APTQ: Attention-aware Post-Training Mixed-Precision Quantization for Large Language Models
2402.14866
0
0
Abstract
Large Language Models (LLMs) have greatly advanced the natural language processing paradigm. However, the high computational load and huge model sizes pose a grand challenge for deployment on edge devices. To this end, we propose APTQ (Attention-aware Post-Training Mixed-Precision Quantization) for LLMs, which considers not only the second-order information of each layer's weights, but also, for the first time, the nonlinear effect of attention outputs on the entire model. We leverage the Hessian trace as a sensitivity metric for mixed-precision quantization, ensuring an informed precision reduction that retains model performance. Experiments show APTQ surpasses previous quantization methods, achieving an average of 4 bit width a 5.22 perplexity nearly equivalent to full precision in the C4 dataset. In addition, APTQ attains state-of-the-art zero-shot accuracy of 68.24% and 70.48% at an average bitwidth of 3.8 in LLaMa-7B and LLaMa-13B, respectively, demonstrating its effectiveness to produce high-quality quantized LLMs.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This research paper proposes a new mixed-precision quantization technique called APTQ (Attention-aware Post-Training Mixed-Precision Quantization) for large language models.
- APTQ aims to achieve accurate and efficient quantization by leveraging the attention mechanism in language models.
- The paper explores how to efficiently quantize large language models while preserving their performance, enabling their deployment on resource-constrained devices.
Plain English Explanation
Large language models, such as GPT-3 and BERT, have revolutionized natural language processing, but they are also computationally intensive and require significant memory and storage resources. This can make it challenging to deploy these models on devices with limited computing power, like smartphones or embedded systems.
To address this challenge, the researchers developed a new technique called APTQ (Attention-aware Post-Training Mixed-Precision Quantization). APTQ takes advantage of the attention mechanism that is central to how large language models work. The attention mechanism allows the model to focus on the most relevant parts of the input when generating output, and the researchers found that this attention information can be used to guide the quantization process.
The key idea behind APTQ is to use the attention information to selectively quantize different parts of the model to different levels of precision. For example, the researchers found that the parts of the model that are responsible for the attention mechanism don't need to be quantized as aggressively as other parts, since the attention information is crucial for maintaining the model's performance.
By using this attention-aware approach, APTQ is able to achieve higher accuracy compared to other quantization techniques, while still reducing the overall memory and computational requirements of the model. This makes it easier to deploy large language models on a wider range of devices, from powerful servers to resource-constrained edge devices.
Technical Explanation
The key technical contributions of the APTQ paper are:
-
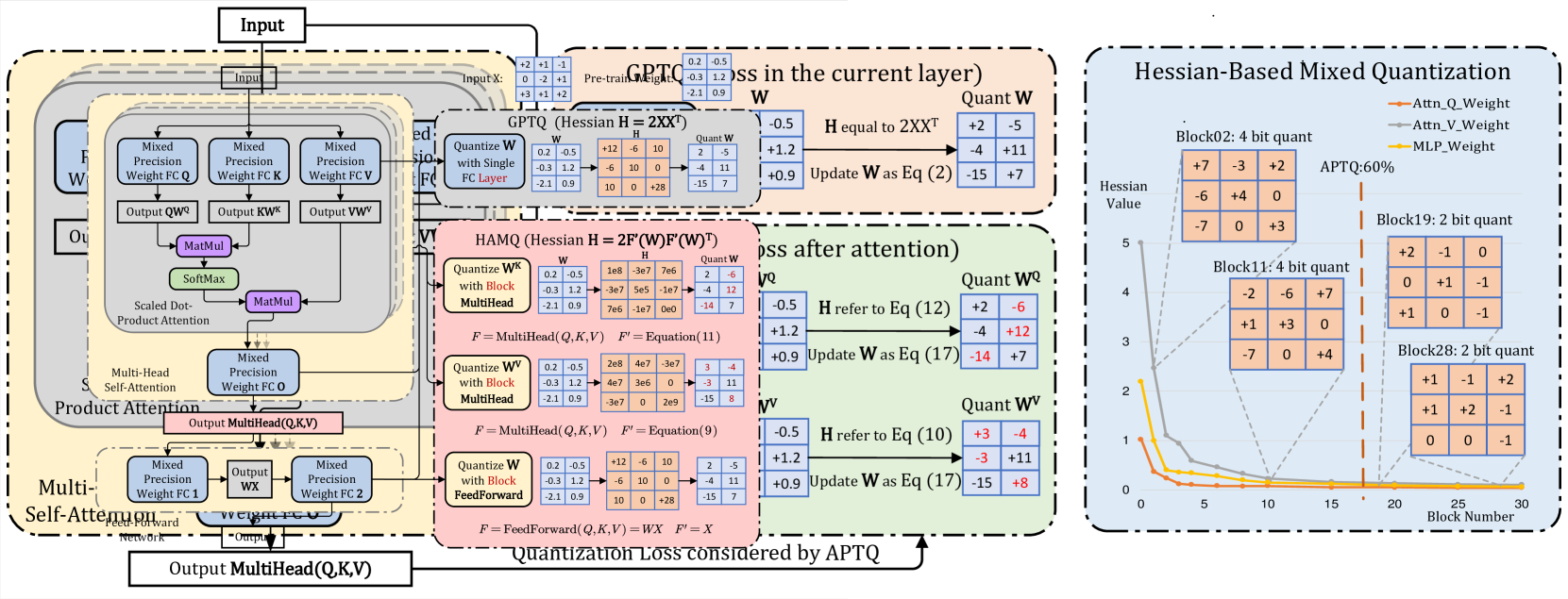
Attention-aware Quantization: The researchers propose an attention-aware quantization scheme that selectively quantizes different parts of the model to different levels of precision based on the importance of the attention information in that part of the model. This is in contrast to previous approaches that applied uniform quantization across the entire model.
-
Mixed-Precision Quantization: APTQ uses a mixed-precision quantization strategy, where some parts of the model are quantized to a lower bit-width (e.g., 4-bit) while other parts are quantized to a higher bit-width (e.g., 8-bit). This allows for a more optimal trade-off between model accuracy and model size/inference speed.
-
Hessian Matrix Sensitivity Analysis: The researchers use a Hessian matrix sensitivity analysis to determine which parts of the model are more sensitive to quantization error. This information is then used to guide the mixed-precision quantization process, ensuring that the most sensitive parts of the model are quantized to a higher precision.
-
Post-Training Quantization: APTQ is a post-training quantization technique, meaning that the quantization is performed after the model has been trained, without requiring any fine-tuning or retraining. This makes APTQ more practical and easier to apply compared to quantization techniques that require model retraining.
The researchers evaluated APTQ on several large language models, including GPT-2, BERT, and RoBERTa, and demonstrated that it can achieve significant model size reductions (up to 4x) with minimal accuracy loss, outperforming previous state-of-the-art quantization techniques.
Critical Analysis
The APTQ paper presents a well-designed and thorough quantization technique for large language models. The attention-aware and mixed-precision approach is a clever way to leverage the unique characteristics of these models to achieve efficient quantization.
One potential limitation of the research is that it was primarily evaluated on standard language modeling benchmarks, such as GLUE and SQuAD. It would be valuable to see how APTQ performs on more real-world, downstream tasks that are more representative of how these models are used in practice.
Additionally, the paper does not provide much insight into the computational overhead of the Hessian matrix sensitivity analysis used to guide the mixed-precision quantization. This step could potentially add significant complexity and runtime overhead, which could be a concern for deployment on resource-constrained devices.
Overall, the APTQ technique represents an important advancement in the field of efficient large language model deployment, and the researchers have provided a strong foundation for further research and development in this area. Future work could explore ways to further streamline the quantization process or integrate it more seamlessly into the model training pipeline.
Conclusion
The APTQ paper presents a novel attention-aware, mixed-precision quantization technique for efficiently deploying large language models on a wide range of devices, from powerful servers to resource-constrained edge devices. By leveraging the attention mechanism in these models and using a selective quantization approach, APTQ is able to achieve significant model size reductions with minimal accuracy loss, outperforming previous state-of-the-art quantization techniques.
This research represents an important step forward in making large language models more accessible and practical for real-world applications, paving the way for their widespread adoption in a diverse range of domains, from natural language processing to multimodal AI systems. As the field of efficient model deployment continues to evolve, techniques like APTQ will play a crucial role in unlocking the full potential of these powerful AI models.
Related Papers
💬
QLLM: Accurate and Efficient Low-Bitwidth Quantization for Large Language Models
Jing Liu, Ruihao Gong, Xiuying Wei, Zhiwei Dong, Jianfei Cai, Bohan Zhuang
0
0
Large Language Models (LLMs) excel in NLP, but their demands hinder their widespread deployment. While Quantization-Aware Training (QAT) offers a solution, its extensive training costs make Post-Training Quantization (PTQ) a more practical approach for LLMs. In existing studies, activation outliers in particular channels are identified as the bottleneck to PTQ accuracy. They propose to transform the magnitudes from activations to weights, which however offers limited alleviation or suffers from unstable gradients, resulting in a severe performance drop at low-bitwidth. In this paper, we propose QLLM, an accurate and efficient low-bitwidth PTQ method designed for LLMs. QLLM introduces an adaptive channel reassembly technique that reallocates the magnitude of outliers to other channels, thereby mitigating their impact on the quantization range. This is achieved by channel disassembly and channel assembly, which first breaks down the outlier channels into several sub-channels to ensure a more balanced distribution of activation magnitudes. Then similar channels are merged to maintain the original channel number for efficiency. Additionally, an adaptive strategy is designed to autonomously determine the optimal number of sub-channels for channel disassembly. To further compensate for the performance loss caused by quantization, we propose an efficient tuning method that only learns a small number of low-rank weights while freezing the pre-trained quantized model. After training, these low-rank parameters can be fused into the frozen weights without affecting inference. Extensive experiments on LLaMA-1 and LLaMA-2 show that QLLM can obtain accurate quantized models efficiently. For example, QLLM quantizes the 4-bit LLaMA-2-70B within 10 hours on a single A100-80G GPU, outperforming the previous state-of-the-art method by 7.89% on the average accuracy across five zero-shot tasks.
4/9/2024
📉
AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration
Ji Lin, Jiaming Tang, Haotian Tang, Shang Yang, Wei-Ming Chen, Wei-Chen Wang, Guangxuan Xiao, Xingyu Dang, Chuang Gan, Song Han
0
0
Large language models (LLMs) have fundamentally transformed the capabilities of numerous applications, from natural language processing to more intricate domain-specific tasks in robotics and autonomous driving. Moreover, the importance of on-device LLMs has grown significantly in the recent years. Running LLMs on edge devices not only promises reduced latency and improved user experience but also aligns with the increasing need for user privacy, as data processing can occur locally. However, the astronomical model sizes of modern LLMs and constraints of the edge devices, primarily in terms of memory size and bandwidth, pose significant deployment challenges. In this paper, we propose Activation-aware Weight Quantization (AWQ), a hardware-friendly approach for LLM low-bit weight-only quantization. Our method is based on the observation that weights are not equally important: protecting only 1% of salient weights can greatly reduce quantization error. We then propose to search for the optimal per-channel scaling that protects the salient weights by observing the activation, not weights. AWQ does not rely on any backpropagation or reconstruction, so it can well preserve LLMs' generalization ability on different domains and modalities, without overfitting to the calibration set. AWQ outperforms existing work on various language modeling and domain-specific benchmarks (coding and math). Thanks to better generalization, it achieves excellent quantization performance for instruction-tuned LMs and, for the first time, multi-modal LMs. Alongside AWQ, we implement TinyChat, an efficient and flexible inference framework tailored for on-device LLM/VLMs, offering more than 3x speedup over the Huggingface FP16 implementation on both desktop and mobile GPUs. It also democratizes the deployment of the 70B Llama-2 model on mobile GPUs.
4/23/2024
CBQ: Cross-Block Quantization for Large Language Models
Xin Ding, Xiaoyu Liu, Zhijun Tu, Yun Zhang, Wei Li, Jie Hu, Hanting Chen, Yehui Tang, Zhiwei Xiong, Baoqun Yin, Yunhe Wang
0
0
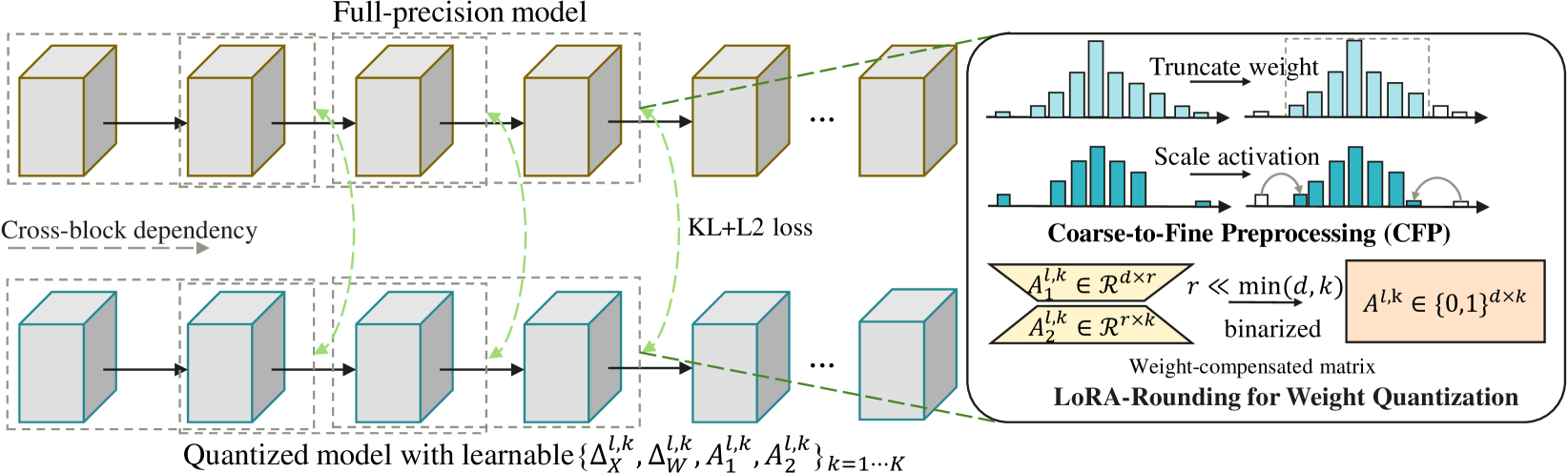
Post-training quantization (PTQ) has played a key role in compressing large language models (LLMs) with ultra-low costs. However, existing PTQ methods only focus on handling the outliers within one layer or one block, which ignores the dependency of blocks and leads to severe performance degradation in low-bit settings. In this paper, we propose CBQ, a cross-block reconstruction-based PTQ method for LLMs. CBQ employs a cross-block dependency using a homologous reconstruction scheme, establishing long-range dependencies across multiple blocks to minimize error accumulation. Furthermore, CBQ incorporates a coarse-to-fine preprocessing (CFP) strategy for suppressing weight and activation outliers, coupled with an adaptive LoRA-Rounding technique for precise weight quantization. These innovations enable CBQ to not only handle extreme outliers effectively but also improve overall quantization accuracy. Extensive experiments show that CBQ achieves superior low-bit quantization (W4A4, W4A8, W2A16) and outperforms existing state-of-the-art methods across various LLMs and datasets. Notably, CBQ quantizes the 4-bit LLAMA1-65B model within only 4.3 hours on a single GPU, achieving a commendable tradeoff between performance and quantization efficiency.
4/16/2024
Gradient-based Automatic Per-Weight Mixed Precision Quantization for Neural Networks On-Chip
Chang Sun, Thea K. {AA}rrestad, Vladimir Loncar, Jennifer Ngadiuba, Maria Spiropulu
0
0
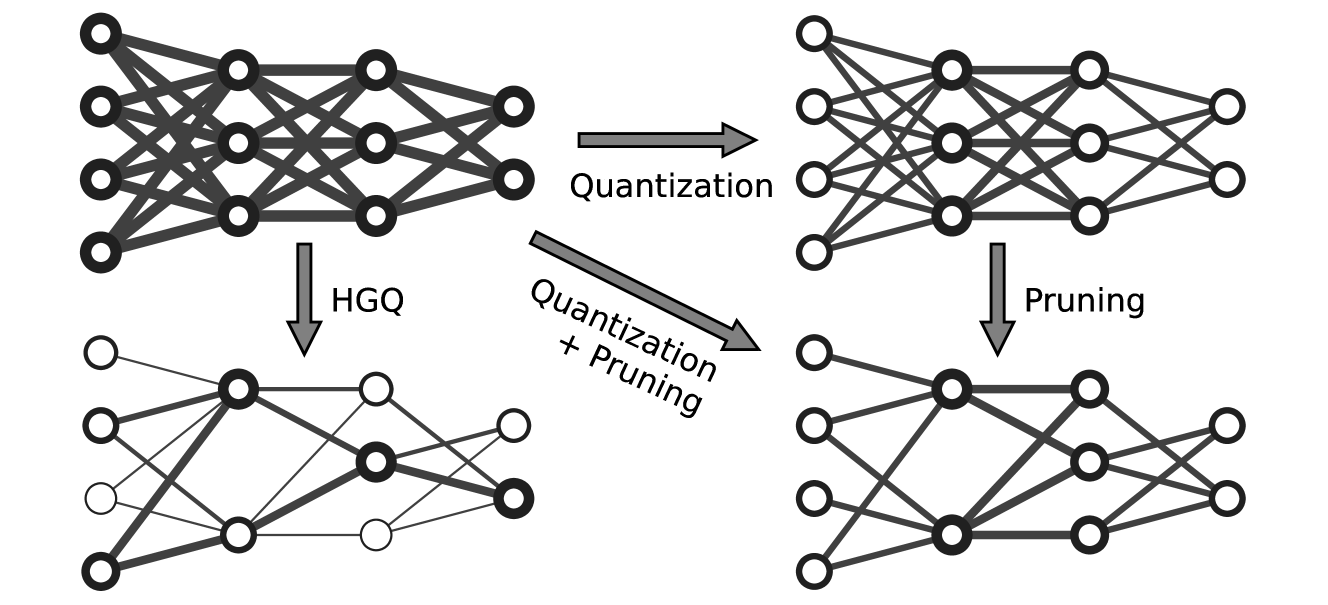
Model size and inference speed at deployment time, are major challenges in many deep learning applications. A promising strategy to overcome these challenges is quantization. However, a straightforward uniform quantization to very low precision can result in significant accuracy loss. Mixed-precision quantization, based on the idea that certain parts of the network can accommodate lower precision without compromising performance compared to other parts, offers a potential solution. In this work, we present High Granularity Quantization (HGQ), an innovative quantization-aware training method designed to fine-tune the per-weight and per-activation precision in an automatic way for ultra-low latency and low power neural networks which are to be deployed on FPGAs. We demonstrate that HGQ can outperform existing methods by a substantial margin, achieving resource reduction by up to a factor of 20 and latency improvement by a factor of 5 while preserving accuracy.
5/2/2024