AI-Driven Review Systems: Evaluating LLMs in Scalable and Bias-Aware Academic Reviews

0

Sign in to get full access
Overview
- Examines the use of large language models (LLMs) in academic peer review systems
- Proposes a framework for developing scalable and bias-aware review systems
- Evaluates the performance and limitations of LLMs in this context
Plain English Explanation
The paper explores the use of advanced artificial intelligence (AI) systems, specifically large language models (LLMs), to assist in the academic peer review process. Peer review is a crucial step in academic publishing, where experts in a field provide feedback on research papers before they are accepted for publication. However, the traditional peer review process can be time-consuming and potentially biased.
The researchers investigate the potential of LLMs to streamline and improve the peer review system. LLMs are AI models that can process and generate human-like text, and the paper examines how these models can be used to automate parts of the peer review process, such as summarizing the key points of a paper or providing feedback. The researchers also explore ways to make the review process more <a href="https://aimodels.fyi/papers/arxiv/human-ai-collaborative-essay-scoring-dual-process">bias-aware</a>, ensuring that the AI-driven reviews are fair and inclusive.
The paper presents a framework for developing scalable and bias-aware review systems that leverage the capabilities of LLMs. This could lead to more efficient and equitable academic publishing, allowing researchers to receive timely feedback and reducing the workload on human reviewers.
Technical Explanation
The paper proposes a framework for developing AI-driven academic review systems that are both scalable and bias-aware. The key components of this framework include:
-
Automated Summarization: LLMs can be used to generate concise summaries of research papers, capturing the key points and contributions. This can help human reviewers quickly understand the paper's content.
-
Bias-Aware Evaluation: The researchers explore methods to ensure that the LLM-generated reviews are <a href="https://aimodels.fyi/papers/arxiv/unveiling-scoring-processes-dissecting-differences-between-llms">free from demographic and other biases</a>. This could involve training the LLMs on diverse datasets and incorporating fairness-aware algorithms.
-
Augmented Human Review: The LLM-generated summaries and feedback can be used to <a href="https://aimodels.fyi/papers/arxiv/pre-peer-review-based-large-language-model">augment the work of human reviewers</a>, allowing them to focus on higher-level analysis and decision-making.
-
Continuous Improvement: The researchers propose a feedback loop where human reviewers can provide corrections and feedback to the LLM models, enabling them to learn and improve over time.
The paper also includes an evaluation of the performance and limitations of LLMs in this context, using both quantitative and qualitative metrics. The results highlight the potential of LLMs to streamline the peer review process while also identifying areas for further research and development.
Critical Analysis
The paper presents a compelling vision for the use of LLMs in academic peer review systems, but it also acknowledges several challenges and limitations:
-
Bias Mitigation: While the researchers propose methods to address bias, <a href="https://aimodels.fyi/papers/arxiv/ai-review-lottery-widespread-ai-assisted-peer">ensuring true fairness and inclusivity in AI-driven reviews</a> remains an ongoing challenge that requires further research and validation.
-
Interpretability and Transparency: The inner workings of LLMs can be opaque, which may raise concerns about the transparency and explainability of the review process. Addressing this issue is crucial for building trust in the system.
-
Scalability and Feasibility: The researchers suggest that their framework can lead to more scalable and efficient review processes, but the practical implementation and adoption of such systems in the academic community will require further investigation and validation.
-
Human Oversight and Collaboration: The paper emphasizes the importance of maintaining human involvement and oversight in the review process, rather than fully automating it. Striking the right balance between human and AI contributions is an area that merits deeper exploration.
Conclusion
The paper presents a promising framework for leveraging LLMs to enhance academic peer review systems, with the potential to improve efficiency, scalability, and bias-awareness. While the proposed approach has several limitations and challenges, the research highlights the valuable role that AI-driven tools can play in supporting and augmenting human expertise in academic publishing. As the field of AI continues to advance, further development and evaluation of such systems will be crucial for improving the quality, fairness, and accessibility of the peer review process.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
AI-Driven Review Systems: Evaluating LLMs in Scalable and Bias-Aware Academic Reviews
Keith Tyser, Ben Segev, Gaston Longhitano, Xin-Yu Zhang, Zachary Meeks, Jason Lee, Uday Garg, Nicholas Belsten, Avi Shporer, Madeleine Udell, Dov Te'eni, Iddo Drori
Automatic reviewing helps handle a large volume of papers, provides early feedback and quality control, reduces bias, and allows the analysis of trends. We evaluate the alignment of automatic paper reviews with human reviews using an arena of human preferences by pairwise comparisons. Gathering human preference may be time-consuming; therefore, we also use an LLM to automatically evaluate reviews to increase sample efficiency while reducing bias. In addition to evaluating human and LLM preferences among LLM reviews, we fine-tune an LLM to predict human preferences, predicting which reviews humans will prefer in a head-to-head battle between LLMs. We artificially introduce errors into papers and analyze the LLM's responses to identify limitations, use adaptive review questions, meta prompting, role-playing, integrate visual and textual analysis, use venue-specific reviewing materials, and predict human preferences, improving upon the limitations of the traditional review processes. We make the reviews of publicly available arXiv and open-access Nature journal papers available online, along with a free service which helps authors review and revise their research papers and improve their quality. This work develops proof-of-concept LLM reviewing systems that quickly deliver consistent, high-quality reviews and evaluate their quality. We mitigate the risks of misuse, inflated review scores, overconfident ratings, and skewed score distributions by augmenting the LLM with multiple documents, including the review form, reviewer guide, code of ethics and conduct, area chair guidelines, and previous year statistics, by finding which errors and shortcomings of the paper may be detected by automated reviews, and evaluating pairwise reviewer preferences. This work identifies and addresses the limitations of using LLMs as reviewers and evaluators and enhances the quality of the reviewing process.
Read more8/21/2024

0
Human-AI Collaborative Essay Scoring: A Dual-Process Framework with LLMs
Changrong Xiao, Wenxing Ma, Qingping Song, Sean Xin Xu, Kunpeng Zhang, Yufang Wang, Qi Fu
Receiving timely and personalized feedback is essential for second-language learners, especially when human instructors are unavailable. This study explores the effectiveness of Large Language Models (LLMs), including both proprietary and open-source models, for Automated Essay Scoring (AES). Through extensive experiments with public and private datasets, we find that while LLMs do not surpass conventional state-of-the-art (SOTA) grading models in performance, they exhibit notable consistency, generalizability, and explainability. We propose an open-source LLM-based AES system, inspired by the dual-process theory. Our system offers accurate grading and high-quality feedback, at least comparable to that of fine-tuned proprietary LLMs, in addition to its ability to alleviate misgrading. Furthermore, we conduct human-AI co-grading experiments with both novice and expert graders. We find that our system not only automates the grading process but also enhances the performance and efficiency of human graders, particularly for essays where the model has lower confidence. These results highlight the potential of LLMs to facilitate effective human-AI collaboration in the educational context, potentially transforming learning experiences through AI-generated feedback.
Read more6/18/2024
1
The AI Review Lottery: Widespread AI-Assisted Peer Reviews Boost Paper Scores and Acceptance Rates
Giuseppe Russo Latona, Manoel Horta Ribeiro, Tim R. Davidson, Veniamin Veselovsky, Robert West
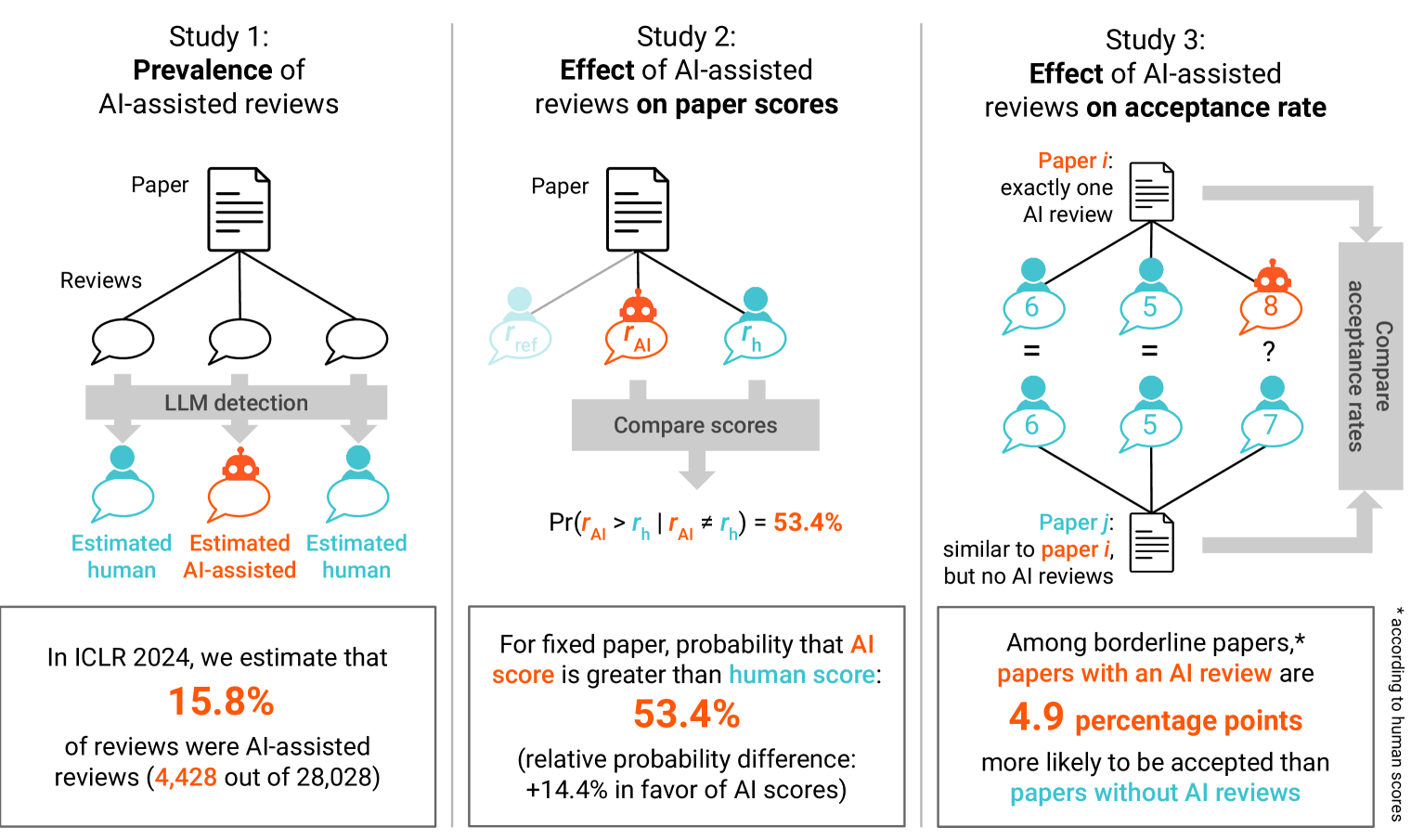
Journals and conferences worry that peer reviews assisted by artificial intelligence (AI), in particular, large language models (LLMs), may negatively influence the validity and fairness of the peer-review system, a cornerstone of modern science. In this work, we address this concern with a quasi-experimental study of the prevalence and impact of AI-assisted peer reviews in the context of the 2024 International Conference on Learning Representations (ICLR), a large and prestigious machine-learning conference. Our contributions are threefold. Firstly, we obtain a lower bound for the prevalence of AI-assisted reviews at ICLR 2024 using the GPTZero LLM detector, estimating that at least $15.8%$ of reviews were written with AI assistance. Secondly, we estimate the impact of AI-assisted reviews on submission scores. Considering pairs of reviews with different scores assigned to the same paper, we find that in $53.4%$ of pairs the AI-assisted review scores higher than the human review ($p = 0.002$; relative difference in probability of scoring higher: $+14.4%$ in favor of AI-assisted reviews). Thirdly, we assess the impact of receiving an AI-assisted peer review on submission acceptance. In a matched study, submissions near the acceptance threshold that received an AI-assisted peer review were $4.9$ percentage points ($p = 0.024$) more likely to be accepted than submissions that did not. Overall, we show that AI-assisted reviews are consequential to the peer-review process and offer a discussion on future implications of current trends
Read more5/6/2024
💬
0
The emergence of Large Language Models (LLM) as a tool in literature reviews: an LLM automated systematic review
Dmitry Scherbakov, Nina Hubig, Vinita Jansari, Alexander Bakumenko, Leslie A. Lenert
Objective: This study aims to summarize the usage of Large Language Models (LLMs) in the process of creating a scientific review. We look at the range of stages in a review that can be automated and assess the current state-of-the-art research projects in the field. Materials and Methods: The search was conducted in June 2024 in PubMed, Scopus, Dimensions, and Google Scholar databases by human reviewers. Screening and extraction process took place in Covidence with the help of LLM add-on which uses OpenAI gpt-4o model. ChatGPT was used to clean extracted data and generate code for figures in this manuscript, ChatGPT and Scite.ai were used in drafting all components of the manuscript, except the methods and discussion sections. Results: 3,788 articles were retrieved, and 172 studies were deemed eligible for the final review. ChatGPT and GPT-based LLM emerged as the most dominant architecture for review automation (n=126, 73.2%). A significant number of review automation projects were found, but only a limited number of papers (n=26, 15.1%) were actual reviews that used LLM during their creation. Most citations focused on automation of a particular stage of review, such as Searching for publications (n=60, 34.9%), and Data extraction (n=54, 31.4%). When comparing pooled performance of GPT-based and BERT-based models, the former were better in data extraction with mean precision 83.0% (SD=10.4), and recall 86.0% (SD=9.8), while being slightly less accurate in title and abstract screening stage (Maccuracy=77.3%, SD=13.0). Discussion/Conclusion: Our LLM-assisted systematic review revealed a significant number of research projects related to review automation using LLMs. The results looked promising, and we anticipate that LLMs will change in the near future the way the scientific reviews are conducted.
Read more9/10/2024