Fairness Without Harm: An Influence-Guided Active Sampling Approach
2402.12789
0
0
Abstract
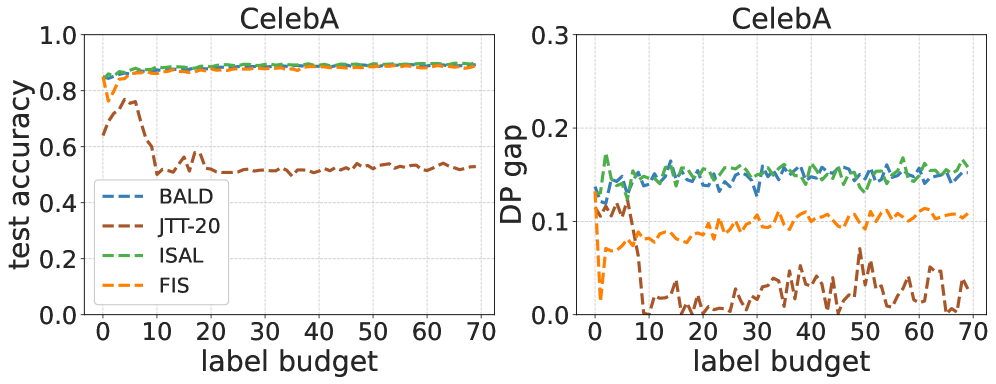
The pursuit of fairness in machine learning (ML), ensuring that the models do not exhibit biases toward protected demographic groups, typically results in a compromise scenario. This compromise can be explained by a Pareto frontier where given certain resources (e.g., data), reducing the fairness violations often comes at the cost of lowering the model accuracy. In this work, we aim to train models that mitigate group fairness disparity without causing harm to model accuracy. Intuitively, acquiring more data is a natural and promising approach to achieve this goal by reaching a better Pareto frontier of the fairness-accuracy tradeoff. The current data acquisition methods, such as fair active learning approaches, typically require annotating sensitive attributes. However, these sensitive attribute annotations should be protected due to privacy and safety concerns. In this paper, we propose a tractable active data sampling algorithm that does not rely on training group annotations, instead only requiring group annotations on a small validation set. Specifically, the algorithm first scores each new example by its influence on fairness and accuracy evaluated on the validation dataset, and then selects a certain number of examples for training. We theoretically analyze how acquiring more data can improve fairness without causing harm, and validate the possibility of our sampling approach in the context of risk disparity. We also provide the upper bound of generalization error and risk disparity as well as the corresponding connections. Extensive experiments on real-world data demonstrate the effectiveness of our proposed algorithm.
Create account to get full access
Overview
- This paper proposes an influence-guided data sampling approach to train fair machine learning classifiers without relying on fair training data.
- The key idea is to identify and sample data points that have a high influence on the model's fairness, rather than just its accuracy.
- This approach aims to address the challenge of obtaining truly representative and unbiased training data, which is a common obstacle in achieving fairness in AI systems.
Plain English Explanation
The paper focuses on the problem of making machine learning models fair, which means ensuring they don't discriminate against certain groups of people. Typically, to train a fair model, you need to have training data that is already fair and representative of different groups. However, finding such data can be very difficult in the real world.
The researchers propose a new approach that doesn't rely on having fair training data. Instead, they find the data points that have the biggest influence on the model's fairness, and focus on sampling more of those points during training. This helps the model learn to be fair, even if the original training data isn't perfectly balanced.
The key insight is that some data points matter more than others when it comes to fairness. By identifying and focusing on the most influential data, the researchers can train a fair model without needing to start with perfectly fair data. This could be a valuable technique for building fair AI systems in the real world, where ideal data is often hard to come by.
Technical Explanation
The paper introduces an "influence-guided data sampling" approach to train fair machine learning classifiers without relying on fair training data. The core idea is to identify and sample data points that have a high influence on the model's fairness, rather than just its accuracy.
Specifically, the authors propose using an influence function to measure the impact of each training data point on the model's fairness metric (e.g., demographic parity, equal opportunity). They then use this influence information to guide the data sampling process during training, prioritizing points that are most critical for improving fairness.
This influence-guided sampling is combined with standard training techniques like stochastic gradient descent. The authors evaluate their approach on several benchmark datasets and find that it can achieve comparable or better fairness performance compared to training on perfectly balanced data or using existing fairness-aware techniques.
The key advantage of this approach is that it sidesteps the challenge of obtaining truly representative and unbiased training data, which is a common obstacle in achieving fairness in AI systems. By focusing on the most influential data points, the model can learn to be fair even when the original training data is biased or imbalanced.
Critical Analysis
The paper presents a novel and promising approach to training fair machine learning models without relying on fair training data. The influence-guided sampling technique is a clever way to address the data challenge, and the empirical results demonstrate its effectiveness.
However, the authors acknowledge several limitations and caveats. First, the approach relies on being able to compute influence functions, which can be computationally expensive and may not scale well to very large datasets. There are also open questions around how to best define and measure the influence on fairness metrics.
Additionally, the paper only considers binary classification tasks and a limited set of fairness metrics. It's unclear how the approach would generalize to more complex models, tasks, or fairness notions. There may also be edge cases or pathological datasets where the influence-guided sampling strategy could fail to find a fair solution.
Further research is needed to better understand the broader applicability and limitations of this approach. Exploring alternative fairness-aware sampling techniques, quantifying the tradeoffs with accuracy, and studying real-world deployment scenarios would all be valuable next steps.
Overall, this paper presents an important step towards more practical and scalable methods for building fair AI systems. By shifting the focus from fair data to fair model training, it opens up new avenues for addressing the challenging problem of algorithmic fairness.
Conclusion
This paper proposes an innovative approach to training fair machine learning classifiers without relying on fair training data. The key idea is to identify and sample the data points that have the greatest influence on the model's fairness, rather than just its accuracy.
This influence-guided sampling technique sidesteps the common challenge of obtaining truly representative and unbiased training data, which is crucial for achieving fairness in AI systems. The authors demonstrate the effectiveness of their approach on several benchmark datasets, showing that it can match or exceed the fairness performance of models trained on perfectly balanced data.
While the approach has some limitations and caveats, it represents an important advance in the field of algorithmic fairness. By shifting the focus from fair data to fair model training, it opens up new possibilities for building fair AI systems in the real world, where ideal data is often hard to come by.
Overall, this research highlights the value of creative problem-solving and the importance of looking beyond the obvious solutions when it comes to complex challenges like ensuring fairness in machine learning. As AI systems become increasingly pervasive, techniques like this will be crucial for building equitable and trustworthy technologies that benefit all of society.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

AIM: Attributing, Interpreting, Mitigating Data Unfairness
Zhining Liu, Ruizhong Qiu, Zhichen Zeng, Yada Zhu, Hendrik Hamann, Hanghang Tong
0
0
Data collected in the real world often encapsulates historical discrimination against disadvantaged groups and individuals. Existing fair machine learning (FairML) research has predominantly focused on mitigating discriminative bias in the model prediction, with far less effort dedicated towards exploring how to trace biases present in the data, despite its importance for the transparency and interpretability of FairML. To fill this gap, we investigate a novel research problem: discovering samples that reflect biases/prejudices from the training data. Grounding on the existing fairness notions, we lay out a sample bias criterion and propose practical algorithms for measuring and countering sample bias. The derived bias score provides intuitive sample-level attribution and explanation of historical bias in data. On this basis, we further design two FairML strategies via sample-bias-informed minimal data editing. They can mitigate both group and individual unfairness at the cost of minimal or zero predictive utility loss. Extensive experiments and analyses on multiple real-world datasets demonstrate the effectiveness of our methods in explaining and mitigating unfairness. Code is available at https://github.com/ZhiningLiu1998/AIM.
6/19/2024
🏅
Fair Active Learning: Solving the Labeling Problem in Insurance
Romuald Elie, Caroline Hillairet, Franc{c}ois Hu, Marc Juillard
0
0
This paper addresses significant obstacles that arise from the widespread use of machine learning models in the insurance industry, with a specific focus on promoting fairness. The initial challenge lies in effectively leveraging unlabeled data in insurance while reducing the labeling effort and emphasizing data relevance through active learning techniques. The paper explores various active learning sampling methodologies and evaluates their impact on both synthetic and real insurance datasets. This analysis highlights the difficulty of achieving fair model inferences, as machine learning models may replicate biases and discrimination found in the underlying data. To tackle these interconnected challenges, the paper introduces an innovative fair active learning method. The proposed approach samples informative and fair instances, achieving a good balance between model predictive performance and fairness, as confirmed by numerical experiments on insurance datasets.
5/21/2024
📊
Trusting Fair Data: Leveraging Quality in Fairness-Driven Data Removal Techniques
Manh Khoi Duong, Stefan Conrad
0
0
In this paper, we deal with bias mitigation techniques that remove specific data points from the training set to aim for a fair representation of the population in that set. Machine learning models are trained on these pre-processed datasets, and their predictions are expected to be fair. However, such approaches may exclude relevant data, making the attained subsets less trustworthy for further usage. To enhance the trustworthiness of prior methods, we propose additional requirements and objectives that the subsets must fulfill in addition to fairness: (1) group coverage, and (2) minimal data loss. While removing entire groups may improve the measured fairness, this practice is very problematic as failing to represent every group cannot be considered fair. In our second concern, we advocate for the retention of data while minimizing discrimination. By introducing a multi-objective optimization problem that considers fairness and data loss, we propose a methodology to find Pareto-optimal solutions that balance these objectives. By identifying such solutions, users can make informed decisions about the trade-off between fairness and data quality and select the most suitable subset for their application.
6/12/2024
🌐
Fairness Without Demographics in Human-Centered Federated Learning
Shaily Roy, Harshit Sharma, Asif Salekin
0
0
Federated learning (FL) enables collaborative model training while preserving data privacy, making it suitable for decentralized human-centered AI applications. However, a significant research gap remains in ensuring fairness in these systems. Current fairness strategies in FL require knowledge of bias-creating/sensitive attributes, clashing with FL's privacy principles. Moreover, in human-centered datasets, sensitive attributes may remain latent. To tackle these challenges, we present a novel bias mitigation approach inspired by Fairness without Demographics in machine learning. The presented approach achieves fairness without needing knowledge of sensitive attributes by minimizing the top eigenvalue of the Hessian matrix during training, ensuring equitable loss landscapes across FL participants. Notably, we introduce a novel FL aggregation scheme that promotes participating models based on error rates and loss landscape curvature attributes, fostering fairness across the FL system. This work represents the first approach to attaining Fairness without Demographics in human-centered FL. Through comprehensive evaluation, our approach demonstrates effectiveness in balancing fairness and efficacy across various real-world applications, FL setups, and scenarios involving single and multiple bias-inducing factors, representing a significant advancement in human-centered FL.
5/17/2024