All in an Aggregated Image for In-Image Learning
2402.17971
0
0
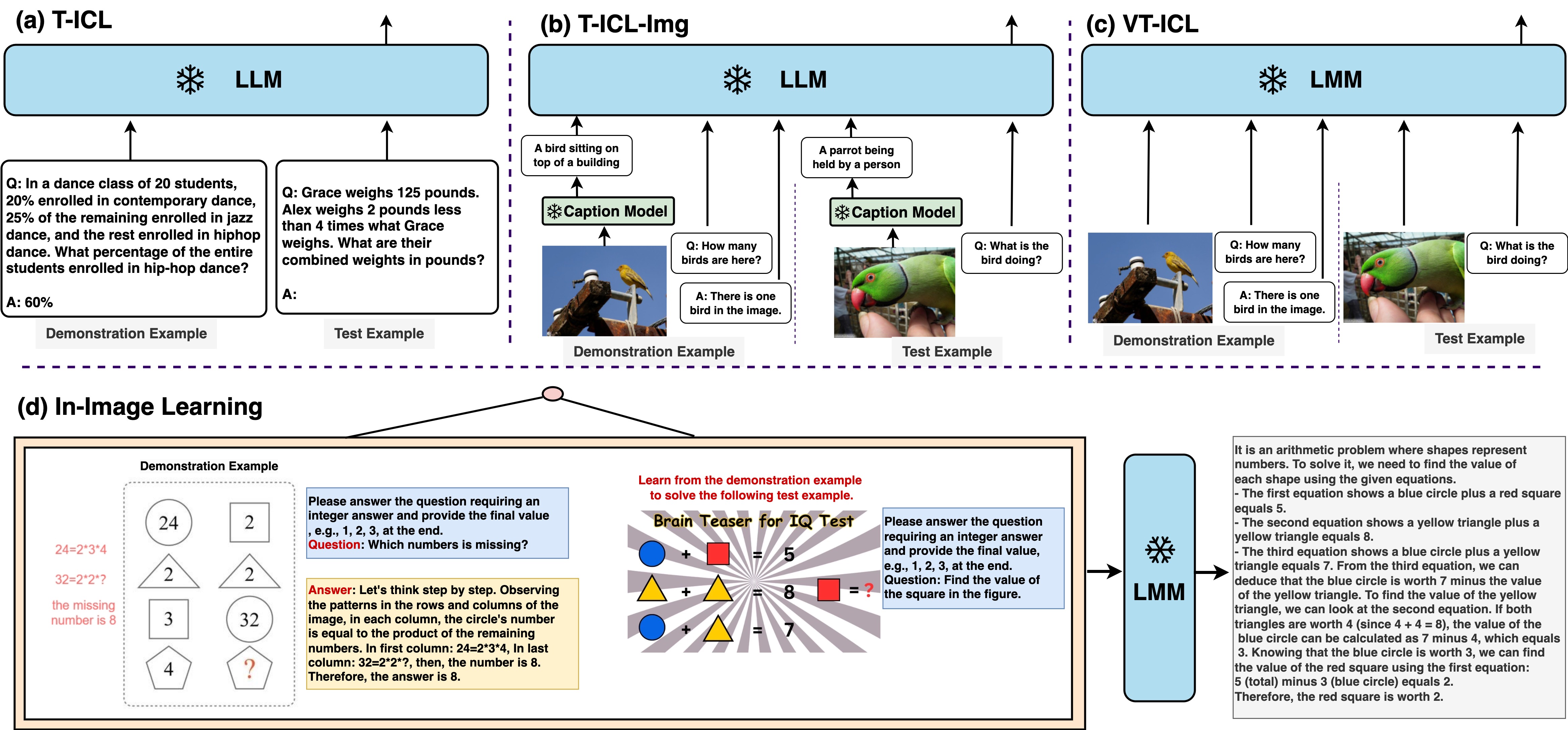
Abstract
This paper introduces a new in-context learning (ICL) mechanism called In-Image Learning (I$^2$L) that combines demonstration examples, visual cues, and chain-of-thought reasoning into an aggregated image to enhance the capabilities of Large Multimodal Models (e.g., GPT-4V) in multimodal reasoning tasks. Unlike previous approaches that rely on converting images to text or incorporating visual input into language models, I$^2$L consolidates all information into an aggregated image and leverages image processing, understanding, and reasoning abilities. This has several advantages: it reduces inaccurate textual descriptions of complex images, provides flexibility in positioning demonstration examples, and avoids multiple input images and lengthy prompts. We also introduce I$^2$L-Hybrid, a method that combines the strengths of I$^2$L with other ICL methods. Specifically, it uses an automatic strategy to select the most suitable method (I$^2$L or another certain ICL method) for a specific task instance. We conduct extensive experiments to assess the effectiveness of I$^2$L and I$^2$L-Hybrid on MathVista, which covers a variety of complex multimodal reasoning tasks. Additionally, we investigate the influence of image resolution, the number of demonstration examples in a single image, and the positions of these demonstrations in the aggregated image on the effectiveness of I$^2$L. Our code is publicly available at https://github.com/AGI-Edgerunners/IIL.
Create account to get full access
Overview
- This paper explores how large multimodal language models, which can process both text and images, are able to learn directly from the visual information contained in a single image.
- The researchers investigate the in-image learning capabilities of these models, showing they can extract rich semantic understanding from images alone.
- The findings suggest these models have powerful visual understanding abilities that could enable new applications for image-based tasks.
Plain English Explanation
Large language models like GPT-3 have become remarkably capable at processing and generating human-like text. But these models can also handle visual information, allowing them to understand the contents of images as well as text.
The researchers in this paper wanted to explore just how much these multimodal models can learn from a single image alone, without any additional text-based information. They found that these models are able to extract a very detailed semantic understanding directly from the visual elements in an image. For example, the model can look at a photograph and identify the objects, people, actions, and relationships depicted, all from the image itself.
This suggests these powerful language models are functioning as "in-image learners" - they can learn a rich set of concepts and associations just by analyzing the contents of a single image, without needing any text-based explanations or captions. This visual understanding is then reflected in the model's language generation and other language-based tasks.
The implications of this finding are quite significant. It means these multimodal models could enable new AI applications that rely heavily on visual understanding, from image-based question answering to automated image captioning and beyond. Their ability to extract meaning from images alone opens up exciting possibilities for how AI can leverage and make sense of visual data.
Technical Explanation
The researchers investigated the in-image learning capabilities of large multimodal language models, which are trained on both text and images. They conducted experiments using the DALL-E 2 and CLIP models, testing the models' ability to extract semantic understanding directly from the visual elements in single images.
The experiments involved showing the models various images and testing their performance on downstream language tasks that required understanding the contents and relationships depicted in the images. The researchers found the models were able to accurately answer questions, generate relevant captions, and perform other language tasks using only the visual information from the images, without any accompanying text.
Further analysis revealed the models had developed rich internal representations of the semantic concepts, objects, and relationships present in the images. This suggested the models were functioning as "in-image learners," extracting detailed knowledge from the visual input alone.
The researchers also explored potential limitations, noting the models' performance could be further improved with more targeted training on image-centric tasks. They highlighted the need for continued research to fully understand the extent and mechanisms of these models' visual understanding capabilities.
Critical Analysis
The findings in this paper demonstrate the impressive multimodal learning abilities of large language models, but there are some important caveats to consider. While the models were able to extract semantic knowledge from images, the researchers note their performance could likely be further enhanced through more specialized training on image-focused tasks.
Additionally, the paper does not delve into potential biases or blind spots in the models' visual understanding. As with any AI system, it is crucial to carefully evaluate these models for unintended biases or limitations in their perception and interpretation of visual data.
Another area for further study is the extent to which these in-image learning capabilities generalize beyond the specific dataset and scenarios explored in the experiments. Investigating performance on more diverse, real-world image types and downstream applications would help paint a fuller picture of the models' visual understanding abilities.
Overall, this research represents an important step forward in understanding the multimodal nature of large language models. However, ongoing work is needed to fully harness the potential of these models for visual understanding and to ensure their capabilities are developed and deployed responsibly.
Conclusion
This paper demonstrates that large multimodal language models are capable of functioning as "in-image learners," extracting rich semantic understanding directly from the visual content of single images. The findings suggest these models have developed powerful visual understanding abilities that could enable new AI applications relying on image-based knowledge and reasoning.
While impressive, the research also highlights the need for continued investigation into the limitations, biases, and generalization of these models' multimodal capabilities. As these technologies continue to advance, it will be critical to study them thoroughly and deploy them responsibly to fully harness their potential benefits while mitigating potential risks or unintended consequences.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
AIM: Let Any Multi-modal Large Language Models Embrace Efficient In-Context Learning
Jun Gao, Qian Qiao, Ziqiang Cao, Zili Wang, Wenjie Li
0
0
In-context learning (ICL) facilitates Large Language Models (LLMs) exhibiting emergent ability on downstream tasks without updating billions of parameters. However, in the area of multi-modal Large Language Models (MLLMs), two problems hinder the application of multi-modal ICL: (1) Most primary MLLMs are only trained on single-image datasets, making them unable to read multi-modal demonstrations. (2) With the demonstrations increasing, thousands of visual tokens highly challenge hardware and degrade ICL performance. During preliminary explorations, we discovered that the inner LLM tends to focus more on the linguistic modality within multi-modal demonstrations to generate responses. Therefore, we propose a general and light-weighted framework textbf{AIM} to tackle the mentioned problems through textbf{A}ggregating textbf{I}mage information of textbf{M}ultimodal demonstrations to the dense latent space of the corresponding linguistic part. Specifically, AIM first uses the frozen backbone MLLM to read each image-text demonstration and extracts the vector representations on top of the text. These vectors naturally fuse the information of the image-text pair, and AIM transforms them into fused virtual tokens acceptable for the inner LLM via a trainable projection layer. Ultimately, these fused tokens function as variants of multi-modal demonstrations, fed into the MLLM to direct its response to the current query as usual. Because these fused tokens stem from the textual component of the image-text pair, a multi-modal demonstration is nearly reduced to a pure textual demonstration, thus seamlessly applying to any MLLMs. With its de facto MLLM frozen, AIM is parameter-efficient and we train it on public multi-modal web corpora which have nothing to do with downstream test tasks.
7/2/2024
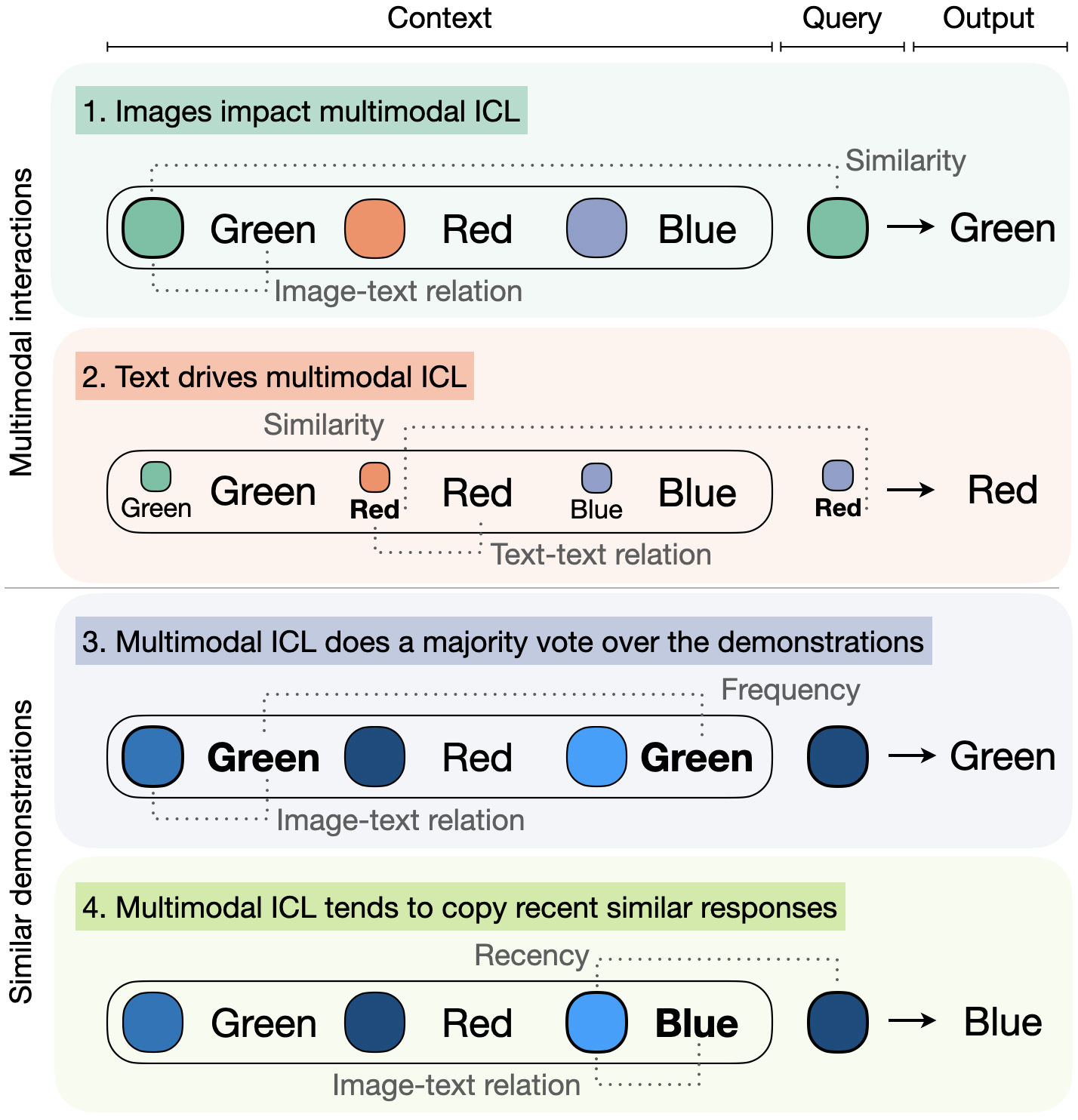
What Makes Multimodal In-Context Learning Work?
Folco Bertini Baldassini, Mustafa Shukor, Matthieu Cord, Laure Soulier, Benjamin Piwowarski
0
0
Large Language Models have demonstrated remarkable performance across various tasks, exhibiting the capacity to swiftly acquire new skills, such as through In-Context Learning (ICL) with minimal demonstration examples. In this work, we present a comprehensive framework for investigating Multimodal ICL (M-ICL) in the context of Large Multimodal Models. We consider the best open-source multimodal models (e.g., IDEFICS, OpenFlamingo) and a wide range of multimodal tasks. Our study unveils several noteworthy findings: (1) M-ICL primarily relies on text-driven mechanisms, showing little to no influence from the image modality. (2) When used with advanced-ICL strategy (like RICES), M-ICL is not better than a simple strategy based on majority voting over context examples. Moreover, we identify several biases and limitations of M-ICL that warrant consideration prior to deployment. Code available at https://gitlab.com/folbaeni/multimodal-icl
4/26/2024
❗
Can MLLMs Perform Text-to-Image In-Context Learning?
Yuchen Zeng, Wonjun Kang, Yicong Chen, Hyung Il Koo, Kangwook Lee
0
0
The evolution from Large Language Models (LLMs) to Multimodal Large Language Models (MLLMs) has spurred research into extending In-Context Learning (ICL) to its multimodal counterpart. Existing such studies have primarily concentrated on image-to-text ICL. However, the Text-to-Image ICL (T2I-ICL), with its unique characteristics and potential applications, remains underexplored. To address this gap, we formally define the task of T2I-ICL and present CoBSAT, the first T2I-ICL benchmark dataset, encompassing ten tasks. Utilizing our dataset to benchmark six state-of-the-art MLLMs, we uncover considerable difficulties MLLMs encounter in solving T2I-ICL. We identify the primary challenges as the inherent complexity of multimodality and image generation, and show that strategies such as fine-tuning and Chain-of-Thought prompting help to mitigate these difficulties, leading to notable improvements in performance. Our code and dataset are available at https://github.com/UW-Madison-Lee-Lab/CoBSAT.
4/17/2024
💬
Explaining Multi-modal Large Language Models by Analyzing their Vision Perception
Loris Giulivi, Giacomo Boracchi
0
0
Multi-modal Large Language Models (MLLMs) have demonstrated remarkable capabilities in understanding and generating content across various modalities, such as images and text. However, their interpretability remains a challenge, hindering their adoption in critical applications. This research proposes a novel approach to enhance the interpretability of MLLMs by focusing on the image embedding component. We combine an open-world localization model with a MLLM, thus creating a new architecture able to simultaneously produce text and object localization outputs from the same vision embedding. The proposed architecture greatly promotes interpretability, enabling us to design a novel saliency map to explain any output token, to identify model hallucinations, and to assess model biases through semantic adversarial perturbations.
5/29/2024