Aligning Explanations for Recommendation with Rating and Feature via Maximizing Mutual Information

0
Sign in to get full access
Overview
- This paper proposes a framework called RecExplainer that aligns natural language-based explanations for recommendations with the corresponding ratings and feature importance.
- The key idea is to maximize the mutual information between the explanation and the rating/feature importance, ensuring the explanation is informative and relevant.
- The authors demonstrate the effectiveness of RecExplainer on several real-world recommendation datasets, showing it outperforms existing explainable recommendation methods.
Plain English Explanation
The paper tackles the challenge of providing clear, meaningful explanations for the recommendations made by AI recommendation systems. Oftentimes, these systems can be "black boxes" - they make recommendations, but it's not always clear why they chose those particular items.
RecExplainer: Aligning Explanations for Recommendation with Rating and Feature via Maximizing Mutual Information proposes a new approach to generate natural language-based explanations that are closely aligned with the actual ratings and feature importance behind the recommendations.
The core idea is to maximize the "mutual information" between the explanation and the rating/feature importance. In other words, the explanation should capture as much of the relevant information as possible about why the system made a particular recommendation. This helps ensure the explanation is informative and closely tied to the actual decision-making process.
The authors demonstrate that this approach outperforms existing explainable recommendation methods on several real-world datasets. By aligning the explanations with the underlying ratings and features, the system can provide users with more transparent and trustworthy recommendations.
Technical Explanation
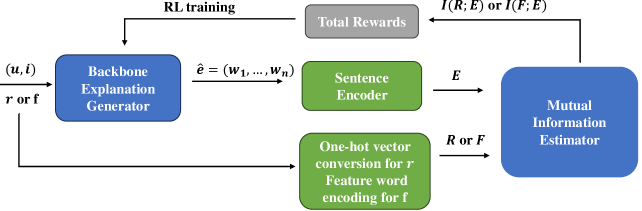
The RecExplainer framework consists of three key components:
- Rating Predictor: This module predicts the rating a user would give to a recommended item based on the item's features.
- Feature Importance Estimator: This component estimates the importance of each feature in determining the rating prediction.
- Explanation Generator: This is a language model that generates natural language explanations for the recommendations, aiming to maximize the mutual information between the explanation and the rating/feature importance.
The authors train these components jointly, using a combination of recommendation data, ratings, and feature information. The mutual information objective encourages the explanation generator to produce text that is closely aligned with the underlying recommendation logic.
The authors evaluate RecExplainer on several real-world recommendation datasets, including MovieLens and Amazon reviews. They show that it outperforms existing explainable recommendation methods in terms of explanation quality, as judged by human evaluators.
Critical Analysis
The RecExplainer approach is a promising step towards more transparent and trustworthy recommendation systems. By aligning the explanations with the actual decision-making process, it helps users better understand the rationale behind the recommendations.
However, the paper does not address some important limitations:
-
Scalability: The joint training of the various components may not scale well to large-scale recommendation systems with millions of users and items. The authors do not discuss the computational complexity of their approach.
-
Interpretability of the Mutual Information Objective: While maximizing mutual information is a principled objective, it may not always be clear how to interpret the resulting explanations. The authors could provide more insight into the connection between mutual information and the quality of the explanations.
-
Generalizability: The paper focuses on a specific type of recommendation task (item-based) and evaluation datasets. More research is needed to understand how well the RecExplainer approach generalizes to other recommendation domains, such as session-based or multimodal recommendations.
-
User Studies: While the authors perform human evaluations, more in-depth user studies would be valuable to understand how end-users perceive the explanations generated by RecExplainer and how they impact trust and satisfaction with the recommendation system.
Overall, the RecExplainer framework represents an interesting advance in the field of explainable recommendation, but further research is needed to address its limitations and explore its broader applicability.
Conclusion
The RecExplainer paper proposes a novel approach to generating natural language explanations for recommendations that are closely aligned with the underlying ratings and feature importance. By maximizing the mutual information between the explanation and the recommendation logic, the system can provide users with more transparent and trustworthy recommendations.
The authors demonstrate the effectiveness of their approach on several real-world datasets, showing that RecExplainer outperforms existing explainable recommendation methods. While the paper represents an important step forward, future research is needed to address scalability, interpretability, and generalizability concerns, as well as to conduct more in-depth user studies.
Overall, the RecExplainer framework is a promising contribution to the field of explainable AI, with the potential to significantly improve the transparency and trustworthiness of recommendation systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Aligning Explanations for Recommendation with Rating and Feature via Maximizing Mutual Information
Yurou Zhao, Yiding Sun, Ruidong Han, Fei Jiang, Lu Guan, Xiang Li, Wei Lin, Weizhi Ma, Jiaxin Mao
Providing natural language-based explanations to justify recommendations helps to improve users' satisfaction and gain users' trust. However, as current explanation generation methods are commonly trained with an objective to mimic existing user reviews, the generated explanations are often not aligned with the predicted ratings or some important features of the recommended items, and thus, are suboptimal in helping users make informed decision on the recommendation platform. To tackle this problem, we propose a flexible model-agnostic method named MMI (Maximizing Mutual Information) framework to enhance the alignment between the generated natural language explanations and the predicted rating/important item features. Specifically, we propose to use mutual information (MI) as a measure for the alignment and train a neural MI estimator. Then, we treat a well-trained explanation generation model as the backbone model and further fine-tune it through reinforcement learning with guidance from the MI estimator, which rewards a generated explanation that is more aligned with the predicted rating or a pre-defined feature of the recommended item. Experiments on three datasets demonstrate that our MMI framework can boost different backbone models, enabling them to outperform existing baselines in terms of alignment with predicted ratings and item features. Additionally, user studies verify that MI-enhanced explanations indeed facilitate users' decisions and are favorable compared with other baselines due to their better alignment properties.
Read more8/22/2024

0
An Aligning and Training Framework for Multimodal Recommendations
Yifan Liu, Kangning Zhang, Xiangyuan Ren, Yanhua Huang, Jiarui Jin, Yingjie Qin, Ruilong Su, Ruiwen Xu, Yong Yu, Weinan Zhang
With the development of multimedia systems, multimodal recommendations are playing an essential role, as they can leverage rich contexts beyond interactions. Existing methods mainly regard multimodal information as an auxiliary, using them to help learn ID features; However, there exist semantic gaps among multimodal content features and ID-based features, for which directly using multimodal information as an auxiliary would lead to misalignment in representations of users and items. In this paper, we first systematically investigate the misalignment issue in multimodal recommendations, and propose a solution named AlignRec. In AlignRec, the recommendation objective is decomposed into three alignments, namely alignment within contents, alignment between content and categorical ID, and alignment between users and items. Each alignment is characterized by a specific objective function and is integrated into our multimodal recommendation framework. To effectively train AlignRec, we propose starting from pre-training the first alignment to obtain unified multimodal features and subsequently training the following two alignments together with these features as input. As it is essential to analyze whether each multimodal feature helps in training and accelerate the iteration cycle of recommendation models, we design three new classes of metrics to evaluate intermediate performance. Our extensive experiments on three real-world datasets consistently verify the superiority of AlignRec compared to nine baselines. We also find that the multimodal features generated by AlignRec are better than currently used ones, which are to be open-sourced in our repository https://github.com/sjtulyf123/AlignRec_CIKM24.
Read more8/2/2024
💬
0
RecExplainer: Aligning Large Language Models for Explaining Recommendation Models
Yuxuan Lei, Jianxun Lian, Jing Yao, Xu Huang, Defu Lian, Xing Xie
Recommender systems are widely used in online services, with embedding-based models being particularly popular due to their expressiveness in representing complex signals. However, these models often function as a black box, making them less transparent and reliable for both users and developers. Recently, large language models (LLMs) have demonstrated remarkable intelligence in understanding, reasoning, and instruction following. This paper presents the initial exploration of using LLMs as surrogate models to explaining black-box recommender models. The primary concept involves training LLMs to comprehend and emulate the behavior of target recommender models. By leveraging LLMs' own extensive world knowledge and multi-step reasoning abilities, these aligned LLMs can serve as advanced surrogates, capable of reasoning about observations. Moreover, employing natural language as an interface allows for the creation of customizable explanations that can be adapted to individual user preferences. To facilitate an effective alignment, we introduce three methods: behavior alignment, intention alignment, and hybrid alignment. Behavior alignment operates in the language space, representing user preferences and item information as text to mimic the target model's behavior; intention alignment works in the latent space of the recommendation model, using user and item representations to understand the model's behavior; hybrid alignment combines both language and latent spaces. Comprehensive experiments conducted on three public datasets show that our approach yields promising results in understanding and mimicking target models, producing high-quality, high-fidelity, and distinct explanations. Our code is available at https://github.com/microsoft/RecAI.
Read more6/26/2024

0
Structure Learning via Mutual Information
Jeremy Nixon
This paper presents a novel approach to machine learning algorithm design based on information theory, specifically mutual information (MI). We propose a framework for learning and representing functional relationships in data using MI-based features. Our method aims to capture the underlying structure of information in datasets, enabling more efficient and generalizable learning algorithms. We demonstrate the efficacy of our approach through experiments on synthetic and real-world datasets, showing improved performance in tasks such as function classification, regression, and cross-dataset transfer. This work contributes to the growing field of metalearning and automated machine learning, offering a new perspective on how to leverage information theory for algorithm design and dataset analysis and proposing new mutual information theoretic foundations to learning algorithms.
Read more9/24/2024