An Analysis on Quantizing Diffusion Transformers
2406.11100
0
0

Abstract
Diffusion Models (DMs) utilize an iterative denoising process to transform random noise into synthetic data. Initally proposed with a UNet structure, DMs excel at producing images that are virtually indistinguishable with or without conditioned text prompts. Later transformer-only structure is composed with DMs to achieve better performance. Though Latent Diffusion Models (LDMs) reduce the computational requirement by denoising in a latent space, it is extremely expensive to inference images for any operating devices due to the shear volume of parameters and feature sizes. Post Training Quantization (PTQ) offers an immediate remedy for a smaller storage size and more memory-efficient computation during inferencing. Prior works address PTQ of DMs on UNet structures have addressed the challenges in calibrating parameters for both activations and weights via moderate optimization. In this work, we pioneer an efficient PTQ on transformer-only structure without any optimization. By analysing challenges in quantizing activations and weights for diffusion transformers, we propose a single-step sampling calibration on activations and adapt group-wise quantization on weights for low-bit quantization. We demonstrate the efficiency and effectiveness of proposed methods with preliminary experiments on conditional image generation.
Create account to get full access
Overview
- This paper analyzes the process of quantizing Diffusion Transformers, which are a type of machine learning model used for tasks like image generation.
- Quantization is a technique to reduce the complexity and size of machine learning models by reducing the precision of their numerical parameters, making them more efficient to run on hardware.
- The paper explores different quantization strategies and their impact on the performance of Diffusion Transformers.
Plain English Explanation
Diffusion Transformers are a powerful type of machine learning model that can generate realistic images from scratch. However, these models can be very large and computationally intensive, making them challenging to use in practical applications.
One way to make these models more efficient is through a process called quantization. Quantization involves reducing the precision of the numerical parameters in the model, allowing it to take up less memory and run faster on hardware.
This paper investigates different ways to quantize Diffusion Transformers. The researchers tested various quantization strategies to see how they impact the model's ability to generate high-quality images. They found that certain quantization methods can significantly reduce the model's size and complexity without greatly impacting its performance.
These findings could help make Diffusion Transformers more practical for real-world use cases, such as EfficientDM: Efficient Quantization-Aware Fine-tuning for Diffusion Models, PTQ4DiT: Post-Training Quantization for Diffusion Transformers, and Towards Accurate Post-Training Quantization of Diffusion Models. By making these models more efficient, they could be deployed on a wider range of hardware, including mobile devices and edge computing systems.
Technical Explanation
The paper explores different strategies for quantizing Diffusion Transformers, a type of machine learning model used for tasks like image generation. Quantization is a technique to reduce the complexity and size of machine learning models by reducing the precision of their numerical parameters.
The researchers tested several quantization methods, including TMPQ-DM: Joint Timestep Reduction and Quantization Precision and ViDiT-Q: Efficient and Accurate Quantization of Diffusion Transformers. They evaluated the impact of these quantization strategies on the model's image generation performance, as well as its size and computational requirements.
The results show that certain quantization methods can significantly reduce the model's complexity without greatly impacting its ability to generate high-quality images. This suggests that quantization could be a useful technique for making Diffusion Transformers more practical for real-world applications, where efficiency and resource constraints are important considerations.
Critical Analysis
The paper provides a thorough analysis of quantization techniques for Diffusion Transformers, but it also acknowledges some limitations and areas for further research.
One potential issue is that the experiments were conducted on a specific dataset and task (image generation), and the findings may not generalize to other applications of Diffusion Transformers. The researchers note that more work is needed to understand how quantization impacts the model's performance on a wider range of tasks.
Additionally, the paper does not explore the trade-offs between different quantization strategies in depth. While it shows that certain methods can achieve good performance-efficiency trade-offs, it doesn't provide a clear recommendation for which approach is best in all situations.
Further research could also investigate the impact of quantization on the model's robustness and reliability, as well as its ability to generalize to new data distributions. It would be valuable to understand how quantization affects the model's behavior in edge cases or under distribution shift.
Overall, this paper makes a valuable contribution to the understanding of quantization for Diffusion Transformers, but there is still room for further exploration and refinement of these techniques.
Conclusion
This paper presents an in-depth analysis of quantization techniques for Diffusion Transformers, a type of machine learning model used for image generation. The researchers tested several quantization strategies and found that they can significantly reduce the model's complexity and size without greatly impacting its performance.
These findings suggest that quantization could be a useful technique for making Diffusion Transformers more practical for real-world applications, where efficiency and resource constraints are important considerations. By improving the efficiency of these models, they could be deployed on a wider range of hardware, including mobile devices and edge computing systems.
While the paper provides valuable insights, it also acknowledges some limitations and areas for further research, such as exploring the impact of quantization on a wider range of tasks and understanding its effects on the model's robustness and reliability. Continued research in this area could lead to even more efficient and practical Diffusion Transformer models for a variety of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏷️
EfficientDM: Efficient Quantization-Aware Fine-Tuning of Low-Bit Diffusion Models
Yefei He, Jing Liu, Weijia Wu, Hong Zhou, Bohan Zhuang
0
0
Diffusion models have demonstrated remarkable capabilities in image synthesis and related generative tasks. Nevertheless, their practicality for real-world applications is constrained by substantial computational costs and latency issues. Quantization is a dominant way to compress and accelerate diffusion models, where post-training quantization (PTQ) and quantization-aware training (QAT) are two main approaches, each bearing its own properties. While PTQ exhibits efficiency in terms of both time and data usage, it may lead to diminished performance in low bit-width. On the other hand, QAT can alleviate performance degradation but comes with substantial demands on computational and data resources. In this paper, we introduce a data-free and parameter-efficient fine-tuning framework for low-bit diffusion models, dubbed EfficientDM, to achieve QAT-level performance with PTQ-like efficiency. Specifically, we propose a quantization-aware variant of the low-rank adapter (QALoRA) that can be merged with model weights and jointly quantized to low bit-width. The fine-tuning process distills the denoising capabilities of the full-precision model into its quantized counterpart, eliminating the requirement for training data. We also introduce scale-aware optimization and temporal learned step-size quantization to further enhance performance. Extensive experimental results demonstrate that our method significantly outperforms previous PTQ-based diffusion models while maintaining similar time and data efficiency. Specifically, there is only a 0.05 sFID increase when quantizing both weights and activations of LDM-4 to 4-bit on ImageNet 256x256. Compared to QAT-based methods, our EfficientDM also boasts a 16.2x faster quantization speed with comparable generation quality. Code is available at href{https://github.com/ThisisBillhe/EfficientDM}{this hrl}.
4/16/2024

PTQ4DiT: Post-training Quantization for Diffusion Transformers
Junyi Wu, Haoxuan Wang, Yuzhang Shang, Mubarak Shah, Yan Yan
0
0
The recent introduction of Diffusion Transformers (DiTs) has demonstrated exceptional capabilities in image generation by using a different backbone architecture, departing from traditional U-Nets and embracing the scalable nature of transformers. Despite their advanced capabilities, the wide deployment of DiTs, particularly for real-time applications, is currently hampered by considerable computational demands at the inference stage. Post-training Quantization (PTQ) has emerged as a fast and data-efficient solution that can significantly reduce computation and memory footprint by using low-bit weights and activations. However, its applicability to DiTs has not yet been explored and faces non-trivial difficulties due to the unique design of DiTs. In this paper, we propose PTQ4DiT, a specifically designed PTQ method for DiTs. We discover two primary quantization challenges inherent in DiTs, notably the presence of salient channels with extreme magnitudes and the temporal variability in distributions of salient activation over multiple timesteps. To tackle these challenges, we propose Channel-wise Salience Balancing (CSB) and Spearmen's $rho$-guided Salience Calibration (SSC). CSB leverages the complementarity property of channel magnitudes to redistribute the extremes, alleviating quantization errors for both activations and weights. SSC extends this approach by dynamically adjusting the balanced salience to capture the temporal variations in activation. Additionally, to eliminate extra computational costs caused by PTQ4DiT during inference, we design an offline re-parameterization strategy for DiTs. Experiments demonstrate that our PTQ4DiT successfully quantizes DiTs to 8-bit precision (W8A8) while preserving comparable generation ability and further enables effective quantization to 4-bit weight precision (W4A8) for the first time.
5/28/2024
🔍
Towards Accurate Post-training Quantization for Diffusion Models
Changyuan Wang, Ziwei Wang, Xiuwei Xu, Yansong Tang, Jie Zhou, Jiwen Lu
0
0
In this paper, we propose an accurate data-free post-training quantization framework of diffusion models (ADP-DM) for efficient image generation. Conventional data-free quantization methods learn shared quantization functions for tensor discretization regardless of the generation timesteps, while the activation distribution differs significantly across various timesteps. The calibration images are acquired in random timesteps which fail to provide sufficient information for generalizable quantization function learning. Both issues cause sizable quantization errors with obvious image generation performance degradation. On the contrary, we design group-wise quantization functions for activation discretization in different timesteps and sample the optimal timestep for informative calibration image generation, so that our quantized diffusion model can reduce the discretization errors with negligible computational overhead. Specifically, we partition the timesteps according to the importance weights of quantization functions in different groups, which are optimized by differentiable search algorithms. We also select the optimal timestep for calibration image generation by structural risk minimizing principle in order to enhance the generalization ability in the deployment of quantized diffusion model. Extensive experimental results show that our method outperforms the state-of-the-art post-training quantization of diffusion model by a sizable margin with similar computational cost.
5/1/2024
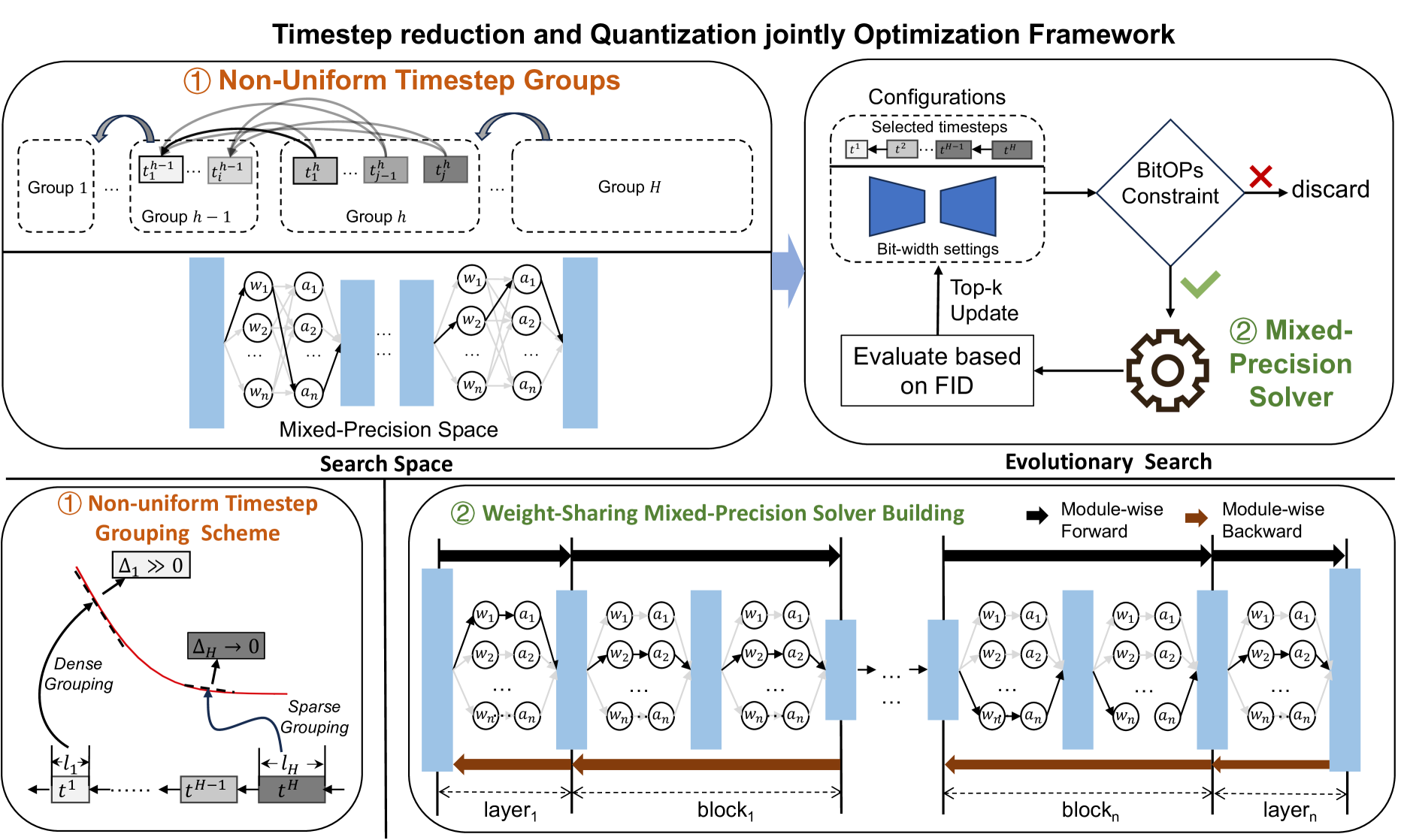
TMPQ-DM: Joint Timestep Reduction and Quantization Precision Selection for Efficient Diffusion Models
Haojun Sun, Chen Tang, Zhi Wang, Yuan Meng, Jingyan jiang, Xinzhu Ma, Wenwu Zhu
0
0
Diffusion models have emerged as preeminent contenders in the realm of generative models. Distinguished by their distinctive sequential generative processes, characterized by hundreds or even thousands of timesteps, diffusion models progressively reconstruct images from pure Gaussian noise, with each timestep necessitating full inference of the entire model. However, the substantial computational demands inherent to these models present challenges for deployment, quantization is thus widely used to lower the bit-width for reducing the storage and computing overheads. Current quantization methodologies primarily focus on model-side optimization, disregarding the temporal dimension, such as the length of the timestep sequence, thereby allowing redundant timesteps to continue consuming computational resources, leaving substantial scope for accelerating the generative process. In this paper, we introduce TMPQ-DM, which jointly optimizes timestep reduction and quantization to achieve a superior performance-efficiency trade-off, addressing both temporal and model optimization aspects. For timestep reduction, we devise a non-uniform grouping scheme tailored to the non-uniform nature of the denoising process, thereby mitigating the explosive combinations of timesteps. In terms of quantization, we adopt a fine-grained layer-wise approach to allocate varying bit-widths to different layers based on their respective contributions to the final generative performance, thus rectifying performance degradation observed in prior studies. To expedite the evaluation of fine-grained quantization, we further devise a super-network to serve as a precision solver by leveraging shared quantization results. These two design components are seamlessly integrated within our framework, enabling rapid joint exploration of the exponentially large decision space via a gradient-free evolutionary search algorithm.
4/16/2024