AIM: Attributing, Interpreting, Mitigating Data Unfairness
2406.08819
0
0

Abstract
Data collected in the real world often encapsulates historical discrimination against disadvantaged groups and individuals. Existing fair machine learning (FairML) research has predominantly focused on mitigating discriminative bias in the model prediction, with far less effort dedicated towards exploring how to trace biases present in the data, despite its importance for the transparency and interpretability of FairML. To fill this gap, we investigate a novel research problem: discovering samples that reflect biases/prejudices from the training data. Grounding on the existing fairness notions, we lay out a sample bias criterion and propose practical algorithms for measuring and countering sample bias. The derived bias score provides intuitive sample-level attribution and explanation of historical bias in data. On this basis, we further design two FairML strategies via sample-bias-informed minimal data editing. They can mitigate both group and individual unfairness at the cost of minimal or zero predictive utility loss. Extensive experiments and analyses on multiple real-world datasets demonstrate the effectiveness of our methods in explaining and mitigating unfairness. Code is available at https://github.com/ZhiningLiu1998/AIM.
Create account to get full access
Overview
- This paper, titled "AIM: Attributing, Interpreting, Mitigating Data Unfairness," explores techniques for identifying, understanding, and addressing unfairness in machine learning (ML) models.
- The researchers propose a framework called AIM that combines three key components: attribution, interpretation, and mitigation of data unfairness.
- The goal is to provide a comprehensive approach to tackle the challenging problem of fairness in AI systems.
Plain English Explanation
The paper focuses on a critical issue in machine learning: unfairness. Machine learning models can sometimes make decisions or predictions that are biased against certain groups of people, leading to unfair outcomes. This can happen due to biases in the data used to train the models.
The researchers developed a framework called AIM to help address this problem. AIM stands for "Attributing, Interpreting, Mitigating," which are the three key components of their approach:
-
Attribution: This involves identifying the specific features or characteristics in the data that are contributing to unfairness in the model's outputs. By understanding what is causing the unfairness, the researchers can then work on addressing it.
-
Interpretation: The next step is to interpret how the identified features are leading to unfair outcomes. This provides deeper insights into the underlying mechanisms driving the unfairness, which is crucial for developing effective solutions.
-
Mitigation: Finally, the researchers explore ways to mitigate the unfairness by modifying the model or the training data. This could involve techniques like adjusting the model's parameters or actively sampling data to address biases.
The overall goal of the AIM framework is to give researchers and developers a comprehensive set of tools to identify, understand, and ultimately reduce unfairness in their AI systems. By taking a more holistic approach, they aim to create fairer and more equitable machine learning models.
Technical Explanation
The paper begins by outlining the key challenges in addressing fairness in machine learning, including the difficulty of defining and measuring fairness, as well as the potential for unintended consequences when attempting to mitigate unfairness as discussed in this related paper.
The researchers then introduce the AIM framework, which consists of three main components:
-
Attribution: The attribution module aims to identify the specific features or characteristics in the data that are contributing to unfairness in the model's outputs. The authors propose using techniques like Shapley value analysis to quantify the influence of each feature on the model's fairness.
-
Interpretation: The interpretation module involves analyzing the identified features to understand how they are leading to unfair outcomes. This could include techniques like sensitivity analysis to measure the model's responsiveness to changes in the features.
-
Mitigation: The mitigation module explores ways to reduce the unfairness in the model, such as adjusting the model's parameters or actively sampling data to address biases.
The paper includes detailed experiments and case studies that demonstrate the effectiveness of the AIM framework in identifying, understanding, and mitigating unfairness in various machine learning tasks and datasets.
Critical Analysis
The AIM framework proposed in this paper represents a comprehensive and systematic approach to addressing the complex challenge of fairness in machine learning. By integrating attribution, interpretation, and mitigation, the researchers aim to provide a more holistic solution than previous work that has often focused on only one or two of these aspects.
One potential limitation of the framework is that it may be computationally intensive, especially for large and complex machine learning models. The authors acknowledge this and suggest that future work should explore ways to make the AIM process more efficient and scalable.
Additionally, the paper does not fully address the potential for unintended consequences when attempting to mitigate unfairness, as discussed in this related paper. It would be valuable for the researchers to further explore this issue and provide guidance on how to navigate the sometimes complex trade-offs between reducing unfairness and preserving other desirable model properties.
Despite these potential limitations, the AIM framework represents a significant contribution to the field of fairness in AI. By providing a structured and comprehensive approach, the researchers have made important strides towards developing more equitable and trustworthy machine learning systems.
Conclusion
The "AIM: Attributing, Interpreting, Mitigating Data Unfairness" paper presents a novel framework for identifying, understanding, and addressing unfairness in machine learning models. By combining attribution, interpretation, and mitigation, the researchers offer a comprehensive approach to this critical challenge facing the AI community.
The framework's potential to provide deeper insights into the underlying causes of unfairness, as well as practical strategies for mitigating it, could have important implications for the development of fairer and more equitable AI systems. While the approach may face some practical limitations, the paper represents a valuable contribution to the ongoing efforts to ensure that machine learning is used in a responsible and ethical manner.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Towards Standardizing AI Bias Exploration
Emmanouil Krasanakis, Symeon Papadopoulos
0
0
Creating fair AI systems is a complex problem that involves the assessment of context-dependent bias concerns. Existing research and programming libraries express specific concerns as measures of bias that they aim to constrain or mitigate. In practice, one should explore a wide variety of (sometimes incompatible) measures before deciding which ones warrant corrective action, but their narrow scope means that most new situations can only be examined after devising new measures. In this work, we present a mathematical framework that distils literature measures of bias into building blocks, hereby facilitating new combinations to cover a wide range of fairness concerns, such as classification or recommendation differences across multiple multi-value sensitive attributes (e.g., many genders and races, and their intersections). We show how this framework generalizes existing concepts and present frequently used blocks. We provide an open-source implementation of our framework as a Python library, called FairBench, that facilitates systematic and extensible exploration of potential bias concerns.
5/30/2024
🌐
When mitigating bias is unfair: multiplicity and arbitrariness in algorithmic group fairness
Natasa Krco, Thibault Laugel, Vincent Grari, Jean-Michel Loubes, Marcin Detyniecki
0
0
Most research on fair machine learning has prioritized optimizing criteria such as Demographic Parity and Equalized Odds. Despite these efforts, there remains a limited understanding of how different bias mitigation strategies affect individual predictions and whether they introduce arbitrariness into the debiasing process. This paper addresses these gaps by exploring whether models that achieve comparable fairness and accuracy metrics impact the same individuals and mitigate bias in a consistent manner. We introduce the FRAME (FaiRness Arbitrariness and Multiplicity Evaluation) framework, which evaluates bias mitigation through five dimensions: Impact Size (how many people were affected), Change Direction (positive versus negative changes), Decision Rates (impact on models' acceptance rates), Affected Subpopulations (who was affected), and Neglected Subpopulations (where unfairness persists). This framework is intended to help practitioners understand the impacts of debiasing processes and make better-informed decisions regarding model selection. Applying FRAME to various bias mitigation approaches across key datasets allows us to exhibit significant differences in the behaviors of debiasing methods. These findings highlight the limitations of current fairness criteria and the inherent arbitrariness in the debiasing process.
5/24/2024
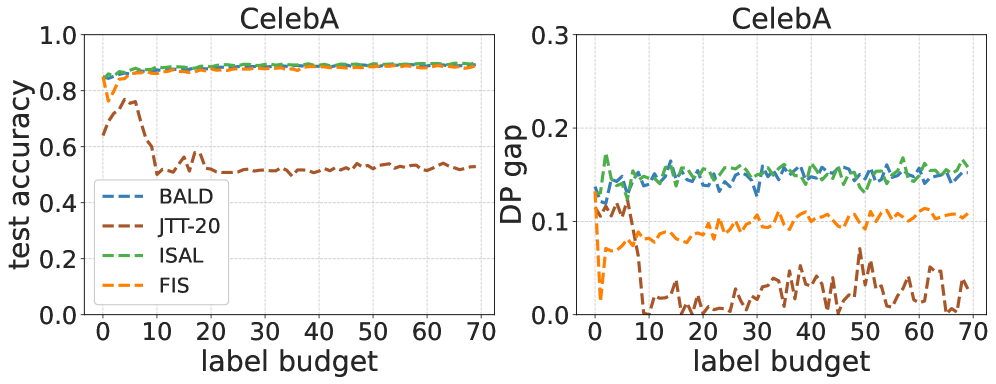
Fairness Without Harm: An Influence-Guided Active Sampling Approach
Jinlong Pang, Jialu Wang, Zhaowei Zhu, Yuanshun Yao, Chen Qian, Yang Liu
0
0
The pursuit of fairness in machine learning (ML), ensuring that the models do not exhibit biases toward protected demographic groups, typically results in a compromise scenario. This compromise can be explained by a Pareto frontier where given certain resources (e.g., data), reducing the fairness violations often comes at the cost of lowering the model accuracy. In this work, we aim to train models that mitigate group fairness disparity without causing harm to model accuracy. Intuitively, acquiring more data is a natural and promising approach to achieve this goal by reaching a better Pareto frontier of the fairness-accuracy tradeoff. The current data acquisition methods, such as fair active learning approaches, typically require annotating sensitive attributes. However, these sensitive attribute annotations should be protected due to privacy and safety concerns. In this paper, we propose a tractable active data sampling algorithm that does not rely on training group annotations, instead only requiring group annotations on a small validation set. Specifically, the algorithm first scores each new example by its influence on fairness and accuracy evaluated on the validation dataset, and then selects a certain number of examples for training. We theoretically analyze how acquiring more data can improve fairness without causing harm, and validate the possibility of our sampling approach in the context of risk disparity. We also provide the upper bound of generalization error and risk disparity as well as the corresponding connections. Extensive experiments on real-world data demonstrate the effectiveness of our proposed algorithm.
6/4/2024

Measuring and Mitigating Bias for Tabular Datasets with Multiple Protected Attributes
Manh Khoi Duong, Stefan Conrad
0
0
Motivated by the recital (67) of the current corrigendum of the AI Act in the European Union, we propose and present measures and mitigation strategies for discrimination in tabular datasets. We specifically focus on datasets that contain multiple protected attributes, such as nationality, age, and sex. This makes measuring and mitigating bias more challenging, as many existing methods are designed for a single protected attribute. This paper comes with a twofold contribution: Firstly, new discrimination measures are introduced. These measures are categorized in our framework along with existing ones, guiding researchers and practitioners in choosing the right measure to assess the fairness of the underlying dataset. Secondly, a novel application of an existing bias mitigation method, FairDo, is presented. We show that this strategy can mitigate any type of discrimination, including intersectional discrimination, by transforming the dataset. By conducting experiments on real-world datasets (Adult, Bank, Compas), we demonstrate that de-biasing datasets with multiple protected attributes is achievable. Further, the transformed fair datasets do not compromise any of the tested machine learning models' performances significantly when trained on these datasets compared to the original datasets. Discrimination was reduced by up to 83% in our experimentation. For most experiments, the disparity between protected groups was reduced by at least 7% and 27% on average. Generally, the findings show that the mitigation strategy used is effective, and this study contributes to the ongoing discussion on the implementation of the European Union's AI Act.
5/30/2024