An AI System Evaluation Framework for Advancing AI Safety: Terminology, Taxonomy, Lifecycle Mapping
2404.05388
0
0

Abstract
The advent of advanced AI underscores the urgent need for comprehensive safety evaluations, necessitating collaboration across communities (i.e., AI, software engineering, and governance). However, divergent practices and terminologies across these communities, combined with the complexity of AI systems-of which models are only a part-and environmental affordances (e.g., access to tools), obstruct effective communication and comprehensive evaluation. This paper proposes a framework for AI system evaluation comprising three components: 1) harmonised terminology to facilitate communication across communities involved in AI safety evaluation; 2) a taxonomy identifying essential elements for AI system evaluation; 3) a mapping between AI lifecycle, stakeholders, and requisite evaluations for accountable AI supply chain. This framework catalyses a deeper discourse on AI system evaluation beyond model-centric approaches.
Create account to get full access
Overview
- Presents a comprehensive taxonomy for evaluating the safety and reliability of AI systems
- Covers key aspects such as robustness, transparency, and value alignment
- Aims to provide a structured framework for assessing the safety and trustworthiness of advanced AI models
Plain English Explanation
This paper proposes a detailed taxonomy for evaluating the safety and reliability of AI systems. The researchers recognized the growing importance of ensuring AI models are safe, transparent, and aligned with human values as they become increasingly advanced and capable.
The taxonomy covers a wide range of factors, including the robustness of the AI system to distributional shift, its transparency and interpretability, and how well it is aligned with intended objectives and human values. By providing a structured framework for evaluation, the authors aim to help researchers and developers assess the safety and trustworthiness of their AI models more systematically.
Technical Explanation
The paper presents a comprehensive taxonomy for evaluating the safety and reliability of AI systems. The taxonomy covers five key dimensions: robustness, transparency, value alignment, control and oversight, and societal impact.
For each dimension, the authors define a set of specific evaluation criteria and provide guidance on how to assess them. For example, under robustness, they consider factors like sensitivity to distributional shift, adversarial vulnerability, and graceful degradation. The transparency dimension looks at interpretability, explainability, and auditability.
The authors argue that this structured approach to evaluation is essential as AI systems become more advanced and deployed in high-stakes domains. By assessing AI models across this broad set of criteria, developers and researchers can gain a more holistic understanding of their safety and reliability.
Critical Analysis
The taxonomy presented in this paper is a valuable contribution to the ongoing efforts to ensure the safety and trustworthiness of advanced AI systems. By covering a wide range of important factors, the authors have provided a comprehensive framework for evaluation.
However, the authors acknowledge that fully implementing and operationalizing this taxonomy may be challenging, particularly for more complex or opaque AI models. Additionally, some of the evaluation criteria, such as assessing value alignment, can be subjective and difficult to measure objectively.
Further research may be needed to refine the taxonomy, develop more standardized evaluation methods, and address potential limitations. Continued collaboration between AI developers, ethicists, and domain experts will be crucial to ensure the taxonomy remains relevant and effective as the field of AI rapidly evolves.
Conclusion
This paper presents a detailed taxonomy for evaluating the safety and reliability of AI systems. By considering factors such as robustness, transparency, value alignment, and societal impact, the taxonomy aims to provide a structured framework for assessing the trustworthiness of advanced AI models.
As AI systems become increasingly capable and widespread, the need for rigorous safety evaluation has never been more pressing. The authors' comprehensive approach to AI system assessment could help guide researchers and developers in their efforts to create more reliable and responsible AI technologies that can be safely deployed in high-stakes applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤖
Holistic Safety and Responsibility Evaluations of Advanced AI Models
Laura Weidinger, Joslyn Barnhart, Jenny Brennan, Christina Butterfield, Susie Young, Will Hawkins, Lisa Anne Hendricks, Ramona Comanescu, Oscar Chang, Mikel Rodriguez, Jennifer Beroshi, Dawn Bloxwich, Lev Proleev, Jilin Chen, Sebastian Farquhar, Lewis Ho, Iason Gabriel, Allan Dafoe, William Isaac
0
0
Safety and responsibility evaluations of advanced AI models are a critical but developing field of research and practice. In the development of Google DeepMind's advanced AI models, we innovated on and applied a broad set of approaches to safety evaluation. In this report, we summarise and share elements of our evolving approach as well as lessons learned for a broad audience. Key lessons learned include: First, theoretical underpinnings and frameworks are invaluable to organise the breadth of risk domains, modalities, forms, metrics, and goals. Second, theory and practice of safety evaluation development each benefit from collaboration to clarify goals, methods and challenges, and facilitate the transfer of insights between different stakeholders and disciplines. Third, similar key methods, lessons, and institutions apply across the range of concerns in responsibility and safety - including established and emerging harms. For this reason it is important that a wide range of actors working on safety evaluation and safety research communities work together to develop, refine and implement novel evaluation approaches and best practices, rather than operating in silos. The report concludes with outlining the clear need to rapidly advance the science of evaluations, to integrate new evaluations into the development and governance of AI, to establish scientifically-grounded norms and standards, and to promote a robust evaluation ecosystem.
4/23/2024
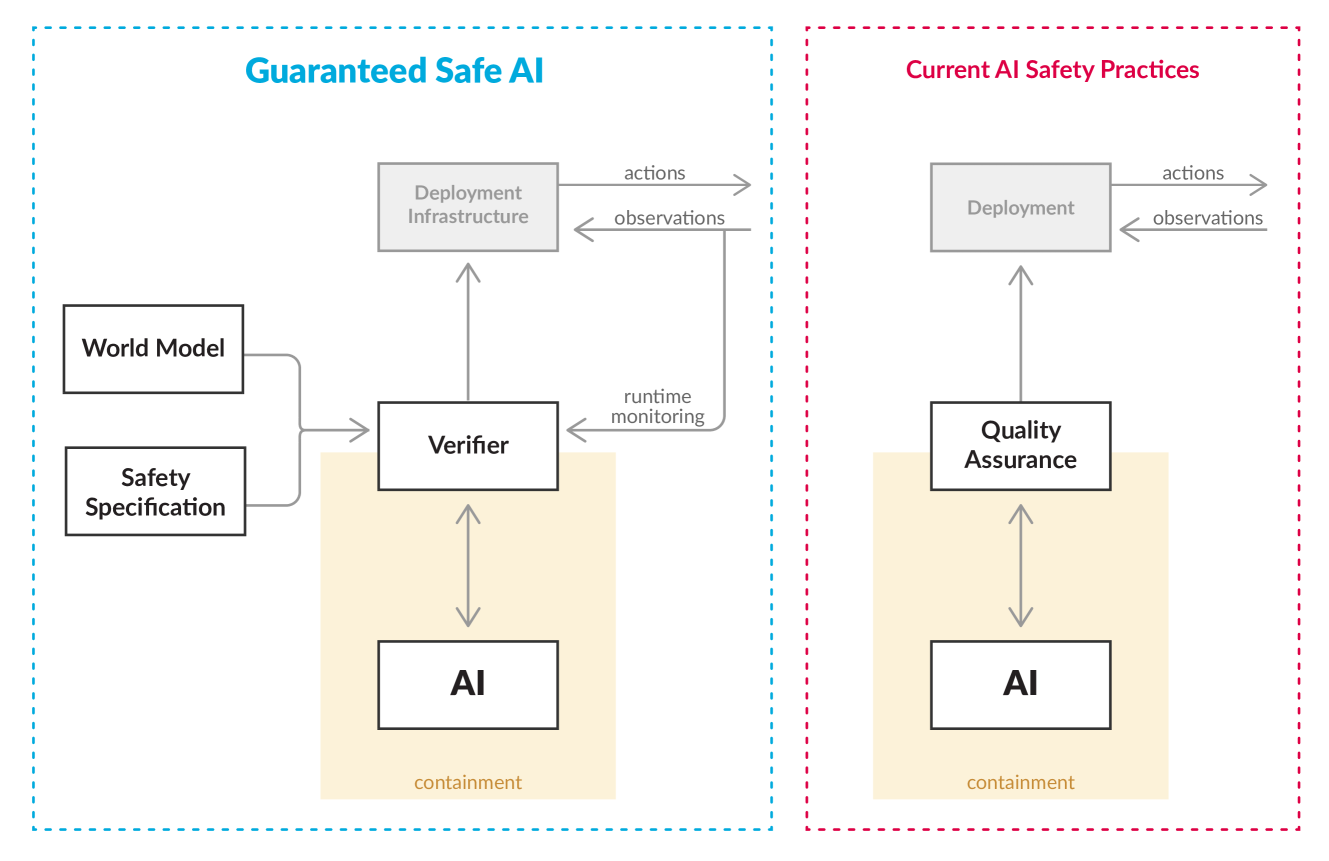
Towards Guaranteed Safe AI: A Framework for Ensuring Robust and Reliable AI Systems
David davidad Dalrymple, Joar Skalse, Yoshua Bengio, Stuart Russell, Max Tegmark, Sanjit Seshia, Steve Omohundro, Christian Szegedy, Ben Goldhaber, Nora Ammann, Alessandro Abate, Joe Halpern, Clark Barrett, Ding Zhao, Tan Zhi-Xuan, Jeannette Wing, Joshua Tenenbaum
0
0
Ensuring that AI systems reliably and robustly avoid harmful or dangerous behaviours is a crucial challenge, especially for AI systems with a high degree of autonomy and general intelligence, or systems used in safety-critical contexts. In this paper, we will introduce and define a family of approaches to AI safety, which we will refer to as guaranteed safe (GS) AI. The core feature of these approaches is that they aim to produce AI systems which are equipped with high-assurance quantitative safety guarantees. This is achieved by the interplay of three core components: a world model (which provides a mathematical description of how the AI system affects the outside world), a safety specification (which is a mathematical description of what effects are acceptable), and a verifier (which provides an auditable proof certificate that the AI satisfies the safety specification relative to the world model). We outline a number of approaches for creating each of these three core components, describe the main technical challenges, and suggest a number of potential solutions to them. We also argue for the necessity of this approach to AI safety, and for the inadequacy of the main alternative approaches.
5/20/2024

Human-AI Safety: A Descendant of Generative AI and Control Systems Safety
Andrea Bajcsy, Jaime F. Fisac
0
0
Artificial intelligence (AI) is interacting with people at an unprecedented scale, offering new avenues for immense positive impact, but also raising widespread concerns around the potential for individual and societal harm. Today, the predominant paradigm for human--AI safety focuses on fine-tuning the generative model's outputs to better agree with human-provided examples or feedback. In reality, however, the consequences of an AI model's outputs cannot be determined in isolation: they are tightly entangled with the responses and behavior of human users over time. In this paper, we distill key complementary lessons from AI safety and control systems safety, highlighting open challenges as well as key synergies between both fields. We then argue that meaningful safety assurances for advanced AI technologies require reasoning about how the feedback loop formed by AI outputs and human behavior may drive the interaction towards different outcomes. To this end, we introduce a unifying formalism to capture dynamic, safety-critical human--AI interactions and propose a concrete technical roadmap towards next-generation human-centered AI safety.
6/26/2024

Beyond static AI evaluations: advancing human interaction evaluations for LLM harms and risks
Lujain Ibrahim, Saffron Huang, Lama Ahmad, Markus Anderljung
0
0
Model evaluations are central to understanding the safety, risks, and societal impacts of AI systems. While most real-world AI applications involve human-AI interaction, most current evaluations (e.g., common benchmarks) of AI models do not. Instead, they incorporate human factors in limited ways, assessing the safety of models in isolation, thereby falling short of capturing the complexity of human-model interactions. In this paper, we discuss and operationalize a definition of an emerging category of evaluations -- human interaction evaluations (HIEs) -- which focus on the assessment of human-model interactions or the process and the outcomes of humans using models. First, we argue that HIEs can be used to increase the validity of safety evaluations, assess direct human impact and interaction-specific harms, and guide future assessments of models' societal impact. Second, we propose a safety-focused HIE design framework -- containing a human-LLM interaction taxonomy -- with three stages: (1) identifying the risk or harm area, (2) characterizing the use context, and (3) choosing the evaluation parameters. Third, we apply our framework to two potential evaluations for overreliance and persuasion risks. Finally, we conclude with tangible recommendations for addressing concerns over costs, replicability, and unrepresentativeness of HIEs.
5/28/2024