AdvisorQA: Towards Helpful and Harmless Advice-seeking Question Answering with Collective Intelligence
2404.11826
0
0

Abstract
As the integration of large language models into daily life is on the rise, there is a clear gap in benchmarks for advising on subjective and personal dilemmas. To address this, we introduce AdvisorQA, the first benchmark developed to assess LLMs' capability in offering advice for deeply personalized concerns, utilizing the LifeProTips subreddit forum. This forum features a dynamic interaction where users post advice-seeking questions, receiving an average of 8.9 advice per query, with 164.2 upvotes from hundreds of users, embodying a collective intelligence framework. Therefore, we've completed a benchmark encompassing daily life questions, diverse corresponding responses, and majority vote ranking to train our helpfulness metric. Baseline experiments validate the efficacy of AdvisorQA through our helpfulness metric, GPT-4, and human evaluation, analyzing phenomena beyond the trade-off between helpfulness and harmlessness. AdvisorQA marks a significant leap in enhancing QA systems for providing personalized, empathetic advice, showcasing LLMs' improved understanding of human subjectivity.
Create account to get full access
Overview
- This paper introduces AdvisorQA, a novel dataset and approach for helpful and harmless advice-seeking question answering using collective intelligence.
- The goal is to develop AI systems that can provide useful advice to users while avoiding harmful or unethical outputs.
- The dataset includes a large number of real-world advice-seeking questions and human-generated responses, annotated for helpfulness and safety.
- The paper explores different AI models and techniques to generate high-quality, trustworthy advice in response to user questions.
Plain English Explanation
The paper describes a new dataset and approach called AdvisorQA that aims to help AI systems provide useful and safe advice to users.
The key idea is to tap into "collective intelligence" - drawing on a large number of real-world questions and responses from humans to train AI models that can give helpful advice while avoiding harmful or unethical outputs. The dataset includes many examples of advice-seeking questions and the answers people have provided, which have been carefully annotated to identify which responses are truly helpful and which might be problematic.
By learning from this diverse dataset, the researchers hope to develop AI assistants that can engage in thoughtful, nuanced dialogue to guide users on a wide range of topics - whether that's navigating a personal problem, making a major life decision, or simply getting a recommendation. At the same time, the system is designed with safeguards to prevent the AI from giving advice that could be harmful or unethical.
This is an important challenge, as conversational AI assistants become more prevalent in our lives. We want these systems to be genuinely helpful, but also to have the wisdom and judgment to avoid giving advice that could lead someone astray or cause harm. The AdvisorQA approach aims to balance those priorities.
Technical Explanation
The paper introduces the AdvisorQA dataset, which contains over 100,000 real-world advice-seeking questions and human-generated responses, collected from online forums and other sources. The responses have been carefully annotated by human raters to indicate whether they are helpful and safe, or potentially harmful or unethical.
The researchers then explore different AI modeling approaches to generate high-quality advice in response to user questions, drawing on this large dataset of human knowledge and wisdom. They experiment with language models, retrieval-based systems, and hybrid approaches that combine multiple techniques.
Key innovations include:
- Helpfulness and Safety Ranking: Models are trained not just to generate relevant responses, but to assess the helpfulness and safety of candidate answers before presenting them to the user.
- Ethical Prompting: The AI is guided to provide responses aligned with principles of beneficence, non-maleficence, autonomy, justice, and other ethical considerations.
- Collective Intelligence Aggregation: The system aggregates insights from many human contributors to provide well-rounded, trustworthy advice.
Through extensive experiments, the paper demonstrates that the AdvisorQA approach can generate helpful and safe advice that outperforms standard language models and retrieval systems. The models are also able to adapt their responses based on the specific user and context.
Critical Analysis
The paper makes a compelling case for the importance of developing AI systems that can provide useful advice while avoiding harmful outputs. The AdvisorQA dataset and modeling approach represent a valuable step towards that goal.
However, the authors acknowledge several limitations and areas for further research:
- The dataset, while large, may not fully capture the diversity of real-world advice-seeking questions and contexts.
- Evaluating the "helpfulness" and "safety" of responses is inherently subjective, and the annotation process may have introduced biases.
- The models still struggle with some types of complex, open-ended questions that require deeper reasoning and understanding.
- Scaling the approach to handle an ever-expanding universe of user queries and scenarios remains a significant challenge.
Additionally, one could question whether an AI system, no matter how well-designed, should be entrusted with providing advice on sensitive personal matters. There are valid concerns about the potential for unintended consequences, and the appropriate role of technology in such domains.
Ultimately, the AdvisorQA research represents an important step forward, but there is still much work to be done to create AI assistants that can reliably and responsibly guide users on life's most important decisions.
Conclusion
The AdvisorQA paper introduces a novel dataset and approach for developing AI systems that can provide helpful and safe advice to users. By drawing on a large corpus of real-world advice-seeking questions and human-generated responses, the researchers aim to create conversational AI assistants that can offer trustworthy guidance on a wide range of topics.
This work is significant as AI becomes increasingly integrated into our daily lives. We want these systems to be truly helpful, but also to have the wisdom and judgment to avoid giving advice that could be harmful or unethical. The AdvisorQA project represents an important step towards that goal, though significant challenges remain in scaling the approach and ensuring the appropriate use of AI in sensitive personal domains.
Overall, this research highlights the potential for collective intelligence and thoughtful system design to create AI assistants that can be valuable partners in navigating life's complexities, while remaining firmly grounded in ethical principles. As AI continues to evolve, approaches like AdvisorQA will be crucial for unlocking the full potential of these technologies in a safe and responsible manner.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Aligning LLMs through Multi-perspective User Preference Ranking-based Feedback for Programming Question Answering
Hongyu Yang, Liyang He, Min Hou, Shuanghong Shen, Rui Li, Jiahui Hou, Jianhui Ma, Junda Zhao
0
0
Code Community Question Answering (CCQA) seeks to tackle programming-related issues, thereby boosting productivity in both software engineering and academic research. Recent advancements in Reinforcement Learning from Human Feedback (RLHF) have transformed the fine-tuning process of Large Language Models (LLMs) to produce responses that closely mimic human behavior. Leveraging LLMs with RLHF for practical CCQA applications has thus emerged as a promising area of study. Unlike standard code question-answering tasks, CCQA involves multiple possible answers, with varying user preferences for each response. Additionally, code communities often show a preference for new APIs. These challenges prevent LLMs from generating responses that cater to the diverse preferences of users in CCQA tasks. To address these issues, we propose a novel framework called Aligning LLMs through Multi-perspective User Preference Ranking-based Feedback for Programming Question Answering (ALMupQA) to create user-focused responses. Our approach starts with Multi-perspective Preference Ranking Alignment (MPRA), which synthesizes varied user preferences based on the characteristics of answers from code communities. We then introduce a Retrieval-augmented In-context Learning (RIL) module to mitigate the problem of outdated answers by retrieving responses to similar questions from a question bank. Due to the limited availability of high-quality, multi-answer CCQA datasets, we also developed a dataset named StaCCQA from real code communities. Extensive experiments demonstrated the effectiveness of the ALMupQA framework in terms of accuracy and user preference. Compared to the base model, ALMupQA showed nearly an 11% improvement in BLEU, with increases of 20% and 17.5% in BERTScore and CodeBERTScore, respectively.
6/4/2024
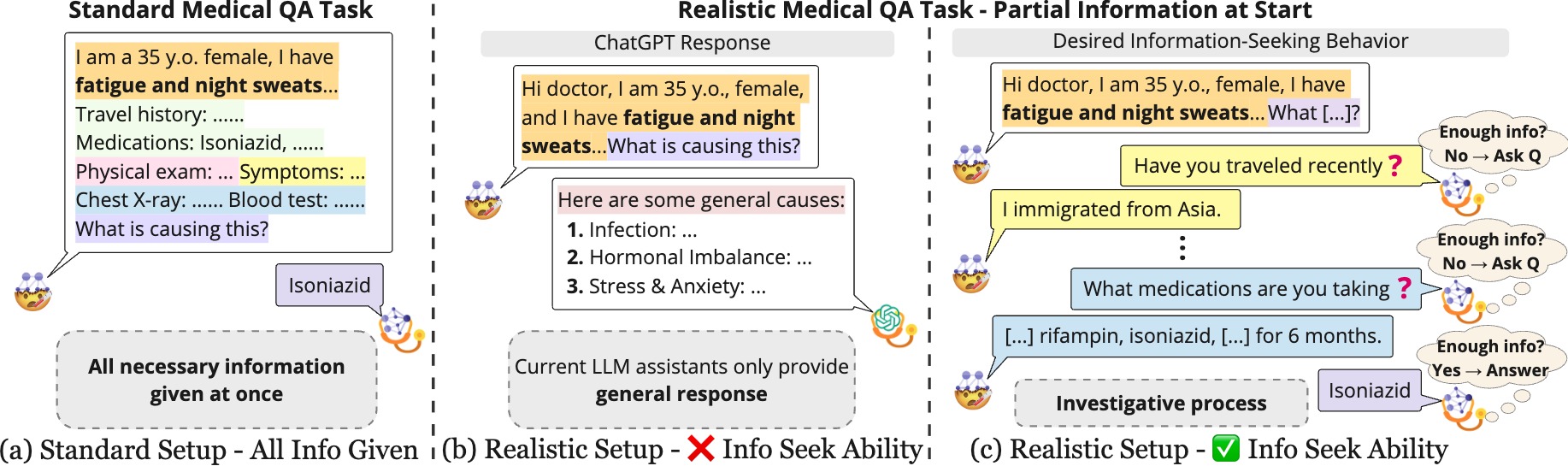
MEDIQ: Question-Asking LLMs for Adaptive and Reliable Medical Reasoning
Shuyue Stella Li, Vidhisha Balachandran, Shangbin Feng, Jonathan Ilgen, Emma Pierson, Pang Wei Koh, Yulia Tsvetkov
0
0
In high-stakes domains like clinical reasoning, AI assistants powered by large language models (LLMs) are yet to be reliable and safe. We identify a key obstacle towards reliability: existing LLMs are trained to answer any question, even with incomplete context in the prompt or insufficient parametric knowledge. We propose to change this paradigm to develop more careful LLMs that ask follow-up questions to gather necessary and sufficient information and respond reliably. We introduce MEDIQ, a framework to simulate realistic clinical interactions, which incorporates a Patient System and an adaptive Expert System. The Patient may provide incomplete information in the beginning; the Expert refrains from making diagnostic decisions when unconfident, and instead elicits missing details from the Patient via follow-up questions. To evaluate MEDIQ, we convert MEDQA and CRAFT-MD -- medical benchmarks for diagnostic question answering -- into an interactive setup. We develop a reliable Patient system and prototype several Expert systems, first showing that directly prompting state-of-the-art LLMs to ask questions degrades the quality of clinical reasoning, indicating that adapting LLMs to interactive information-seeking settings is nontrivial. We then augment the Expert with a novel abstention module to better estimate model confidence and decide whether to ask more questions, thereby improving diagnostic accuracy by 20.3%; however, performance still lags compared to an (unrealistic in practice) upper bound when full information is given upfront. Further analyses reveal that interactive performance can be improved by filtering irrelevant contexts and reformatting conversations. Overall, our paper introduces a novel problem towards LLM reliability, a novel MEDIQ framework, and highlights important future directions to extend the information-seeking abilities of LLM assistants in critical domains.
6/5/2024

(A)I Am Not a Lawyer, But...: Engaging Legal Experts towards Responsible LLM Policies for Legal Advice
Inyoung Cheong, King Xia, K. J. Kevin Feng, Quan Ze Chen, Amy X. Zhang
0
0
Large language models (LLMs) are increasingly capable of providing users with advice in a wide range of professional domains, including legal advice. However, relying on LLMs for legal queries raises concerns due to the significant expertise required and the potential real-world consequences of the advice. To explore textit{when} and textit{why} LLMs should or should not provide advice to users, we conducted workshops with 20 legal experts using methods inspired by case-based reasoning. The provided realistic queries (cases) allowed experts to examine granular, situation-specific concerns and overarching technical and legal constraints, producing a concrete set of contextual considerations for LLM developers. By synthesizing the factors that impacted LLM response appropriateness, we present a 4-dimension framework: (1) User attributes and behaviors, (2) Nature of queries, (3) AI capabilities, and (4) Social impacts. We share experts' recommendations for LLM response strategies, which center around helping users identify `right questions to ask' and relevant information rather than providing definitive legal judgments. Our findings reveal novel legal considerations, such as unauthorized practice of law, confidentiality, and liability for inaccurate advice, that have been overlooked in the literature. The case-based deliberation method enabled us to elicit fine-grained, practice-informed insights that surpass those from de-contextualized surveys or speculative principles. These findings underscore the applicability of our method for translating domain-specific professional knowledge and practices into policies that can guide LLM behavior in a more responsible direction.
5/6/2024

MedExQA: Medical Question Answering Benchmark with Multiple Explanations
Yunsoo Kim, Jinge Wu, Yusuf Abdulle, Honghan Wu
0
0
This paper introduces MedExQA, a novel benchmark in medical question-answering, to evaluate large language models' (LLMs) understanding of medical knowledge through explanations. By constructing datasets across five distinct medical specialties that are underrepresented in current datasets and further incorporating multiple explanations for each question-answer pair, we address a major gap in current medical QA benchmarks which is the absence of comprehensive assessments of LLMs' ability to generate nuanced medical explanations. Our work highlights the importance of explainability in medical LLMs, proposes an effective methodology for evaluating models beyond classification accuracy, and sheds light on one specific domain, speech language pathology, where current LLMs including GPT4 lack good understanding. Our results show generation evaluation with multiple explanations aligns better with human assessment, highlighting an opportunity for a more robust automated comprehension assessment for LLMs. To diversify open-source medical LLMs (currently mostly based on Llama2), this work also proposes a new medical model, MedPhi-2, based on Phi-2 (2.7B). The model outperformed medical LLMs based on Llama2-70B in generating explanations, showing its effectiveness in the resource-constrained medical domain. We will share our benchmark datasets and the trained model.
6/11/2024