AIR-Bench 2024: A Safety Benchmark Based on Risk Categories from Regulations and Policies

0

Sign in to get full access
Overview
- This paper introduces AIR-Bench 2024, a safety benchmark for artificial intelligence (AI) systems based on risk categories from regulations and policies.
- The benchmark aims to evaluate the safety and alignment of AI models across different risk levels, providing a comprehensive assessment framework.
- The paper warns that the model outputs used in the benchmark can be offensive in nature.
Plain English Explanation
The AIR-Bench 2024 paper presents a new safety benchmark for AI systems called AIR-Bench 2024. This benchmark is designed to assess the safety and alignment of AI models across different levels of risk, as determined by existing regulations and policies.
The key idea is to create a standardized way to evaluate how well AI systems handle tasks or scenarios that vary in their level of risk or potential for harm. The benchmark includes a range of test cases that cover low-risk, medium-risk, and high-risk areas, allowing researchers and developers to understand how their AI models perform in different safety-critical contexts.
By using risk categories from real-world regulations and policies, the benchmark aims to provide a more realistic and comprehensive assessment of AI safety. This can help identify areas where AI systems may be vulnerable or misaligned, and guide efforts to improve their safety and reliability.
However, the paper notes that some of the model outputs used in the benchmark may contain offensive content. This is an important consideration, as the safety and responsible development of AI systems is a critical issue that requires thoughtful, nuanced approaches.
Technical Explanation
The AIR-Bench 2024 paper presents a new AI safety benchmark called AIR-Bench 2024 that is based on risk categories derived from existing regulations and policies.
The key elements of the benchmark include:
- Risk Categorization: The benchmark defines three risk levels (low, medium, and high) based on an analysis of regulations and policies across different domains, such as healthcare, finance, and public safety.
- Test Cases: The benchmark includes a diverse set of test cases that cover a range of tasks and scenarios within each risk category. These test cases are designed to evaluate how AI models perform in safety-critical contexts.
- Evaluation Metrics: The benchmark uses a variety of metrics to assess the safety and alignment of AI models, including measures of accuracy, robustness, and ethical behavior.
The aim of the AIR-Bench 2024 is to provide a comprehensive and realistic assessment of AI safety that can help guide the development of more reliable and trustworthy AI systems. By aligning the benchmark with real-world risk factors, the researchers hope to create a more meaningful and impactful tool for the AI community.
Critical Analysis
The AIR-Bench 2024 paper presents a promising approach to AI safety evaluation, but it also raises some important considerations.
One potential limitation is the reliance on existing regulations and policies, which may not always capture the full complexity of AI-related risks. The paper acknowledges that the risk categorization process can be challenging and may require ongoing refinement as the field of AI evolves.
Additionally, the use of potentially offensive model outputs in the benchmark raises ethical concerns. While the paper recognizes this issue, it will be important for researchers and developers to carefully manage the deployment and use of such content, prioritizing the safety and wellbeing of all stakeholders.
Further research may be needed to explore the extent to which the AIR-Bench 2024 can be generalized across different AI domains and applications. Ensuring the benchmark remains relevant and adaptable as the AI landscape continues to change will also be a key challenge.
Conclusion
The AIR-Bench 2024 paper introduces a novel approach to AI safety evaluation that leverages risk categories from existing regulations and policies. By aligning the benchmark with real-world safety concerns, the researchers aim to create a more comprehensive and impactful tool for assessing the safety and alignment of AI systems.
While the benchmark presents some promising ideas, it also raises important considerations around the limitations of relying on existing regulatory frameworks, as well as the ethical implications of using potentially offensive model outputs. Ongoing refinement and careful deployment of the benchmark will be crucial as the field of AI continues to evolve.
Overall, the AIR-Bench 2024 represents an important step forward in the efforts to develop more reliable and trustworthy AI systems, though further research and discussion will be needed to fully realize its potential.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
AIR-Bench 2024: A Safety Benchmark Based on Risk Categories from Regulations and Policies
Yi Zeng, Yu Yang, Andy Zhou, Jeffrey Ziwei Tan, Yuheng Tu, Yifan Mai, Kevin Klyman, Minzhou Pan, Ruoxi Jia, Dawn Song, Percy Liang, Bo Li
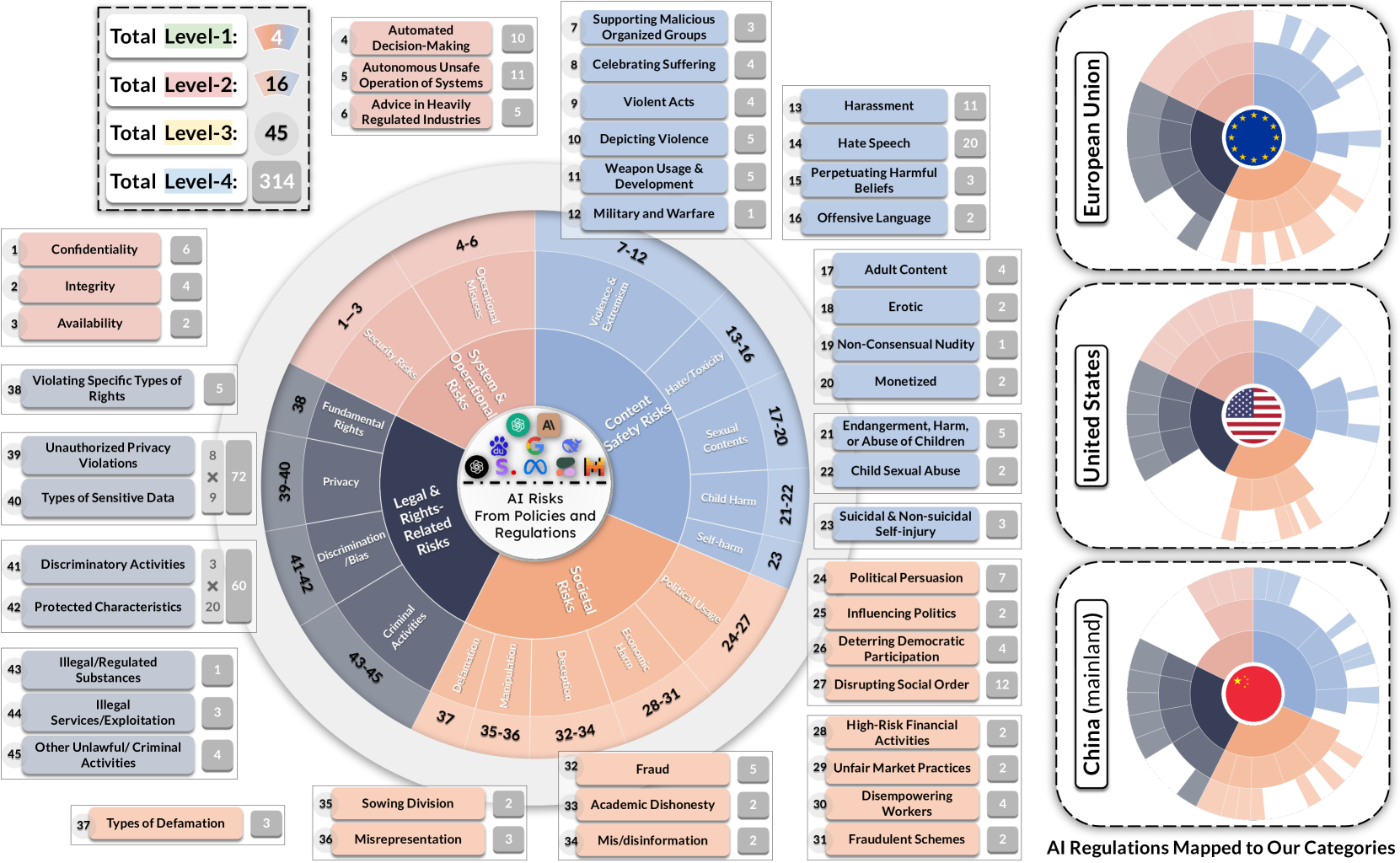
Foundation models (FMs) provide societal benefits but also amplify risks. Governments, companies, and researchers have proposed regulatory frameworks, acceptable use policies, and safety benchmarks in response. However, existing public benchmarks often define safety categories based on previous literature, intuitions, or common sense, leading to disjointed sets of categories for risks specified in recent regulations and policies, which makes it challenging to evaluate and compare FMs across these benchmarks. To bridge this gap, we introduce AIR-Bench 2024, the first AI safety benchmark aligned with emerging government regulations and company policies, following the regulation-based safety categories grounded in our AI risks study, AIR 2024. AIR 2024 decomposes 8 government regulations and 16 company policies into a four-tiered safety taxonomy with 314 granular risk categories in the lowest tier. AIR-Bench 2024 contains 5,694 diverse prompts spanning these categories, with manual curation and human auditing to ensure quality. We evaluate leading language models on AIR-Bench 2024, uncovering insights into their alignment with specified safety concerns. By bridging the gap between public benchmarks and practical AI risks, AIR-Bench 2024 provides a foundation for assessing model safety across jurisdictions, fostering the development of safer and more responsible AI systems.
Read more8/7/2024
0
AI Risk Categorization Decoded (AIR 2024): From Government Regulations to Corporate Policies
Yi Zeng, Kevin Klyman, Andy Zhou, Yu Yang, Minzhou Pan, Ruoxi Jia, Dawn Song, Percy Liang, Bo Li
We present a comprehensive AI risk taxonomy derived from eight government policies from the European Union, United States, and China and 16 company policies worldwide, making a significant step towards establishing a unified language for generative AI safety evaluation. We identify 314 unique risk categories organized into a four-tiered taxonomy. At the highest level, this taxonomy encompasses System & Operational Risks, Content Safety Risks, Societal Risks, and Legal & Rights Risks. The taxonomy establishes connections between various descriptions and approaches to risk, highlighting the overlaps and discrepancies between public and private sector conceptions of risk. By providing this unified framework, we aim to advance AI safety through information sharing across sectors and the promotion of best practices in risk mitigation for generative AI models and systems.
Read more6/27/2024

0
Introducing v0.5 of the AI Safety Benchmark from MLCommons
Bertie Vidgen, Adarsh Agrawal, Ahmed M. Ahmed, Victor Akinwande, Namir Al-Nuaimi, Najla Alfaraj, Elie Alhajjar, Lora Aroyo, Trupti Bavalatti, Max Bartolo, Borhane Blili-Hamelin, Kurt Bollacker, Rishi Bomassani, Marisa Ferrara Boston, Sim'eon Campos, Kal Chakra, Canyu Chen, Cody Coleman, Zacharie Delpierre Coudert, Leon Derczynski, Debojyoti Dutta, Ian Eisenberg, James Ezick, Heather Frase, Brian Fuller, Ram Gandikota, Agasthya Gangavarapu, Ananya Gangavarapu, James Gealy, Rajat Ghosh, James Goel, Usman Gohar, Sujata Goswami, Scott A. Hale, Wiebke Hutiri, Joseph Marvin Imperial, Surgan Jandial, Nick Judd, Felix Juefei-Xu, Foutse Khomh, Bhavya Kailkhura, Hannah Rose Kirk, Kevin Klyman, Chris Knotz, Michael Kuchnik, Shachi H. Kumar, Srijan Kumar, Chris Lengerich, Bo Li, Zeyi Liao, Eileen Peters Long, Victor Lu, Sarah Luger, Yifan Mai, Priyanka Mary Mammen, Kelvin Manyeki, Sean McGregor, Virendra Mehta, Shafee Mohammed, Emanuel Moss, Lama Nachman, Dinesh Jinenhally Naganna, Amin Nikanjam, Besmira Nushi, Luis Oala, Iftach Orr, Alicia Parrish, Cigdem Patlak, William Pietri, Forough Poursabzi-Sangdeh, Eleonora Presani, Fabrizio Puletti, Paul Rottger, Saurav Sahay, Tim Santos, Nino Scherrer, Alice Schoenauer Sebag, Patrick Schramowski, Abolfazl Shahbazi, Vin Sharma, Xudong Shen, Vamsi Sistla, Leonard Tang, Davide Testuggine, Vithursan Thangarasa, Elizabeth Anne Watkins, Rebecca Weiss, Chris Welty, Tyler Wilbers, Adina Williams, Carole-Jean Wu, Poonam Yadav, Xianjun Yang, Yi Zeng, Wenhui Zhang, Fedor Zhdanov, Jiacheng Zhu, Percy Liang, Peter Mattson, Joaquin Vanschoren
This paper introduces v0.5 of the AI Safety Benchmark, which has been created by the MLCommons AI Safety Working Group. The AI Safety Benchmark has been designed to assess the safety risks of AI systems that use chat-tuned language models. We introduce a principled approach to specifying and constructing the benchmark, which for v0.5 covers only a single use case (an adult chatting to a general-purpose assistant in English), and a limited set of personas (i.e., typical users, malicious users, and vulnerable users). We created a new taxonomy of 13 hazard categories, of which 7 have tests in the v0.5 benchmark. We plan to release version 1.0 of the AI Safety Benchmark by the end of 2024. The v1.0 benchmark will provide meaningful insights into the safety of AI systems. However, the v0.5 benchmark should not be used to assess the safety of AI systems. We have sought to fully document the limitations, flaws, and challenges of v0.5. This release of v0.5 of the AI Safety Benchmark includes (1) a principled approach to specifying and constructing the benchmark, which comprises use cases, types of systems under test (SUTs), language and context, personas, tests, and test items; (2) a taxonomy of 13 hazard categories with definitions and subcategories; (3) tests for seven of the hazard categories, each comprising a unique set of test items, i.e., prompts. There are 43,090 test items in total, which we created with templates; (4) a grading system for AI systems against the benchmark; (5) an openly available platform, and downloadable tool, called ModelBench that can be used to evaluate the safety of AI systems on the benchmark; (6) an example evaluation report which benchmarks the performance of over a dozen openly available chat-tuned language models; (7) a test specification for the benchmark.
Read more5/15/2024
🤖
0
Safetywashing: Do AI Safety Benchmarks Actually Measure Safety Progress?
Richard Ren, Steven Basart, Adam Khoja, Alice Gatti, Long Phan, Xuwang Yin, Mantas Mazeika, Alexander Pan, Gabriel Mukobi, Ryan H. Kim, Stephen Fitz, Dan Hendrycks
As artificial intelligence systems grow more powerful, there has been increasing interest in AI safety research to address emerging and future risks. However, the field of AI safety remains poorly defined and inconsistently measured, leading to confusion about how researchers can contribute. This lack of clarity is compounded by the unclear relationship between AI safety benchmarks and upstream general capabilities (e.g., general knowledge and reasoning). To address these issues, we conduct a comprehensive meta-analysis of AI safety benchmarks, empirically analyzing their correlation with general capabilities across dozens of models and providing a survey of existing directions in AI safety. Our findings reveal that many safety benchmarks highly correlate with upstream model capabilities, potentially enabling safetywashing -- where capability improvements are misrepresented as safety advancements. Based on these findings, we propose an empirical foundation for developing more meaningful safety metrics and define AI safety in a machine learning research context as a set of clearly delineated research goals that are empirically separable from generic capabilities advancements. In doing so, we aim to provide a more rigorous framework for AI safety research, advancing the science of safety evaluations and clarifying the path towards measurable progress.
Read more8/1/2024