Can MLLMs Perform Text-to-Image In-Context Learning?
2402.01293
0
0
❗
Abstract
The evolution from Large Language Models (LLMs) to Multimodal Large Language Models (MLLMs) has spurred research into extending In-Context Learning (ICL) to its multimodal counterpart. Existing such studies have primarily concentrated on image-to-text ICL. However, the Text-to-Image ICL (T2I-ICL), with its unique characteristics and potential applications, remains underexplored. To address this gap, we formally define the task of T2I-ICL and present CoBSAT, the first T2I-ICL benchmark dataset, encompassing ten tasks. Utilizing our dataset to benchmark six state-of-the-art MLLMs, we uncover considerable difficulties MLLMs encounter in solving T2I-ICL. We identify the primary challenges as the inherent complexity of multimodality and image generation, and show that strategies such as fine-tuning and Chain-of-Thought prompting help to mitigate these difficulties, leading to notable improvements in performance. Our code and dataset are available at https://github.com/UW-Madison-Lee-Lab/CoBSAT.
Create account to get full access
Overview
- This paper explores the task of Text-to-Image In-Context Learning (T2I-ICL), where an AI model is given a text prompt and must generate an image that matches the prompt.
- The authors introduce a new benchmark dataset called CoBSAT, which includes 10 different T2I-ICL tasks.
- They evaluate several state-of-the-art Multimodal Large Language Models (MLLMs) on the CoBSAT dataset and find that these models struggle with the challenges of multimodality and image generation.
- The authors show that techniques like fine-tuning and "Chain-of-Thought" prompting can help improve the performance of MLLMs on T2I-ICL tasks.
Plain English Explanation
As artificial intelligence (AI) models have become more advanced, researchers have been exploring ways to expand their capabilities beyond just processing text. One promising area is Multimodal Large Language Models (MLLMs), which can work with both text and images.
One specific task that MLLMs could potentially tackle is Text-to-Image In-Context Learning (T2I-ICL). In this task, the AI model is given a text description and must generate an image that matches that description. This could have all sorts of interesting applications, like helping artists come up with new ideas or allowing people to create custom images just by describing what they want.
However, T2I-ICL is a challenging problem, and the authors of this paper wanted to better understand how well current MLLMs perform on it. To do this, they created a new benchmark dataset called CoBSAT, which includes 10 different T2I-ICL tasks. They then evaluated several state-of-the-art MLLMs on this dataset and found that they struggle with the inherent complexity of working with both text and images.
The authors identified a few key challenges that make T2I-ICL difficult for these models:
- Multimodality: Effectively combining and processing both text and image information is inherently more complex than working with just one modality.
- Image Generation: Generating high-quality images from scratch is a very difficult task, even for advanced AI systems.
But the researchers also found that certain techniques, like fine-tuning the models and using "Chain-of-Thought" prompting, can help improve the performance of MLLMs on T2I-ICL tasks. This suggests that with the right approaches, these models may be able to overcome the challenges and become effective at Text-to-Image In-Context Learning.
Technical Explanation
The authors of this paper formally define the task of Text-to-Image In-Context Learning (T2I-ICL), which involves generating an image that matches a given text prompt. This task is an extension of the broader concept of In-Context Learning (ICL), where an AI model can leverage contextual information to complete a given task.
To better understand how well current Multimodal Large Language Models (MLLMs) perform on T2I-ICL, the researchers created a new benchmark dataset called CoBSAT. This dataset includes 10 distinct T2I-ICL tasks, covering a range of domains and complexity levels.
The authors then evaluated six state-of-the-art MLLM systems on the CoBSAT dataset. Their results showed that these models struggle with the unique challenges of T2I-ICL, including the inherent complexity of multimodality (combining text and image information) and the difficulty of image generation.
However, the researchers also found that certain strategies can help improve the performance of MLLMs on T2I-ICL tasks. Specifically, they demonstrated that fine-tuning the models on relevant data and using Chain-of-Thought prompting (a technique where the model is encouraged to break down problems into multiple steps) can lead to notable improvements in performance.
Critical Analysis
The paper provides a valuable contribution by formally defining the T2I-ICL task and introducing a new benchmark dataset, CoBSAT, to evaluate MLLM performance on this challenge. The authors' findings highlight the significant difficulties that current state-of-the-art models face when attempting to translate text prompts into generated images.
One potential limitation of the study is that the authors only evaluated a relatively small number of MLLM systems (six) on the CoBSAT dataset. It would be interesting to see how a broader range of models, including newer or more specialized architectures, might perform on these tasks. Additionally, the paper does not delve deeply into the specific reasons why certain models struggled more than others, which could provide valuable insights for future research.
Furthermore, the authors acknowledge that their work focuses on the technical aspects of T2I-ICL, and they do not explore the potential social or ethical implications of such systems. As text-to-image models become more advanced, it will be crucial for researchers to consider the broader societal impacts and potential misuse cases.
Overall, this paper lays important groundwork for the emerging field of T2I-ICL and highlights the need for continued research to overcome the challenges of multimodal learning. By further exploring this area, researchers may unlock new possibilities for AI-powered image creation and potentially transform various industries and applications.
Conclusion
This paper takes an important step forward in the exploration of Text-to-Image In-Context Learning (T2I-ICL), a task that could have far-reaching applications if the technical challenges can be overcome. By introducing the CoBSAT benchmark dataset and evaluating the performance of several state-of-the-art Multimodal Large Language Models, the authors have shed light on the inherent difficulties of combining text and image information in a generative context.
While current MLLM systems struggle with T2I-ICL, the authors demonstrate that strategies like fine-tuning and Chain-of-Thought prompting can help improve their capabilities. This suggests that with continued research and development, AI models may one day be able to seamlessly translate text descriptions into high-quality, contextually relevant images - unlocking new possibilities for creative expression, visualization, and more.
As the field of multimodal learning continues to evolve, it will be crucial for researchers to not only address the technical challenges, but also consider the broader societal implications of such powerful image generation systems. By approaching this work with a critical and thoughtful mindset, the AI community can work towards unlocking the transformative potential of Text-to-Image In-Context Learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
AIM: Let Any Multi-modal Large Language Models Embrace Efficient In-Context Learning
Jun Gao, Qian Qiao, Ziqiang Cao, Zili Wang, Wenjie Li
0
0
In-context learning (ICL) facilitates Large Language Models (LLMs) exhibiting emergent ability on downstream tasks without updating billions of parameters. However, in the area of multi-modal Large Language Models (MLLMs), two problems hinder the application of multi-modal ICL: (1) Most primary MLLMs are only trained on single-image datasets, making them unable to read multi-modal demonstrations. (2) With the demonstrations increasing, thousands of visual tokens highly challenge hardware and degrade ICL performance. During preliminary explorations, we discovered that the inner LLM tends to focus more on the linguistic modality within multi-modal demonstrations to generate responses. Therefore, we propose a general and light-weighted framework textbf{AIM} to tackle the mentioned problems through textbf{A}ggregating textbf{I}mage information of textbf{M}ultimodal demonstrations to the dense latent space of the corresponding linguistic part. Specifically, AIM first uses the frozen backbone MLLM to read each image-text demonstration and extracts the vector representations on top of the text. These vectors naturally fuse the information of the image-text pair, and AIM transforms them into fused virtual tokens acceptable for the inner LLM via a trainable projection layer. Ultimately, these fused tokens function as variants of multi-modal demonstrations, fed into the MLLM to direct its response to the current query as usual. Because these fused tokens stem from the textual component of the image-text pair, a multi-modal demonstration is nearly reduced to a pure textual demonstration, thus seamlessly applying to any MLLMs. With its de facto MLLM frozen, AIM is parameter-efficient and we train it on public multi-modal web corpora which have nothing to do with downstream test tasks.
6/13/2024
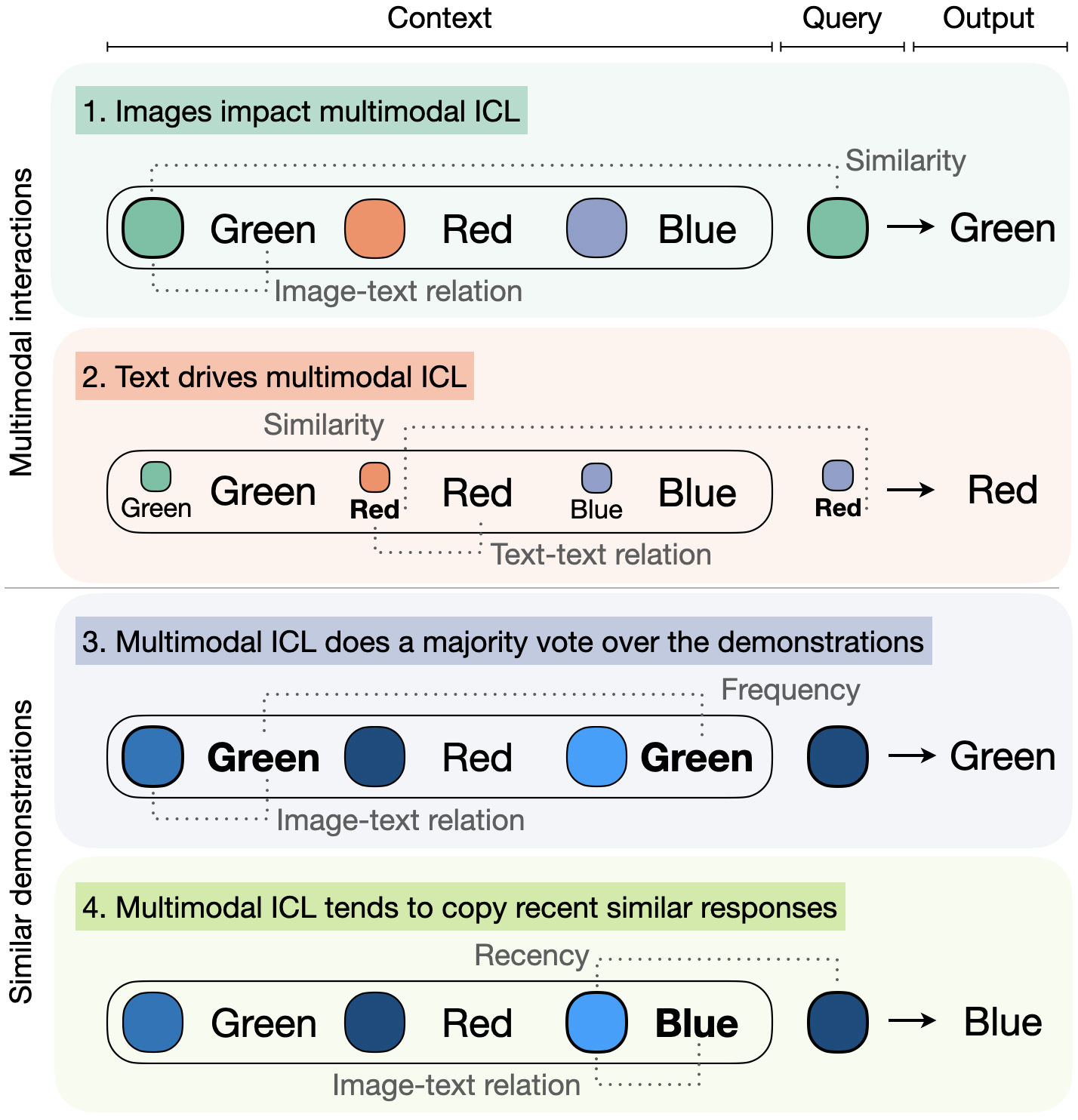
What Makes Multimodal In-Context Learning Work?
Folco Bertini Baldassini, Mustafa Shukor, Matthieu Cord, Laure Soulier, Benjamin Piwowarski
0
0
Large Language Models have demonstrated remarkable performance across various tasks, exhibiting the capacity to swiftly acquire new skills, such as through In-Context Learning (ICL) with minimal demonstration examples. In this work, we present a comprehensive framework for investigating Multimodal ICL (M-ICL) in the context of Large Multimodal Models. We consider the best open-source multimodal models (e.g., IDEFICS, OpenFlamingo) and a wide range of multimodal tasks. Our study unveils several noteworthy findings: (1) M-ICL primarily relies on text-driven mechanisms, showing little to no influence from the image modality. (2) When used with advanced-ICL strategy (like RICES), M-ICL is not better than a simple strategy based on majority voting over context examples. Moreover, we identify several biases and limitations of M-ICL that warrant consideration prior to deployment. Code available at https://gitlab.com/folbaeni/multimodal-icl
4/26/2024
📈
An Empirical Study of In-context Learning in LLMs for Machine Translation
Pranjal A. Chitale, Jay Gala, Raj Dabre
0
0
Recent interest has surged in employing Large Language Models (LLMs) for machine translation (MT) via in-context learning (ICL) (Vilar et al., 2023). Most prior studies primarily focus on optimizing translation quality, with limited attention to understanding the specific aspects of ICL that influence the said quality. To this end, we perform the first of its kind, an exhaustive study of in-context learning for machine translation. We first establish that ICL is primarily example-driven and not instruction-driven. Following this, we conduct an extensive exploration of various aspects of the examples to understand their influence on downstream performance. Our analysis includes factors such as quality and quantity of demonstrations, spatial proximity, and source versus target originality. Further, we also investigate challenging scenarios involving indirectness and misalignment of examples to understand the limits of ICL. While we establish the significance of the quality of the target distribution over the source distribution of demonstrations, we further observe that perturbations sometimes act as regularizers, resulting in performance improvements. Surprisingly, ICL does not necessitate examples from the same task, and a related task with the same target distribution proves sufficient. We hope that our study acts as a guiding resource for considerations in utilizing ICL for MT. Our code is available on https://github.com/PranjalChitale/in-context-mt-analysis.
6/6/2024
MileBench: Benchmarking MLLMs in Long Context
Dingjie Song, Shunian Chen, Guiming Hardy Chen, Fei Yu, Xiang Wan, Benyou Wang
0
0
Despite the advancements and impressive performance of Multimodal Large Language Models (MLLMs) on benchmarks, their effectiveness in real-world, long-context, and multi-image tasks is unclear due to the benchmarks' limited scope. Existing benchmarks often focus on single-image and short-text samples, and when assessing multi-image tasks, they either limit the image count or focus on specific task (e.g time-series captioning), potentially obscuring the performance challenges of MLLMs. To address these limitations, we introduce MileBench, a pioneering benchmark designed to test the MultImodal Long-contExt capabilities of MLLMs. This benchmark comprises not only multimodal long contexts, but also multiple tasks requiring both comprehension and generation. We establish two distinct evaluation sets, diagnostic and realistic, to systematically assess MLLMs' long-context adaptation capacity and their ability to complete tasks in long-context scenarios. Our experimental results, obtained from testing 22 models, revealed that while the closed-source GPT-4o outperforms others, most open-source MLLMs struggle in long-context situations. Interestingly, the performance gap tends to widen with an increase in the number of images. We strongly encourage an intensification of research efforts towards enhancing MLLMs' long-context capabilities, especially in scenarios involving multiple images.
5/16/2024