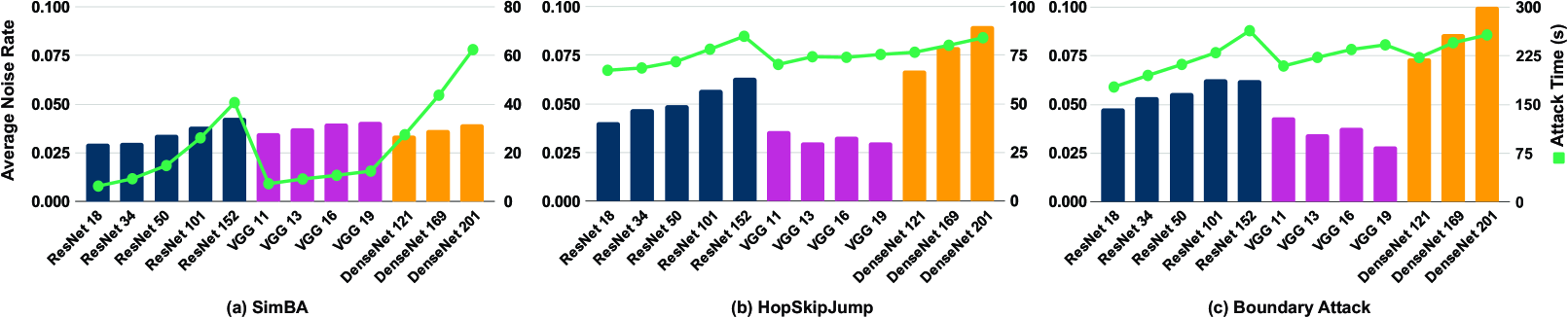
Deep Learning (DL) is rapidly maturing to the point that it can be used in safety- and security-crucial applications. However, adversarial samples, which are undetectable to the human eye, pose a serious threat that can cause the model to misbehave and compromise the performance of such applications. Addressing the robustness of DL models has become crucial to understanding and defending against adversarial attacks. In this study, we perform comprehensive experiments to examine the effect of adversarial attacks and defenses on various model architectures across well-known datasets. Our research focuses on black-box attacks such as SimBA, HopSkipJump, MGAAttack, and boundary attacks, as well as preprocessor-based defensive mechanisms, including bits squeezing, median smoothing, and JPEG filter. Experimenting with various models, our results demonstrate that the level of noise needed for the attack increases as the number of layers increases. Moreover, the attack success rate decreases as the number of layers increases. This indicates that model complexity and robustness have a significant relationship. Investigating the diversity and robustness relationship, our experiments with diverse models show that having a large number of parameters does not imply higher robustness. Our experiments extend to show the effects of the training dataset on model robustness. Using various datasets such as ImageNet-1000, CIFAR-100, and CIFAR-10 are used to evaluate the black-box attacks. Considering the multiple dimensions of our analysis, e.g., model complexity and training dataset, we examined the behavior of black-box attacks when models apply defenses. Our results show that applying defense strategies can significantly reduce attack effectiveness. This research provides in-depth analysis and insight into the robustness of DL models against various attacks, and defenses.
5/6/2024

Defending Against Unforeseen Failure Modes with Latent Adversarial Training
Stephen Casper, Lennart Schulze, Oam Patel, Dylan Hadfield-Menell
0
0
Despite extensive diagnostics and debugging by developers, AI systems sometimes exhibit harmful unintended behaviors. Finding and fixing these is challenging because the attack surface is so large -- it is not tractable to exhaustively search for inputs that may elicit harmful behaviors. Red-teaming and adversarial training (AT) are commonly used to improve robustness, however, they empirically struggle to fix failure modes that differ from the attacks used during training. In this work, we utilize latent adversarial training (LAT) to defend against vulnerabilities without generating inputs that elicit them. LAT leverages the compressed, abstract, and structured latent representations of concepts that the network actually uses for prediction. We use it to remove trojans and defend against held-out classes of adversarial attacks. We show in image classification, text classification, and text generation tasks that LAT usually improves both robustness to novel attacks and performance on clean data relative to AT. This suggests that LAT can be a promising tool for defending against failure modes that are not explicitly identified by developers.
4/3/2024