EfficientDM: Efficient Quantization-Aware Fine-Tuning of Low-Bit Diffusion Models
2310.03270
0
0
🏷️
Abstract
Diffusion models have demonstrated remarkable capabilities in image synthesis and related generative tasks. Nevertheless, their practicality for real-world applications is constrained by substantial computational costs and latency issues. Quantization is a dominant way to compress and accelerate diffusion models, where post-training quantization (PTQ) and quantization-aware training (QAT) are two main approaches, each bearing its own properties. While PTQ exhibits efficiency in terms of both time and data usage, it may lead to diminished performance in low bit-width. On the other hand, QAT can alleviate performance degradation but comes with substantial demands on computational and data resources. In this paper, we introduce a data-free and parameter-efficient fine-tuning framework for low-bit diffusion models, dubbed EfficientDM, to achieve QAT-level performance with PTQ-like efficiency. Specifically, we propose a quantization-aware variant of the low-rank adapter (QALoRA) that can be merged with model weights and jointly quantized to low bit-width. The fine-tuning process distills the denoising capabilities of the full-precision model into its quantized counterpart, eliminating the requirement for training data. We also introduce scale-aware optimization and temporal learned step-size quantization to further enhance performance. Extensive experimental results demonstrate that our method significantly outperforms previous PTQ-based diffusion models while maintaining similar time and data efficiency. Specifically, there is only a 0.05 sFID increase when quantizing both weights and activations of LDM-4 to 4-bit on ImageNet 256x256. Compared to QAT-based methods, our EfficientDM also boasts a 16.2x faster quantization speed with comparable generation quality. Code is available at href{https://github.com/ThisisBillhe/EfficientDM}{this hrl}.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Diffusion models have shown impressive capabilities in image synthesis, but their practical use is limited by high computational costs and latency.
- Quantization is a way to compress and speed up diffusion models, with post-training quantization (PTQ) and quantization-aware training (QAT) as the main approaches.
- PTQ is efficient in time and data usage, but can degrade performance at low bit-widths. QAT can maintain performance but requires more computational and data resources.
- This paper introduces EfficientDM, a data-free and parameter-efficient fine-tuning framework to achieve QAT-level performance with PTQ-like efficiency for low-bit diffusion models.
Plain English Explanation
Diffusion models are a type of machine learning technique that have become very good at generating new images. However, using diffusion models in real-world applications can be challenging because they require a lot of computing power and time to run.
One way to make diffusion models more practical is to compress and speed them up using a process called quantization. There are two main approaches to quantization: post-training quantization (PTQ) and quantization-aware training (QAT). PTQ is efficient in terms of both time and the amount of data needed, but it can reduce the quality of the generated images when using very low-bit representations. QAT can maintain image quality, but it requires a lot more computing power and training data.
The researchers in this paper introduce a new method called EfficientDM that aims to get the best of both worlds. EfficientDM can compress diffusion models to low bit-widths while maintaining high-quality image generation, and it can do so without needing a large amount of training data. The key ideas are:
- Using a "quantization-aware variant of the low-rank adapter" that can be combined with the model's weights and quantized together.
- Distilling the denoising capabilities of the full-precision model into the quantized model, so no additional training data is required.
- Introducing some other optimizations like "scale-aware optimization" and "temporal learned step-size quantization" to further improve performance.
The researchers show that EfficientDM significantly outperforms previous PTQ-based methods while being just as efficient in terms of time and data usage. It also compares favorably to QAT-based methods, being 16.2x faster at quantization while maintaining similar image generation quality.
Technical Explanation
The key technical contributions of this paper are:
-
Quantization-Aware Low-Rank Adapter (QALoRA): The authors propose a quantization-aware variant of the low-rank adapter (LoRA) technique, which can be merged with the model's weights and jointly quantized to low bit-widths. This allows the quantized model to maintain the denoising capability of the full-precision model.
-
Data-Free Fine-Tuning: The authors develop a data-free fine-tuning process that distills the denoising capabilities of the full-precision diffusion model into its quantized counterpart, eliminating the need for training data.
-
Scale-Aware Optimization: The authors introduce scale-aware optimization to better handle the dynamic range of activations during quantization, improving the quantized model's performance.
-
Temporal Learned Step-Size Quantization: The authors propose a temporal learned step-size quantization scheme that adaptively adjusts the quantization step size based on the diffusion process, further enhancing the quantized model's performance.
The authors extensively evaluate their EfficientDM framework on various diffusion models and datasets. They show that EfficientDM can achieve QAT-level performance while being as efficient as PTQ in terms of time and data usage. For example, when quantizing both weights and activations of the LDM-4 model on ImageNet 256x256 to 4-bit, there is only a 0.05 sFID (Sliced Fréchet Inception Distance) increase compared to the full-precision model. Additionally, EfficientDM is 16.2x faster than QAT-based methods for quantization while maintaining comparable generation quality.
Critical Analysis
The paper presents a promising approach to accelerating diffusion models for practical applications. By leveraging quantization-aware techniques and data-free fine-tuning, the authors are able to achieve significant speedups without major compromises in image generation quality.
However, the paper does not address some potential limitations. For example, the performance of EfficientDM may degrade on more complex or diverse datasets beyond ImageNet. Additionally, the paper does not explore the impact of EfficientDM on other diffusion-based tasks, such as text-to-image generation or lossy image compression.
Further research could also investigate the scalability of EfficientDM to larger diffusion models, as well as its compatibility with other model compression techniques, such as weight binarization or memory footprint reduction. Exploring these aspects could help establish the broader applicability and robustness of the proposed approach.
Conclusion
This paper introduces EfficientDM, a data-free and parameter-efficient fine-tuning framework for compressing and accelerating diffusion models. By leveraging quantization-aware techniques and novel optimization methods, EfficientDM is able to achieve QAT-level performance with PTQ-like efficiency, significantly outperforming previous PTQ-based methods.
The key innovations of EfficientDM, including the quantization-aware low-rank adapter and the data-free fine-tuning process, demonstrate the potential for making diffusion models more practical for real-world applications. The impressive results on image generation tasks suggest that this approach could have a significant impact on the wider adoption of diffusion models in various domains.
As the field of diffusion models continues to evolve, the insights and techniques presented in this paper may inspire further research to unlock the full potential of these powerful generative models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔍
Towards Accurate Post-training Quantization for Diffusion Models
Changyuan Wang, Ziwei Wang, Xiuwei Xu, Yansong Tang, Jie Zhou, Jiwen Lu
0
0
In this paper, we propose an accurate data-free post-training quantization framework of diffusion models (ADP-DM) for efficient image generation. Conventional data-free quantization methods learn shared quantization functions for tensor discretization regardless of the generation timesteps, while the activation distribution differs significantly across various timesteps. The calibration images are acquired in random timesteps which fail to provide sufficient information for generalizable quantization function learning. Both issues cause sizable quantization errors with obvious image generation performance degradation. On the contrary, we design group-wise quantization functions for activation discretization in different timesteps and sample the optimal timestep for informative calibration image generation, so that our quantized diffusion model can reduce the discretization errors with negligible computational overhead. Specifically, we partition the timesteps according to the importance weights of quantization functions in different groups, which are optimized by differentiable search algorithms. We also select the optimal timestep for calibration image generation by structural risk minimizing principle in order to enhance the generalization ability in the deployment of quantized diffusion model. Extensive experimental results show that our method outperforms the state-of-the-art post-training quantization of diffusion model by a sizable margin with similar computational cost.
5/1/2024
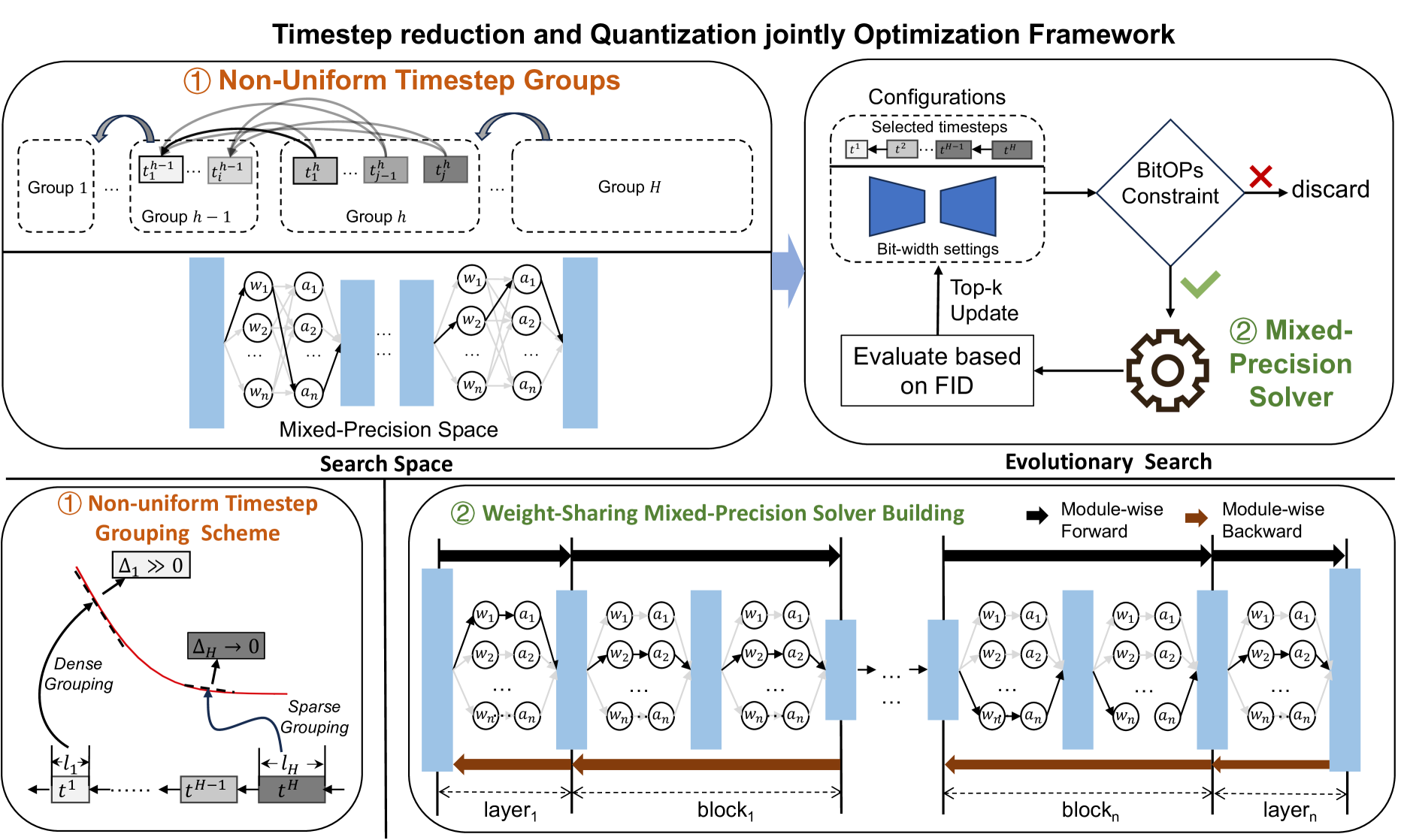
TMPQ-DM: Joint Timestep Reduction and Quantization Precision Selection for Efficient Diffusion Models
Haojun Sun, Chen Tang, Zhi Wang, Yuan Meng, Jingyan jiang, Xinzhu Ma, Wenwu Zhu
0
0
Diffusion models have emerged as preeminent contenders in the realm of generative models. Distinguished by their distinctive sequential generative processes, characterized by hundreds or even thousands of timesteps, diffusion models progressively reconstruct images from pure Gaussian noise, with each timestep necessitating full inference of the entire model. However, the substantial computational demands inherent to these models present challenges for deployment, quantization is thus widely used to lower the bit-width for reducing the storage and computing overheads. Current quantization methodologies primarily focus on model-side optimization, disregarding the temporal dimension, such as the length of the timestep sequence, thereby allowing redundant timesteps to continue consuming computational resources, leaving substantial scope for accelerating the generative process. In this paper, we introduce TMPQ-DM, which jointly optimizes timestep reduction and quantization to achieve a superior performance-efficiency trade-off, addressing both temporal and model optimization aspects. For timestep reduction, we devise a non-uniform grouping scheme tailored to the non-uniform nature of the denoising process, thereby mitigating the explosive combinations of timesteps. In terms of quantization, we adopt a fine-grained layer-wise approach to allocate varying bit-widths to different layers based on their respective contributions to the final generative performance, thus rectifying performance degradation observed in prior studies. To expedite the evaluation of fine-grained quantization, we further devise a super-network to serve as a precision solver by leveraging shared quantization results. These two design components are seamlessly integrated within our framework, enabling rapid joint exploration of the exponentially large decision space via a gradient-free evolutionary search algorithm.
4/16/2024

BinaryDM: Towards Accurate Binarization of Diffusion Model
Xingyu Zheng, Haotong Qin, Xudong Ma, Mingyuan Zhang, Haojie Hao, Jiakai Wang, Zixiang Zhao, Jinyang Guo, Xianglong Liu
0
0
With the advancement of diffusion models (DMs) and the substantially increased computational requirements, quantization emerges as a practical solution to obtain compact and efficient low-bit DMs. However, the highly discrete representation leads to severe accuracy degradation, hindering the quantization of diffusion models to ultra-low bit-widths. In this paper, we propose BinaryDM, a novel accurate quantization-aware training approach to push the weights of diffusion models towards the limit of 1-bit. Firstly, we present a Learnable Multi-basis Binarizer (LMB) to recover the representations generated by the binarized DM, which improves the information in details of representations crucial to the DM. Secondly, a Low-rank Representation Mimicking (LRM) is applied to enhance the binarization-aware optimization of the DM, alleviating the optimization direction ambiguity caused by fine-grained alignment. Moreover, a progressive initialization strategy is applied to training DMs to avoid convergence difficulties. Comprehensive experiments demonstrate that BinaryDM achieves significant accuracy and efficiency gains compared to SOTA quantization methods of DMs under ultra-low bit-widths. As the first binarization method for diffusion models, BinaryDM achieves impressive 16.0 times FLOPs and 27.1 times storage savings with 1-bit weight and 4-bit activation, showcasing its substantial advantages and potential for deploying DMs on resource-limited scenarios.
4/9/2024
💬
QLLM: Accurate and Efficient Low-Bitwidth Quantization for Large Language Models
Jing Liu, Ruihao Gong, Xiuying Wei, Zhiwei Dong, Jianfei Cai, Bohan Zhuang
0
0
Large Language Models (LLMs) excel in NLP, but their demands hinder their widespread deployment. While Quantization-Aware Training (QAT) offers a solution, its extensive training costs make Post-Training Quantization (PTQ) a more practical approach for LLMs. In existing studies, activation outliers in particular channels are identified as the bottleneck to PTQ accuracy. They propose to transform the magnitudes from activations to weights, which however offers limited alleviation or suffers from unstable gradients, resulting in a severe performance drop at low-bitwidth. In this paper, we propose QLLM, an accurate and efficient low-bitwidth PTQ method designed for LLMs. QLLM introduces an adaptive channel reassembly technique that reallocates the magnitude of outliers to other channels, thereby mitigating their impact on the quantization range. This is achieved by channel disassembly and channel assembly, which first breaks down the outlier channels into several sub-channels to ensure a more balanced distribution of activation magnitudes. Then similar channels are merged to maintain the original channel number for efficiency. Additionally, an adaptive strategy is designed to autonomously determine the optimal number of sub-channels for channel disassembly. To further compensate for the performance loss caused by quantization, we propose an efficient tuning method that only learns a small number of low-rank weights while freezing the pre-trained quantized model. After training, these low-rank parameters can be fused into the frozen weights without affecting inference. Extensive experiments on LLaMA-1 and LLaMA-2 show that QLLM can obtain accurate quantized models efficiently. For example, QLLM quantizes the 4-bit LLaMA-2-70B within 10 hours on a single A100-80G GPU, outperforming the previous state-of-the-art method by 7.89% on the average accuracy across five zero-shot tasks.
4/9/2024