Analysis of the Two-Step Heterogeneous Transfer Learning for Laryngeal Blood Vessel Classification: Issue and Improvement

0

Sign in to get full access
Overview
- This paper analyzes issues with a two-step heterogeneous transfer learning approach for classifying laryngeal blood vessels and proposes improvements.
- Heterogeneous transfer learning involves adapting models trained on one type of data (e.g. natural images) to perform well on a different type of data (e.g. medical images).
- The authors identify limitations in previous work using this approach for laryngeal blood vessel classification and suggest ways to address them.
Plain English Explanation
The paper looks at a technique called "two-step heterogeneous transfer learning" that researchers have used to classify images of blood vessels in the larynx (voice box). This involves taking a model trained on one type of data, like normal photos, and adapting it to work well on a different type of data, like medical images of the larynx.
The authors found some issues with how this technique had been used before for classifying laryngeal blood vessels. They propose ways to improve the approach to make it work better. The key ideas are to modify how the model is adapted to the new medical image data and to incorporate additional information about the blood vessels themselves.
Technical Explanation
The paper analyzes the use of a two-step heterogeneous transfer learning approach for the task of laryngeal blood vessel classification. This involves first training a model on a large dataset of natural images, then fine-tuning that model on a smaller medical image dataset to adapt it to the new domain.
The authors identify limitations in prior work using this approach, such as:
- Insufficient fine-tuning of the pre-trained model on the target medical data
- Lack of exploitation of anatomical knowledge about blood vessel structures
To address these issues, the authors propose modifications to the transfer learning pipeline, including:
- More extensive fine-tuning of the pre-trained model on the target medical data
- Incorporating shape priors about blood vessel morphology into the model architecture
Through experiments on a laryngeal blood vessel dataset, the authors demonstrate that their improved two-step transfer learning approach outperforms the previous state-of-the-art methods.
Critical Analysis
The paper provides a thoughtful analysis of the shortcomings of prior work using two-step heterogeneous transfer learning for laryngeal blood vessel classification. The proposed improvements, such as more thorough fine-tuning and incorporating anatomical knowledge, seem well-justified and likely to yield performance gains.
However, the paper does not fully address the potential limitations of the underlying transfer learning approach. For example, there may be inherent challenges in adapting models trained on natural images to work well on highly specialized medical data, regardless of the fine-tuning approach.
Additionally, the reliance on shape priors raises questions about the generalizability of the method - it may perform well on this specific laryngeal blood vessel task, but its effectiveness could be limited when applied to other medical image classification problems with different anatomical structures.
Further research would be needed to better understand the broader applicability and limitations of the authors' proposed techniques.
Conclusion
This paper presents an analysis of issues with using two-step heterogeneous transfer learning for laryngeal blood vessel classification, along with proposed improvements to address those limitations. The key ideas are to perform more extensive fine-tuning of the pre-trained model and to incorporate anatomical knowledge about blood vessel shapes.
While the authors demonstrate that their approach outperforms prior methods, there are still open questions about the general applicability of two-step transfer learning to medical image classification tasks. Continued research in this area could lead to more robust and versatile techniques for adapting computer vision models to specialized domains like healthcare.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Analysis of the Two-Step Heterogeneous Transfer Learning for Laryngeal Blood Vessel Classification: Issue and Improvement
Xinyi Fang, Xu Yang, Chak Fong Chong, Kei Long Wong, Yapeng Wang, Tiankui Zhang, Sio-Kei Im
Accurate classification of laryngeal vascular as benign or malignant is crucial for early detection of laryngeal cancer. However, organizations with limited access to laryngeal vascular images face challenges due to the lack of large and homogeneous public datasets for effective learning. Distinguished from the most familiar works, which directly transfer the ImageNet pre-trained models to the target domain for fine-tuning, this work pioneers exploring two-step heterogeneous transfer learning (THTL) for laryngeal lesion classification with nine deep-learning models, utilizing the diabetic retinopathy color fundus images, semantically non-identical yet vascular images, as the intermediate domain. Attention visualization technique, Layer Class Activate Map (LayerCAM), reveals a novel finding that yet the intermediate and the target domain both reflect vascular structure to a certain extent, the prevalent radial vascular pattern in the intermediate domain prevents learning the features of twisted and tangled vessels that distinguish the malignant class in the target domain, summarizes a vital rule for laryngeal lesion classification using THTL. To address this, we introduce an enhanced fine-tuning strategy in THTL called Step-Wise Fine-Tuning (SWFT) and apply it to the ResNet models. SWFT progressively refines model performance by accumulating fine-tuning layers from back to front, guided by the visualization results of LayerCAM. Comparison with the original THTL approach shows significant improvements. For ResNet18, the accuracy and malignant recall increases by 26.1% and 79.8%, respectively, while for ResNet50, these indicators improve by 20.4% and 62.2%, respectively.
Read more4/16/2024
0
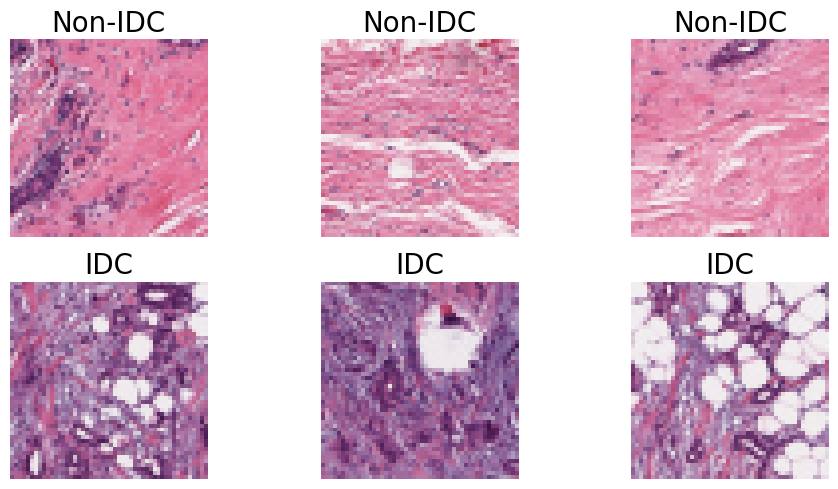
Comparative Analysis of Transfer Learning Models for Breast Cancer Classification
Sania Eskandari, Ali Eslamian, Qiang Cheng
The classification of histopathological images is crucial for the early and precise detection of breast cancer. This study investigates the efficiency of deep learning models in distinguishing between Invasive Ductal Carcinoma (IDC) and non-IDC in histopathology slides. We conducted a thorough comparison examination of eight sophisticated models: ResNet-50, DenseNet-121, ResNeXt-50, Vision Transformer (ViT), GoogLeNet (Inception v3), EfficientNet, MobileNet, and SqueezeNet. This analysis was carried out using a large dataset of 277,524 image patches. Our research makes a substantial contribution to the field by offering a comprehensive assessment of the performance of each model. We particularly highlight the exceptional efficacy of attention-based mechanisms in the ViT model, which achieved a remarkable validation accuracy of 93%, surpassing conventional convolutional networks. This study highlights the promise of advanced machine learning approaches in clinical settings, offering improved precision as well as efficiency in breast cancer diagnosis.
Read more9/2/2024
0
Explainable Convolutional Neural Networks for Retinal Fundus Classification and Cutting-Edge Segmentation Models for Retinal Blood Vessels from Fundus Images
Fatema Tuj Johora Faria, Mukaffi Bin Moin, Pronay Debnath, Asif Iftekher Fahim, Faisal Muhammad Shah
Our research focuses on the critical field of early diagnosis of disease by examining retinal blood vessels in fundus images. While automatic segmentation of retinal blood vessels holds promise for early detection, accurate analysis remains challenging due to the limitations of existing methods, which often lack discrimination power and are susceptible to influences from pathological regions. Our research in fundus image analysis advances deep learning-based classification using eight pre-trained CNN models. To enhance interpretability, we utilize Explainable AI techniques such as Grad-CAM, Grad-CAM++, Score-CAM, Faster Score-CAM, and Layer CAM. These techniques illuminate the decision-making processes of the models, fostering transparency and trust in their predictions. Expanding our exploration, we investigate ten models, including TransUNet with ResNet backbones, Attention U-Net with DenseNet and ResNet backbones, and Swin-UNET. Incorporating diverse architectures such as ResNet50V2, ResNet101V2, ResNet152V2, and DenseNet121 among others, this comprehensive study deepens our insights into attention mechanisms for enhanced fundus image analysis. Among the evaluated models for fundus image classification, ResNet101 emerged with the highest accuracy, achieving an impressive 94.17%. On the other end of the spectrum, EfficientNetB0 exhibited the lowest accuracy among the models, achieving a score of 88.33%. Furthermore, in the domain of fundus image segmentation, Swin-Unet demonstrated a Mean Pixel Accuracy of 86.19%, showcasing its effectiveness in accurately delineating regions of interest within fundus images. Conversely, Attention U-Net with DenseNet201 backbone exhibited the lowest Mean Pixel Accuracy among the evaluated models, achieving a score of 75.87%.
Read more5/14/2024
👀
0
A vision transformer-based framework for knowledge transfer from multi-modal to mono-modal lymphoma subtyping models
Bilel Guetarni, Feryal Windal, Halim Benhabiles, Marianne Petit, Romain Dubois, Emmanuelle Leteurtre, Dominique Collard
Determining lymphoma subtypes is a crucial step for better patient treatment targeting to potentially increase their survival chances. In this context, the existing gold standard diagnosis method, which relies on gene expression technology, is highly expensive and time-consuming, making it less accessibility. Although alternative diagnosis methods based on IHC (immunohistochemistry) technologies exist (recommended by the WHO), they still suffer from similar limitations and are less accurate. Whole Slide Image (WSI) analysis using deep learning models has shown promising potential for cancer diagnosis, that could offer cost-effective and faster alternatives to existing methods. In this work, we propose a vision transformer-based framework for distinguishing DLBCL (Diffuse Large B-Cell Lymphoma) cancer subtypes from high-resolution WSIs. To this end, we introduce a multi-modal architecture to train a classifier model from various WSI modalities. We then leverage this model through a knowledge distillation process to efficiently guide the learning of a mono-modal classifier. Our experimental study conducted on a lymphoma dataset of 157 patients shows the promising performance of our mono-modal classification model, outperforming six recent state-of-the-art methods. In addition, the power-law curve, estimated on our experimental data, suggests that with more training data from a reasonable number of additional patients, our model could achieve competitive diagnosis accuracy with IHC technologies. Furthermore, the efficiency of our framework is confirmed through an additional experimental study on an external breast cancer dataset (BCI dataset).
Read more5/30/2024