Gradient-based Automatic Per-Weight Mixed Precision Quantization for Neural Networks On-Chip
2405.00645
0
0
Abstract
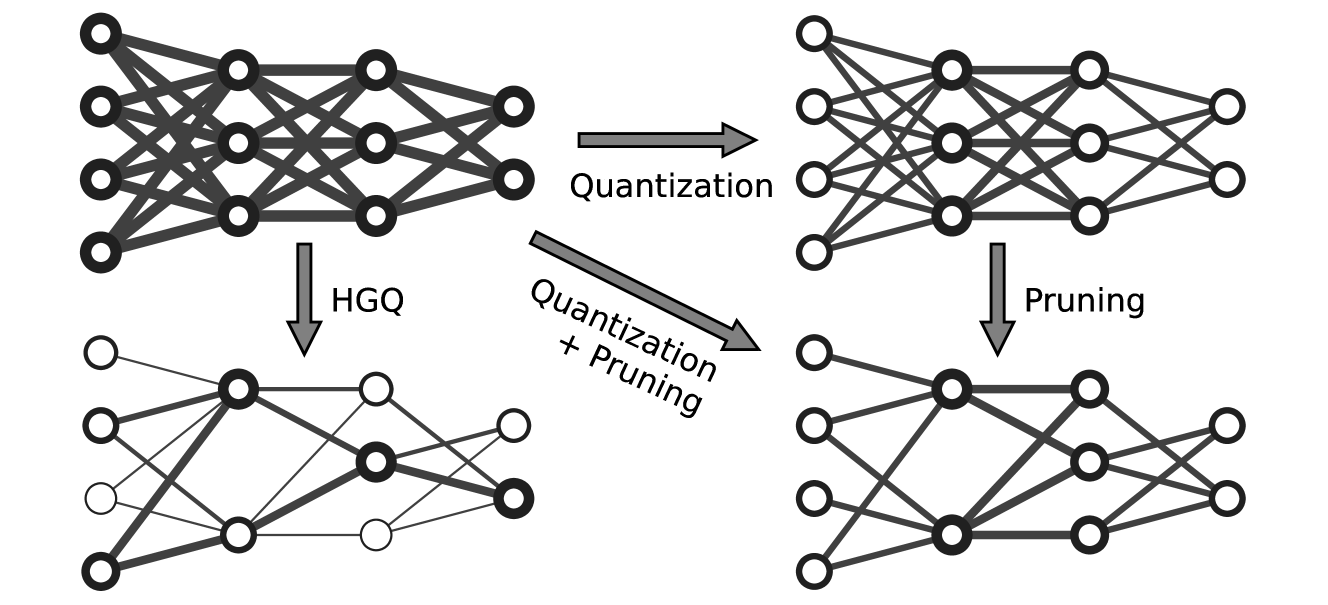
Model size and inference speed at deployment time, are major challenges in many deep learning applications. A promising strategy to overcome these challenges is quantization. However, a straightforward uniform quantization to very low precision can result in significant accuracy loss. Mixed-precision quantization, based on the idea that certain parts of the network can accommodate lower precision without compromising performance compared to other parts, offers a potential solution. In this work, we present High Granularity Quantization (HGQ), an innovative quantization-aware training method designed to fine-tune the per-weight and per-activation precision in an automatic way for ultra-low latency and low power neural networks which are to be deployed on FPGAs. We demonstrate that HGQ can outperform existing methods by a substantial margin, achieving resource reduction by up to a factor of 20 and latency improvement by a factor of 5 while preserving accuracy.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper presents a new approach for automatically determining the optimal bitwidth for each weight in a neural network, a technique known as "per-weight mixed precision quantization."
- The authors propose a gradient-based method to find the best bitwidth for each weight during training, without requiring manual tuning or architecture search.
- The technique is designed to enable efficient neural network inference on edge devices with limited computational resources.
Plain English Explanation
The main idea behind this research is to find the optimal way to represent the numbers (or "weights") inside a neural network using as few bits as possible, while still maintaining the network's accuracy. [This is similar to the techniques used in the papers <a href="https://aimodels.fyi/papers/arxiv/qgen-ability-to-generalize-quantization-aware-training">QGen</a>, <a href="https://aimodels.fyi/papers/arxiv/aptq-attention-aware-post-training-mixed-precision">APTQ</a>, <a href="https://aimodels.fyi/papers/arxiv/adaqat-adaptive-bit-width-quantization-aware-training">AdaQAT</a>, <a href="https://aimodels.fyi/papers/arxiv/qllm-accurate-efficient-low-bitwidth-quantization-large">QLLM</a>, and <a href="https://aimodels.fyi/papers/arxiv/dnn-memory-footprint-reduction-via-post-training">DNN Memory Footprint Reduction</a>.]
Typically, neural networks use 32-bit floating-point numbers to represent these weights, which can be computationally expensive, especially on devices with limited hardware resources like phones or edge devices. The authors' approach allows the network to use different precisions (i.e., number of bits) for different weights, which can significantly reduce the overall memory and computation requirements without sacrificing too much accuracy.
The key innovation is that the authors developed a way to automatically determine the optimal bitwidth for each weight during the training process, rather than having to manually tune this or search through different configurations. This makes the technique easier to apply and more broadly useful.
Technical Explanation
The paper presents a new method for "per-weight mixed precision quantization" - the process of representing each weight in a neural network using the minimum number of bits required, rather than using the same precision for all weights.
The authors propose a gradient-based approach to automatically determine the optimal bitwidth for each weight during the training process. They introduce a set of "bitwidth parameters" that are learned alongside the network weights, allowing the bitwidth to be optimized for each weight through backpropagation.
The method works by adding a regularization term to the loss function that encourages the use of lower bitwidths where possible. This allows the network to find the sweet spot between accuracy and efficiency, using high precision only where necessary.
The authors evaluate their technique on several benchmark neural network models and datasets, demonstrating significant reductions in model size and computation requirements compared to uniform precision quantization, with only minor accuracy degradation. For example, on the ImageNet dataset, they were able to achieve a 4.5x reduction in model size and 3.5x reduction in multiply-accumulate operations with less than 1% top-1 accuracy loss.
Critical Analysis
The authors provide a thorough evaluation of their method, testing it on a variety of neural network architectures and datasets. The results show that the technique is effective at finding efficient mixed-precision representations without sacrificing too much accuracy.
One potential limitation is that the method requires modifying the training process, which may add some complexity compared to post-training quantization approaches. However, the authors argue that the benefits of automated bitwidth selection outweigh this drawback.
Additionally, the paper does not explore the impact of the proposed method on various hardware platforms or real-world deployment scenarios. Further research would be needed to understand how the technique performs in practical applications with strict latency and power constraints.
Overall, this work represents an interesting contribution to the field of efficient neural network inference, and the gradient-based approach to per-weight mixed precision quantization is a promising direction for future research.
Conclusion
This paper introduces a new gradient-based method for automatically determining the optimal bitwidth for each weight in a neural network during training. The technique, called "automatic per-weight mixed precision quantization," allows neural networks to use lower-precision representations where possible, leading to significant reductions in model size and computational requirements without major accuracy loss.
The authors demonstrate the effectiveness of their approach on several benchmark tasks, showing that it outperforms uniform precision quantization methods. While there are still some open questions around practical deployment, this work represents an important step towards enabling efficient and high-performing neural networks on resource-constrained edge devices.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
SySMOL: Co-designing Algorithms and Hardware for Neural Networks with Heterogeneous Precisions
Cyrus Zhou, Pedro Savarese, Vaughn Richard, Zack Hassman, Xin Yuan, Michael Maire, Michael DiBrino, Yanjing Li
0
0
Recent quantization techniques have enabled heterogeneous precisions at very fine granularity, e.g., each parameter/activation can take on a different precision, resulting in compact neural networks without sacrificing accuracy. However, there is a lack of efficient architectural support for such networks, which require additional hardware to decode the precision settings for individual variables, align the variables, and provide fine-grained mixed-precision compute capabilities. The complexity of these operations introduces high overheads. Thus, the improvements in inference latency/energy of these networks are not commensurate with the compression ratio, and may be inferior to larger quantized networks with uniform precisions. We present an end-to-end co-design approach encompassing computer architecture, training algorithm, and inference optimization to efficiently execute networks with fine-grained heterogeneous precisions. The key to our approach is a novel training algorithm designed to accommodate hardware constraints and inference operation requirements, outputting networks with input-channel-wise heterogeneous precisions and at most three precision levels. Combined with inference optimization techniques, existing architectures with low-cost enhancements can support such networks efficiently, yielding optimized tradeoffs between accuracy, compression ratio and inference latency/energy. We demonstrate the efficacy of our approach across CPU and GPU architectures. For various representative neural networks, our approach achieves >10x improvements in both compression ratio and inference latency, with negligible degradation in accuracy compared to full-precision networks.
5/8/2024
QGen: On the Ability to Generalize in Quantization Aware Training
MohammadHossein AskariHemmat, Ahmadreza Jeddi, Reyhane Askari Hemmat, Ivan Lazarevich, Alexander Hoffman, Sudhakar Sah, Ehsan Saboori, Yvon Savaria, Jean-Pierre David
0
0
Quantization lowers memory usage, computational requirements, and latency by utilizing fewer bits to represent model weights and activations. In this work, we investigate the generalization properties of quantized neural networks, a characteristic that has received little attention despite its implications on model performance. In particular, first, we develop a theoretical model for quantization in neural networks and demonstrate how quantization functions as a form of regularization. Second, motivated by recent work connecting the sharpness of the loss landscape and generalization, we derive an approximate bound for the generalization of quantized models conditioned on the amount of quantization noise. We then validate our hypothesis by experimenting with over 2000 models trained on CIFAR-10, CIFAR-100, and ImageNet datasets on convolutional and transformer-based models.
4/22/2024
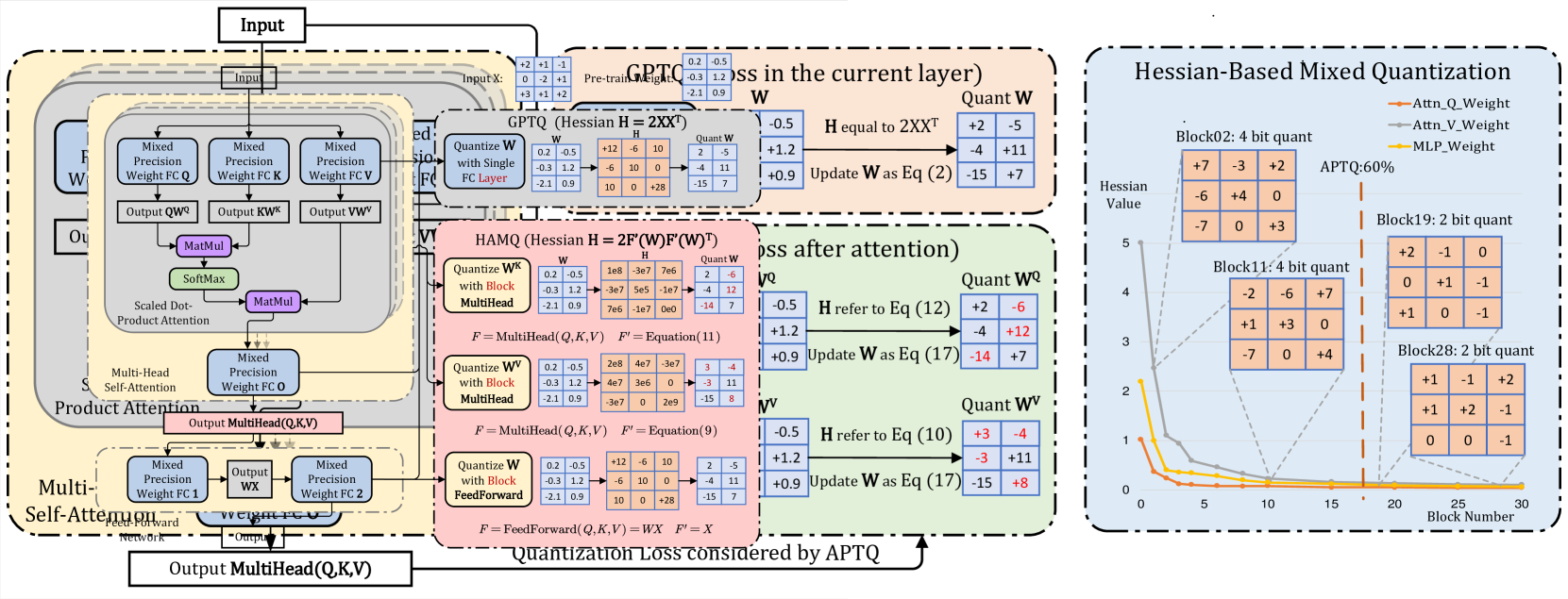
APTQ: Attention-aware Post-Training Mixed-Precision Quantization for Large Language Models
Ziyi Guan, Hantao Huang, Yupeng Su, Hong Huang, Ngai Wong, Hao Yu
0
0
Large Language Models (LLMs) have greatly advanced the natural language processing paradigm. However, the high computational load and huge model sizes pose a grand challenge for deployment on edge devices. To this end, we propose APTQ (Attention-aware Post-Training Mixed-Precision Quantization) for LLMs, which considers not only the second-order information of each layer's weights, but also, for the first time, the nonlinear effect of attention outputs on the entire model. We leverage the Hessian trace as a sensitivity metric for mixed-precision quantization, ensuring an informed precision reduction that retains model performance. Experiments show APTQ surpasses previous quantization methods, achieving an average of 4 bit width a 5.22 perplexity nearly equivalent to full precision in the C4 dataset. In addition, APTQ attains state-of-the-art zero-shot accuracy of 68.24% and 70.48% at an average bitwidth of 3.8 in LLaMa-7B and LLaMa-13B, respectively, demonstrating its effectiveness to produce high-quality quantized LLMs.
4/17/2024
🏋️
AdaQAT: Adaptive Bit-Width Quantization-Aware Training
C'edric Gernigon (TARAN), Silviu-Ioan Filip (TARAN), Olivier Sentieys (TARAN), Cl'ement Coggiola (CNES), Mickael Bruno (CNES)
0
0
Large-scale deep neural networks (DNNs) have achieved remarkable success in many application scenarios. However, high computational complexity and energy costs of modern DNNs make their deployment on edge devices challenging. Model quantization is a common approach to deal with deployment constraints, but searching for optimized bit-widths can be challenging. In this work, we present Adaptive Bit-Width Quantization Aware Training (AdaQAT), a learning-based method that automatically optimizes weight and activation signal bit-widths during training for more efficient DNN inference. We use relaxed real-valued bit-widths that are updated using a gradient descent rule, but are otherwise discretized for all quantization operations. The result is a simple and flexible QAT approach for mixed-precision uniform quantization problems. Compared to other methods that are generally designed to be run on a pretrained network, AdaQAT works well in both training from scratch and fine-tuning scenarios.Initial results on the CIFAR-10 and ImageNet datasets using ResNet20 and ResNet18 models, respectively, indicate that our method is competitive with other state-of-the-art mixed-precision quantization approaches.
4/29/2024