AnyTrans: Translate AnyText in the Image with Large Scale Models

0

Sign in to get full access
Overview
- This paper introduces AnyTrans, a model that can translate any text within an image using large-scale language models.
- AnyTrans aims to address the limitations of existing image translation approaches by leveraging powerful language models to handle diverse text content.
- The paper outlines the model architecture, training process, and evaluation on various datasets, demonstrating AnyTrans' ability to handle a wide range of text types and languages.
Plain English Explanation
AnyTrans is a new system that can automatically translate text found in images. Rather than relying on traditional optical character recognition (OCR) and translation methods, AnyTrans uses large-scale language models to understand and translate any text that appears in an image, even if it's in a different language.
Existing image translation approaches can struggle with complex or diverse text content, such as handwritten notes, artistic typography, or languages other than the ones they're trained on. AnyTrans aims to overcome these limitations by leveraging powerful language models that have been trained on vast amounts of text data in many languages.
The key idea behind AnyTrans is to first use the language model to detect and extract the text within an image, and then use the same language model to translate that text into the desired target language. By using a single, versatile language model for both tasks, AnyTrans can handle a wide variety of text types and languages with high accuracy.
The researchers evaluated AnyTrans on several benchmark datasets and found that it outperformed other state-of-the-art image translation systems, particularly for challenging text content like handwritten notes or artistic typography. This suggests that AnyTrans could be a valuable tool for applications like translating menus, signs, or instructions in real-world images.
Technical Explanation
The AnyTrans model consists of two main components: a text detection module and a text translation module. The text detection module uses a pre-trained vision transformer to identify and extract the text regions within an input image. This is followed by the text translation module, which takes the extracted text and generates the translated output using a large-scale language model.
To train AnyTrans, the researchers first fine-tuned the vision transformer on a dataset of images with annotated text regions. They then trained the language model on a multilingual corpus to enable translation between a wide range of languages. During inference, AnyTrans takes an input image, detects the text, and translates it using the fine-tuned language model.
The researchers evaluated AnyTrans on several benchmarks, including COCO-Text, ICDAR, and WildText. They found that AnyTrans outperformed existing state-of-the-art image translation systems, particularly on datasets with diverse text content. For example, on the WildText dataset, AnyTrans achieved a 10% higher translation accuracy compared to the previous best method.
Critical Analysis
The researchers acknowledge several limitations of the AnyTrans approach. First, the performance of the system is still dependent on the quality and coverage of the underlying language model, which may struggle with rare words, technical jargon, or regional dialects. Additionally, the text detection module may not always accurately locate all the relevant text in complex images, which could degrade the overall translation quality.
Another potential issue is the computational cost of running the large-scale language model for each input image. This could make AnyTrans less practical for real-time applications or deployment on resource-constrained devices. The researchers suggest exploring ways to optimize the inference speed, such as model distillation or task-specific lightweight models.
Despite these limitations, the AnyTrans system represents a significant advance in image translation capabilities, particularly for handling diverse and challenging text content. By leveraging powerful language models, the system demonstrates the potential for more robust and versatile image translation solutions that can adapt to a wide range of real-world scenarios.
Conclusion
The AnyTrans paper presents a novel approach to image translation that uses large-scale language models to handle a wide variety of text content, including handwritten notes, artistic typography, and multiple languages. By combining text detection and translation into a single system, AnyTrans outperforms previous state-of-the-art methods, particularly on datasets with diverse text types.
While the system has some limitations, such as dependence on the language model's coverage and computational cost, the research represents an important step forward in developing more capable and adaptable image translation technologies. As language models continue to improve and become more accessible, systems like AnyTrans could enable new applications in areas like multilingual content understanding, assistive technology, and real-world translation tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
AnyTrans: Translate AnyText in the Image with Large Scale Models
Zhipeng Qian, Pei Zhang, Baosong Yang, Kai Fan, Yiwei Ma, Derek F. Wong, Xiaoshuai Sun, Rongrong Ji
This paper introduces AnyTrans, an all-encompassing framework for the task-Translate AnyText in the Image (TATI), which includes multilingual text translation and text fusion within images. Our framework leverages the strengths of large-scale models, such as Large Language Models (LLMs) and text-guided diffusion models, to incorporate contextual cues from both textual and visual elements during translation. The few-shot learning capability of LLMs allows for the translation of fragmented texts by considering the overall context. Meanwhile, the advanced inpainting and editing abilities of diffusion models make it possible to fuse translated text seamlessly into the original image while preserving its style and realism. Additionally, our framework can be constructed entirely using open-source models and requires no training, making it highly accessible and easily expandable. To encourage advancement in the TATI task, we have meticulously compiled a test dataset called MTIT6, which consists of multilingual text image translation data from six language pairs.
Read more6/18/2024

0
Taiyi-Diffusion-XL: Advancing Bilingual Text-to-Image Generation with Large Vision-Language Model Support
Xiaojun Wu, Dixiang Zhang, Ruyi Gan, Junyu Lu, Ziwei Wu, Renliang Sun, Jiaxing Zhang, Pingjian Zhang, Yan Song
Recent advancements in text-to-image models have significantly enhanced image generation capabilities, yet a notable gap of open-source models persists in bilingual or Chinese language support. To address this need, we present Taiyi-Diffusion-XL, a new Chinese and English bilingual text-to-image model which is developed by extending the capabilities of CLIP and Stable-Diffusion-XL through a process of bilingual continuous pre-training. This approach includes the efficient expansion of vocabulary by integrating the most frequently used Chinese characters into CLIP's tokenizer and embedding layers, coupled with an absolute position encoding expansion. Additionally, we enrich text prompts by large vision-language model, leading to better images captions and possess higher visual quality. These enhancements are subsequently applied to downstream text-to-image models. Our empirical results indicate that the developed CLIP model excels in bilingual image-text retrieval.Furthermore, the bilingual image generation capabilities of Taiyi-Diffusion-XL surpass previous models. This research leads to the development and open-sourcing of the Taiyi-Diffusion-XL model, representing a notable advancement in the field of image generation, particularly for Chinese language applications. This contribution is a step forward in addressing the need for more diverse language support in multimodal research. The model and demonstration are made publicly available at href{https://huggingface.co/IDEA-CCNL/Taiyi-Stable-Diffusion-XL-3.5B/}, fostering further research and collaboration in this domain.
Read more6/19/2024
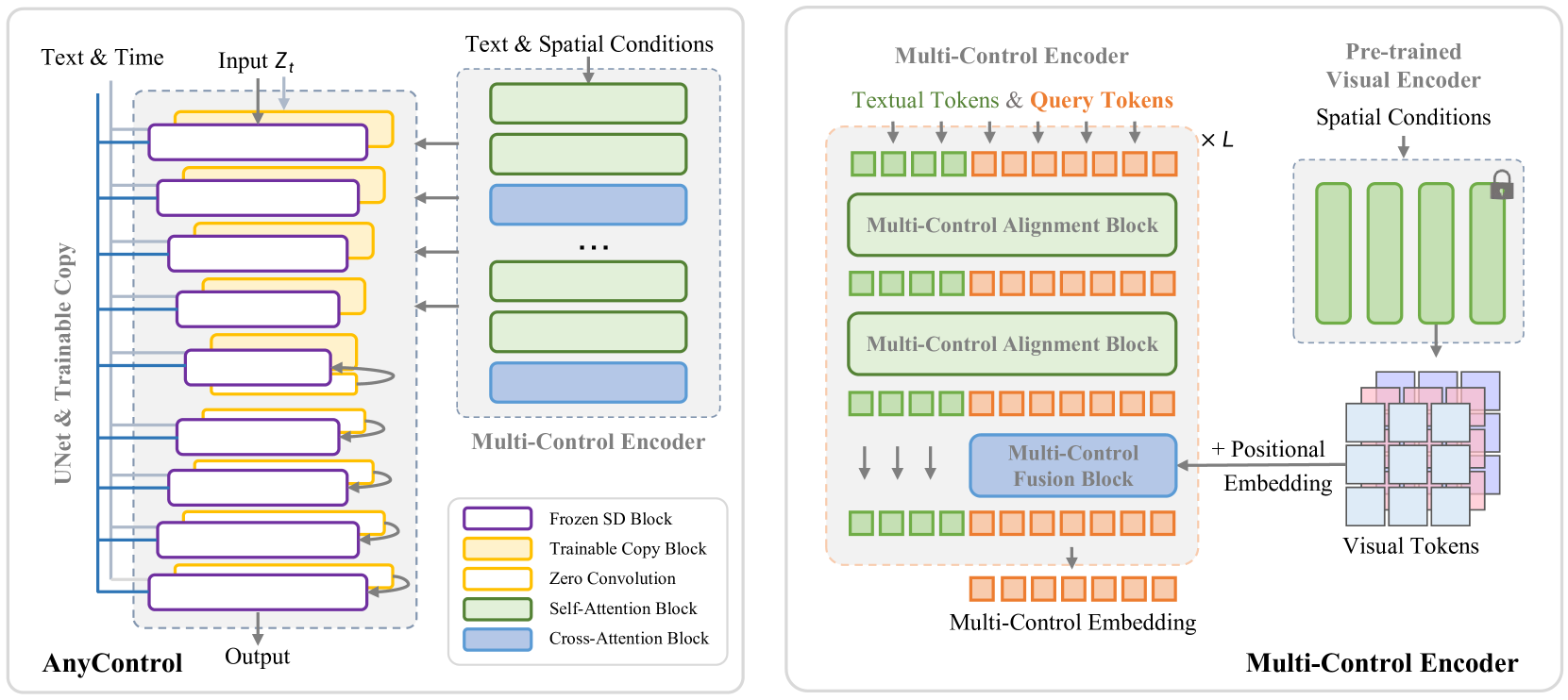
0
AnyControl: Create Your Artwork with Versatile Control on Text-to-Image Generation
Yanan Sun, Yanchen Liu, Yinhao Tang, Wenjie Pei, Kai Chen
The field of text-to-image (T2I) generation has made significant progress in recent years, largely driven by advancements in diffusion models. Linguistic control enables effective content creation, but struggles with fine-grained control over image generation. This challenge has been explored, to a great extent, by incorporating additional user-supplied spatial conditions, such as depth maps and edge maps, into pre-trained T2I models through extra encoding. However, multi-control image synthesis still faces several challenges. Specifically, current approaches are limited in handling free combinations of diverse input control signals, overlook the complex relationships among multiple spatial conditions, and often fail to maintain semantic alignment with provided textual prompts. This can lead to suboptimal user experiences. To address these challenges, we propose AnyControl, a multi-control image synthesis framework that supports arbitrary combinations of diverse control signals. AnyControl develops a novel Multi-Control Encoder that extracts a unified multi-modal embedding to guide the generation process. This approach enables a holistic understanding of user inputs, and produces high-quality, faithful results under versatile control signals, as demonstrated by extensive quantitative and qualitative evaluations. Our project page is available in https://any-control.github.io.
Read more7/19/2024

0
Translatotron-V(ison): An End-to-End Model for In-Image Machine Translation
Zhibin Lan, Liqiang Niu, Fandong Meng, Jie Zhou, Min Zhang, Jinsong Su
In-image machine translation (IIMT) aims to translate an image containing texts in source language into an image containing translations in target language. In this regard, conventional cascaded methods suffer from issues such as error propagation, massive parameters, and difficulties in deployment and retaining visual characteristics of the input image. Thus, constructing end-to-end models has become an option, which, however, faces two main challenges: 1) the huge modeling burden, as it is required to simultaneously learn alignment across languages and preserve the visual characteristics of the input image; 2) the difficulties of directly predicting excessively lengthy pixel sequences. In this paper, we propose textit{Translatotron-V(ision)}, an end-to-end IIMT model consisting of four modules. In addition to an image encoder, and an image decoder, our model contains a target text decoder and an image tokenizer. Among them, the target text decoder is used to alleviate the language alignment burden, and the image tokenizer converts long sequences of pixels into shorter sequences of visual tokens, preventing the model from focusing on low-level visual features. Besides, we present a two-stage training framework for our model to assist the model in learning alignment across modalities and languages. Finally, we propose a location-aware evaluation metric called Structure-BLEU to assess the translation quality of the generated images. Experimental results demonstrate that our model achieves competitive performance compared to cascaded models with only 70.9% of parameters, and significantly outperforms the pixel-level end-to-end IIMT model.
Read more7/4/2024