Approximate UMAP allows for high-rate online visualization of high-dimensional data streams

0
Sign in to get full access
Overview
- The paper presents a method for approximating the UMAP dimensionality reduction algorithm, which allows for high-rate online visualization of high-dimensional data streams.
- Accurate dimensionality reduction is crucial for visualizing and understanding high-dimensional data, but existing methods can be computationally expensive, making them unsuitable for real-time applications.
- The proposed approximate UMAP approach aims to address this limitation by providing a fast, efficient alternative that maintains the accuracy and properties of the original UMAP algorithm.
Plain English Explanation
Visualizing and understanding high-dimensional data, such as the data generated by modern sensors and experiments, is a challenging problem. Interpretable Dimensionality Reduction by Feature-Preserving Manifold and Visual Decoding Reconstruction via EEG Embeddings Guided are examples of techniques used to tackle this challenge.
The UMAP algorithm is a powerful tool for reducing the dimensionality of high-dimensional data while preserving the underlying structure. However, the original UMAP algorithm can be computationally expensive, making it difficult to use in real-time applications where data is constantly being generated, such as Towards Transcranial 3D Ultrasound Localization Microscopy Nonhuman or Computationally Efficient Unsupervised Deep Learning Robust Joint.
The researchers in this paper have developed an approximate version of UMAP that is much faster and more efficient, while still maintaining the accuracy and properties of the original algorithm. This allows for high-rate online visualization of high-dimensional data streams, which could be useful in a wide range of applications, including Bridging Projection Gap Overcoming Projection Bias Through.
Technical Explanation
The paper introduces an approximate version of the UMAP dimensionality reduction algorithm that is designed for high-rate online visualization of high-dimensional data streams. The key idea is to use a faster, more efficient algorithm to approximate the original UMAP, while still preserving its accuracy and important properties.
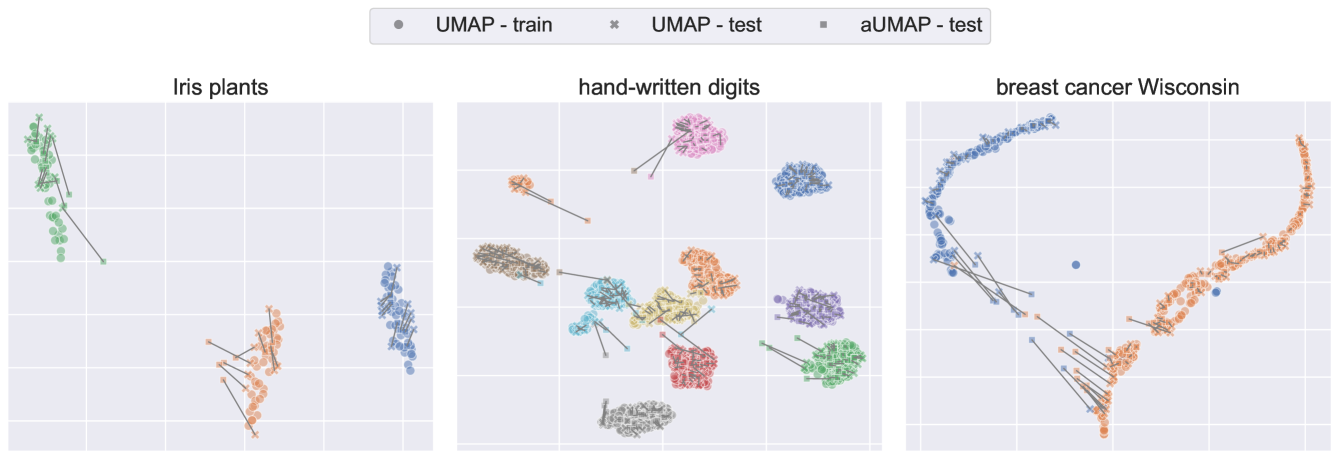
The researchers first provide a summary of the datasets used to evaluate the accuracy of their approximate UMAP approach. These datasets cover a range of high-dimensional data types, including image, text, and sensor data, to ensure a comprehensive evaluation.
The proposed approximate UMAP method is then described in detail. The algorithm uses a combination of techniques, such as subsampling and approximate nearest neighbor searches, to achieve a significant speedup over the original UMAP while maintaining the desired accuracy and properties.
The paper presents extensive experiments comparing the performance of the approximate UMAP to the original UMAP, as well as other dimensionality reduction methods. The results show that the approximate UMAP is able to achieve comparable or better accuracy than the original UMAP, while being much faster and more computationally efficient.
Critical Analysis
The paper presents a convincing approach for approximating the UMAP dimensionality reduction algorithm to enable high-rate online visualization of high-dimensional data streams. The researchers have carefully designed their experiments to evaluate the accuracy and performance of the approximate UMAP across a diverse set of datasets, which strengthens the credibility of their findings.
One potential limitation of the study is that it does not provide a detailed analysis of the specific trade-offs between accuracy and computational efficiency. While the results show that the approximate UMAP can match or exceed the accuracy of the original UMAP, it would be helpful to understand the precise conditions under which this holds true, and the cases where the approximate UMAP may fall short.
Additionally, the paper does not address the potential impact of the approximation on the interpretability and quality of the visualizations generated by the UMAP algorithm. Since UMAP is often used for exploratory data analysis and hypothesis generation, it would be important to understand how the approximate version affects the insights that can be derived from the resulting visualizations.
Overall, the paper presents a valuable contribution to the field of dimensionality reduction, particularly for real-time applications. The researchers have demonstrated a promising approach to balancing accuracy and computational efficiency, which could have significant implications for a wide range of data-intensive domains.
Conclusion
The paper introduces an approximate version of the UMAP dimensionality reduction algorithm that is designed for high-rate online visualization of high-dimensional data streams. The key innovation is the use of a faster, more efficient algorithm to approximate the original UMAP, while still preserving its accuracy and important properties.
The researchers have conducted a comprehensive evaluation of their approach across a diverse set of datasets, demonstrating that the approximate UMAP can match or exceed the accuracy of the original UMAP while being much faster and more computationally efficient. This could have significant implications for real-time applications where high-dimensional data is constantly being generated, such as sensor-based monitoring, medical imaging, and online analytics.
Overall, the paper presents a valuable contribution to the field of dimensionality reduction, showcasing a promising approach to balancing accuracy and computational efficiency. As high-dimensional data continues to play an increasingly important role in various domains, the ability to visualize and understand these complex datasets in real-time will become increasingly crucial, making the insights from this research highly relevant and impactful.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Approximate UMAP allows for high-rate online visualization of high-dimensional data streams
Peter Wassenaar, Pierre Guetschel, Michael Tangermann
In the BCI field, introspection and interpretation of brain signals are desired for providing feedback or to guide rapid paradigm prototyping but are challenging due to the high noise level and dimensionality of the signals. Deep neural networks are often introspected by transforming their learned feature representations into 2- or 3-dimensional subspace visualizations using projection algorithms like Uniform Manifold Approximation and Projection (UMAP). Unfortunately, these methods are computationally expensive, making the projection of data streams in real-time a non-trivial task. In this study, we introduce a novel variant of UMAP, called approximate UMAP (aUMAP). It aims at generating rapid projections for real-time introspection. To study its suitability for real-time projecting, we benchmark the methods against standard UMAP and its neural network counterpart parametric UMAP. Our results show that approximate UMAP delivers projections that replicate the projection space of standard UMAP while decreasing projection speed by an order of magnitude and maintaining the same training time.
Read more4/8/2024
📉
0
CBMAP: Clustering-based manifold approximation and projection for dimensionality reduction
Berat Dogan
Dimensionality reduction methods are employed to decrease data dimensionality, either to enhance machine learning performance or to facilitate data visualization in two or three-dimensional spaces. These methods typically fall into two categories: feature selection and feature transformation. Feature selection retains significant features, while feature transformation projects data into a lower-dimensional space, with linear and nonlinear methods. While nonlinear methods excel in preserving local structures and capturing nonlinear relationships, they may struggle with interpreting global structures and can be computationally intensive. Recent algorithms, such as the t-SNE, UMAP, TriMap, and PaCMAP prioritize preserving local structures, often at the expense of accurately representing global structures, leading to clusters being spread out more in lower-dimensional spaces. Moreover, these methods heavily rely on hyperparameters, making their results sensitive to parameter settings. To address these limitations, this study introduces a clustering-based approach, namely CBMAP (Clustering-Based Manifold Approximation and Projection), for dimensionality reduction. CBMAP aims to preserve both global and local structures, ensuring that clusters in lower-dimensional spaces closely resemble those in high-dimensional spaces. Experimental evaluations on benchmark datasets demonstrate CBMAP's efficacy, offering speed, scalability, and minimal reliance on hyperparameters. Importantly, CBMAP enables low-dimensional projection of test data, addressing a critical need in machine learning applications. CBMAP is made freely available at https://github.com/doganlab/cbmap and can be installed from the Python Package Directory (PyPI) software repository with the command pip install cbmap.
Read more9/17/2024

0
Exploring UMAP in hybrid models of entropy-based and representativeness sampling for active learning in biomedical segmentation
H. S. Tan, Kuancheng Wang, Rafe Mcbeth
In this work, we study various hybrid models of entropy-based and representativeness sampling techniques in the context of active learning in medical segmentation, in particular examining the role of UMAP (Uniform Manifold Approximation and Projection) as a technique for capturing representativeness. Although UMAP has been shown viable as a general purpose dimension reduction method in diverse areas, its role in deep learning-based medical segmentation has yet been extensively explored. Using the cardiac and prostate datasets in the Medical Segmentation Decathlon for validation, we found that a novel hybrid combination of Entropy-UMAP sampling technique achieved a statistically significant Dice score advantage over the random baseline ($3.2 %$ for cardiac, $4.5 %$ for prostate), and attained the highest Dice coefficient among the spectrum of 10 distinct active learning methodologies we examined. This provides preliminary evidence that there is an interesting synergy between entropy-based and UMAP methods when the former precedes the latter in a hybrid model of active learning.
Read more5/28/2024
0
Outlier Detection in Large Radiological Datasets using UMAP
Mohammad Tariqul Islam, Jason W. Fleischer
The success of machine learning algorithms heavily relies on the quality of samples and the accuracy of their corresponding labels. However, building and maintaining large, high-quality datasets is an enormous task. This is especially true for biomedical data and for meta-sets that are compiled from smaller ones, as variations in image quality, labeling, reports, and archiving can lead to errors, inconsistencies, and repeated samples. Here, we show that the uniform manifold approximation and projection (UMAP) algorithm can find these anomalies essentially by forming independent clusters that are distinct from the main (good) data but similar to other points with the same error type. As a representative example, we apply UMAP to discover outliers in the publicly available ChestX-ray14, CheXpert, and MURA datasets. While the results are archival and retrospective and focus on radiological images, the graph-based methods work for any data type and will prove equally beneficial for curation at the time of dataset creation.
Read more8/2/2024