AKBR: Learning Adaptive Kernel-based Representations for Graph Classification

0

Sign in to get full access
Overview
- The paper presents a novel graph representation learning method called AKBR (Adaptive Kernel-based Representations) for graph classification tasks.
- AKBR learns adaptive kernel-based graph representations that capture both structural and attribute information of graphs.
- The approach outperforms state-of-the-art graph classification methods on several benchmark datasets.
Plain English Explanation
In graph classification, the goal is to categorize graphs (e.g., chemical molecules, social networks) into different classes based on their structural and attribute properties. Classical graph kernels have been widely used for this task, but they often struggle to capture complex relationships within graphs.
The AKBR method proposed in this paper aims to learn more expressive graph representations by adaptively combining different kernel functions. The key idea is to automatically learn the optimal combination of kernel functions that best captures the unique characteristics of each input graph. This allows AKBR to be more flexible and effective than using a single fixed kernel.
The authors demonstrate that AKBR outperforms state-of-the-art graph classification methods on several benchmark datasets, indicating its ability to learn powerful representations for this task.
Technical Explanation
The AKBR framework consists of two main components:
-
Adaptive Kernel Combination: AKBR learns a set of kernel functions and their corresponding weights, which are adaptively combined to capture the structural and attribute information of the input graphs. This allows the model to automatically determine the optimal kernel combination for each dataset.
-
Graph Representation Learning: AKBR uses the learned kernel combination to compute a kernel matrix for the input graphs, which is then used to generate a vector representation for each graph. These representations are then fed into a classifier for the final graph classification task.
The authors evaluate AKBR on several benchmark graph classification datasets and compare its performance to existing graph kernel and representation learning methods. The results show that AKBR consistently outperforms the baselines, demonstrating its effectiveness in learning adaptive and expressive graph representations.
Critical Analysis
The paper provides a novel and promising approach for graph representation learning, addressing the limitations of classical graph kernels. However, some potential areas for further research include:
- Exploring the interpretability of the learned kernel combinations and their connection to the underlying graph properties.
- Investigating the scalability of AKBR to larger and more complex graph datasets.
- Incorporating additional inductive biases or domain-specific knowledge to further enhance the learned representations.
Overall, the AKBR method presents an interesting advancement in the field of graph classification and represents a valuable contribution to the ongoing research in graph representation learning.
Conclusion
The AKBR framework introduces an adaptive kernel-based approach for learning effective graph representations, which outperforms state-of-the-art methods on several benchmark graph classification tasks. By automatically learning the optimal combination of kernel functions, AKBR can capture the unique structural and attribute characteristics of input graphs, leading to improved classification performance. This work demonstrates the potential of adaptive kernel-based approaches in the broader field of graph representation learning and analysis.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
AKBR: Learning Adaptive Kernel-based Representations for Graph Classification
Feifei Qian, Lixin Cui, Ming Li, Yue Wang, Hangyuan Du, Lixiang Xu, Lu Bai, Philip S. Yu, Edwin R. Hancock
In this paper, we propose a new model to learn Adaptive Kernel-based Representations (AKBR) for graph classification. Unlike state-of-the-art R-convolution graph kernels that are defined by merely counting any pair of isomorphic substructures between graphs and cannot provide an end-to-end learning mechanism for the classifier, the proposed AKBR approach aims to define an end-to-end representation learning model to construct an adaptive kernel matrix for graphs. To this end, we commence by leveraging a novel feature-channel attention mechanism to capture the interdependencies between different substructure invariants of original graphs. The proposed AKBR model can thus effectively identify the structural importance of different substructures, and compute the R-convolution kernel between pairwise graphs associated with the more significant substructures specified by their structural attentions. Since each row of the resulting kernel matrix can be theoretically seen as the embedding vector of a sample graph, the proposed AKBR model is able to directly employ the resulting kernel matrix as the graph feature matrix and input it into the classifier for classification (i.e., the SoftMax layer), naturally providing an end-to-end learning architecture between the kernel computation as well as the classifier. Experimental results show that the proposed AKBR model outperforms existing state-of-the-art graph kernels and deep learning methods on standard graph benchmarks.
Read more8/14/2024
🤿
0
Deep Hierarchical Graph Alignment Kernels
Shuhao Tang, Hao Tian, Xiaofeng Cao, Wei Ye
Typical R-convolution graph kernels invoke the kernel functions that decompose graphs into non-isomorphic substructures and compare them. However, overlooking implicit similarities and topological position information between those substructures limits their performances. In this paper, we introduce Deep Hierarchical Graph Alignment Kernels (DHGAK) to resolve this problem. Specifically, the relational substructures are hierarchically aligned to cluster distributions in their deep embedding space. The substructures belonging to the same cluster are assigned the same feature map in the Reproducing Kernel Hilbert Space (RKHS), where graph feature maps are derived by kernel mean embedding. Theoretical analysis guarantees that DHGAK is positive semi-definite and has linear separability in the RKHS. Comparison with state-of-the-art graph kernels on various benchmark datasets demonstrates the effectiveness and efficiency of DHGAK. The code is available at Github (https://github.com/EWesternRa/DHGAK).
Read more5/10/2024
🧠
0
Graph Kernel Neural Networks
Luca Cosmo, Giorgia Minello, Alessandro Bicciato, Michael Bronstein, Emanuele Rodol`a, Luca Rossi, Andrea Torsello
The convolution operator at the core of many modern neural architectures can effectively be seen as performing a dot product between an input matrix and a filter. While this is readily applicable to data such as images, which can be represented as regular grids in the Euclidean space, extending the convolution operator to work on graphs proves more challenging, due to their irregular structure. In this paper, we propose to use graph kernels, i.e. kernel functions that compute an inner product on graphs, to extend the standard convolution operator to the graph domain. This allows us to define an entirely structural model that does not require computing the embedding of the input graph. Our architecture allows to plug-in any type of graph kernels and has the added benefit of providing some interpretability in terms of the structural masks that are learned during the training process, similarly to what happens for convolutional masks in traditional convolutional neural networks. We perform an extensive ablation study to investigate the model hyper-parameters' impact and show that our model achieves competitive performance on standard graph classification and regression datasets.
Read more6/21/2024
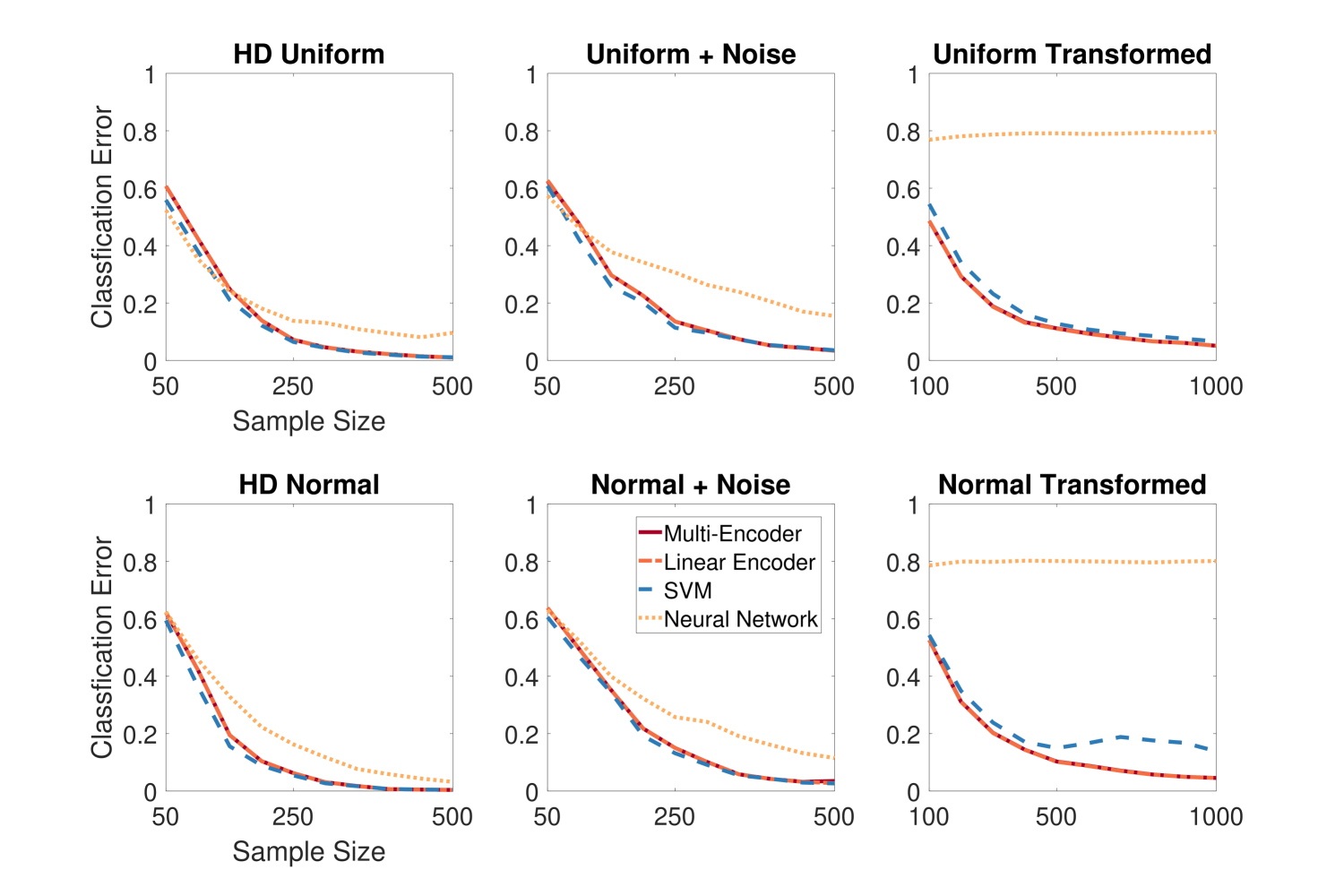
0
Fast and Scalable Multi-Kernel Encoder Classifier
Cencheng Shen
This paper introduces a new kernel-based classifier by viewing kernel matrices as generalized graphs and leveraging recent progress in graph embedding techniques. The proposed method facilitates fast and scalable kernel matrix embedding, and seamlessly integrates multiple kernels to enhance the learning process. Our theoretical analysis offers a population-level characterization of this approach using random variables. Empirically, our method demonstrates superior running time compared to standard approaches such as support vector machines and two-layer neural network, while achieving comparable classification accuracy across various simulated and real datasets.
Read more6/5/2024