Are Large Language Models True Healthcare Jacks-of-All-Trades? Benchmarking Across Health Professions Beyond Physician Exams
2406.11328
0
0

Abstract
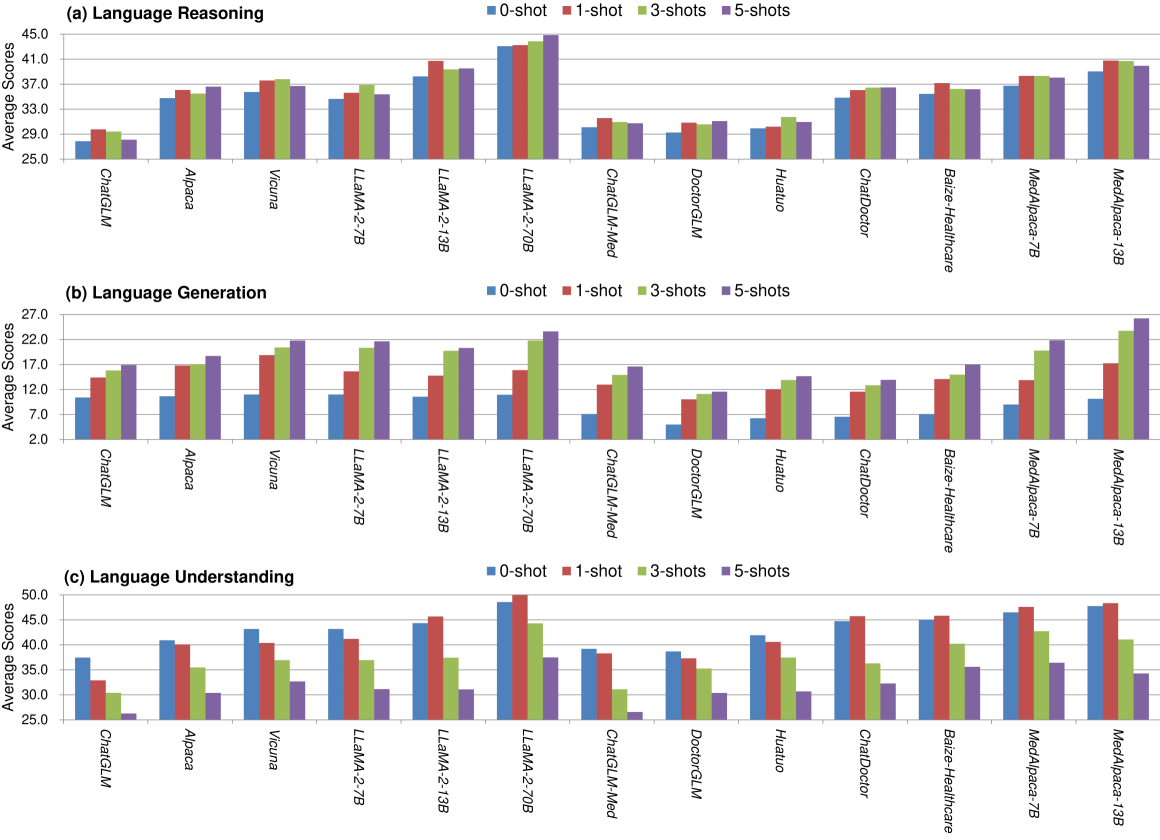
Recent advancements in Large Language Models (LLMs) have demonstrated their potential in delivering accurate answers to questions about world knowledge. Despite this, existing benchmarks for evaluating LLMs in healthcare predominantly focus on medical doctors, leaving other critical healthcare professions underrepresented. To fill this research gap, we introduce the Examinations for Medical Personnel in Chinese (EMPEC), a pioneering large-scale healthcare knowledge benchmark in traditional Chinese. EMPEC consists of 157,803 exam questions across 124 subjects and 20 healthcare professions, including underrepresented occupations like Optometrists and Audiologists. Each question is tagged with its release time and source, ensuring relevance and authenticity. We conducted extensive experiments on 17 LLMs, including proprietary, open-source models, general domain models and medical specific models, evaluating their performance under various settings. Our findings reveal that while leading models like GPT-4 achieve over 75% accuracy, they still struggle with specialized fields and alternative medicine. Surprisingly, general-purpose LLMs outperformed medical-specific models, and incorporating EMPEC's training data significantly enhanced performance. Additionally, the results on questions released after the models' training cutoff date were consistent with overall performance trends, suggesting that the models' performance on the test set can predict their effectiveness in addressing unseen healthcare-related queries. The transition from traditional to simplified Chinese characters had a negligible impact on model performance, indicating robust linguistic versatility. Our study underscores the importance of expanding benchmarks to cover a broader range of healthcare professions to better assess the applicability of LLMs in real-world healthcare scenarios.
Create account to get full access
Overview
- This paper examines the capabilities of large language models (LLMs) beyond just physician exams, exploring their potential as "healthcare jacks-of-all-trades" across a range of health professions.
- The researchers developed a comprehensive benchmark to assess LLM performance on tasks spanning nursing, pharmacy, physical therapy, and other healthcare domains, going beyond the typical focus on medical knowledge tests.
- The results provide insights into the strengths and limitations of LLMs in healthcare applications, informing the ongoing discussions around their role in transforming the industry.
Plain English Explanation
The paper investigates whether large language models (LLMs) - powerful AI systems that can understand and generate human-like text - can be true "jacks-of-all-trades" in healthcare, excelling not just in medical knowledge tests but across a wide range of health-related tasks and professions.
Existing benchmarks for evaluating LLMs in healthcare have typically focused on their performance on exams for doctors and medical students. However, the healthcare industry involves many different roles and responsibilities beyond just practicing medicine, such as nursing, pharmacy, physical therapy, and more. The researchers wanted to see how well LLMs could handle tasks and challenges specific to these other health professions.
To do this, they developed a comprehensive benchmark that assessed LLM capabilities across a diverse set of healthcare-related skills and knowledge areas. This allowed them to get a more holistic understanding of how these AI systems might perform in real-world healthcare settings, beyond just academic medical exams.
The results provide insight into the strengths and limitations of LLMs when it comes to healthcare applications. While the models showed impressive capabilities in some areas, there were also clear gaps in their knowledge and abilities compared to human experts. This information can help guide the ongoing discussions and decisions around how these powerful AI tools should be deployed and integrated within the healthcare industry.
Technical Explanation
The researchers created a comprehensive benchmark to evaluate large language models (LLMs) on a wide range of healthcare-related tasks, going beyond the typical focus on physician exams. Drawing inspiration from prior work on surveying LLM capabilities in healthcare and general-purpose LLM benchmarking, the benchmark included assessments across nursing, pharmacy, physical therapy, and other health professions.
The benchmark tasks were designed to be authentic and representative of real-world healthcare challenges, rather than just academic tests. This stands in contrast to existing medical language model benchmarks that have been limited in scope.
The researchers evaluated several prominent LLM architectures on this comprehensive healthcare benchmark, analyzing their performance and capabilities across the diverse set of tasks and domains. This provided a more holistic understanding of LLM strengths and weaknesses in healthcare applications, beyond just their medical knowledge.
Critical Analysis
The paper's comprehensive approach to benchmarking LLMs across healthcare professions is a valuable contribution, as it addresses the limitations of prior research that focused narrowly on physician exams. By including a wider range of tasks and domains, the researchers were able to uncover interesting insights about the models' capabilities and limitations.
However, as noted in the paper, the benchmark tasks were still somewhat artificial and may not fully capture the complexities of real-world healthcare settings. There is an opportunity for further research to develop even more authentic and challenging evaluations that better reflect the realities of clinical practice, patient interactions, and multi-disciplinary collaboration.
Additionally, the paper acknowledges that the benchmark primarily assessed language understanding and generation abilities, while other critical healthcare competencies like clinical reasoning, empathy, and ethical decision-making were not directly evaluated. Exploring these higher-level cognitive and social skills will be an important area for future research on the role of LLMs in healthcare.
Conclusion
This study provides a comprehensive evaluation of large language models' capabilities across a wide range of healthcare professions, going beyond the typical focus on physician exams. The results offer valuable insights into the strengths and limitations of these powerful AI systems when it comes to healthcare applications.
While the LLMs demonstrated impressive performance on many tasks, the findings also highlight significant gaps in their knowledge and abilities compared to human experts. This underscores the need for continued research and careful consideration of how these technologies should be developed and deployed within the complex and high-stakes domain of healthcare.
As the use of large language models in healthcare continues to evolve, this study's holistic approach to benchmarking can inform the ongoing discussions and decisions around the role of AI in transforming the industry. By better understanding the current capabilities and limitations of these models, healthcare stakeholders can work towards leveraging their strengths while addressing their weaknesses to ultimately improve patient outcomes and experiences.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Large Language Models in Healthcare: A Comprehensive Benchmark
Andrew Liu, Hongjian Zhou, Yining Hua, Omid Rohanian, Anshul Thakur, Lei Clifton, David A. Clifton
0
0
The adoption of large language models (LLMs) to assist clinicians has attracted remarkable attention. Existing works mainly adopt the close-ended question-answering (QA) task with answer options for evaluation. However, many clinical decisions involve answering open-ended questions without pre-set options. To better understand LLMs in the clinic, we construct a benchmark ClinicBench. We first collect eleven existing datasets covering diverse clinical language generation, understanding, and reasoning tasks. Furthermore, we construct six novel datasets and complex clinical tasks that are close to real-world practice, i.e., referral QA, treatment recommendation, hospitalization (long document) summarization, patient education, pharmacology QA and drug interaction for emerging drugs. We conduct an extensive evaluation of twenty-two LLMs under both zero-shot and few-shot settings. Finally, we invite medical experts to evaluate the clinical usefulness of LLMs.
6/27/2024
💬
A Survey of Large Language Models for Healthcare: from Data, Technology, and Applications to Accountability and Ethics
Kai He, Rui Mao, Qika Lin, Yucheng Ruan, Xiang Lan, Mengling Feng, Erik Cambria
0
0
The utilization of large language models (LLMs) in the Healthcare domain has generated both excitement and concern due to their ability to effectively respond to freetext queries with certain professional knowledge. This survey outlines the capabilities of the currently developed LLMs for Healthcare and explicates their development process, with the aim of providing an overview of the development roadmap from traditional Pretrained Language Models (PLMs) to LLMs. Specifically, we first explore the potential of LLMs to enhance the efficiency and effectiveness of various Healthcare applications highlighting both the strengths and limitations. Secondly, we conduct a comparison between the previous PLMs and the latest LLMs, as well as comparing various LLMs with each other. Then we summarize related Healthcare training data, training methods, optimization strategies, and usage. Finally, the unique concerns associated with deploying LLMs in Healthcare settings are investigated, particularly regarding fairness, accountability, transparency and ethics. Our survey provide a comprehensive investigation from perspectives of both computer science and Healthcare specialty. Besides the discussion about Healthcare concerns, we supports the computer science community by compiling a collection of open source resources, such as accessible datasets, the latest methodologies, code implementations, and evaluation benchmarks in the Github. Summarily, we contend that a significant paradigm shift is underway, transitioning from PLMs to LLMs. This shift encompasses a move from discriminative AI approaches to generative AI approaches, as well as a shift from model-centered methodologies to data-centered methodologies. Also, we determine that the biggest obstacle of using LLMs in Healthcare are fairness, accountability, transparency and ethics.
6/12/2024

A Survey on Large Language Models from General Purpose to Medical Applications: Datasets, Methodologies, and Evaluations
Jinqiang Wang, Huansheng Ning, Yi Peng, Qikai Wei, Daniel Tesfai, Wenwei Mao, Tao Zhu, Runhe Huang
0
0
Large Language Models (LLMs) have demonstrated surprising performance across various natural language processing tasks. Recently, medical LLMs enhanced with domain-specific knowledge have exhibited excellent capabilities in medical consultation and diagnosis. These models can smoothly simulate doctor-patient dialogues and provide professional medical advice. Most medical LLMs are developed through continued training of open-source general LLMs, which require significantly fewer computational resources than training LLMs from scratch. Additionally, this approach offers better protection of patient privacy compared to API-based solutions. This survey systematically explores how to train medical LLMs based on general LLMs. It covers: (a) how to acquire training corpus and construct customized medical training sets, (b) how to choose a appropriate training paradigm, (c) how to choose a suitable evaluation benchmark, and (d) existing challenges and promising future research directions are discussed. This survey can provide guidance for the development of LLMs focused on various medical applications, such as medical education, diagnostic planning, and clinical assistants.
6/18/2024
MedExpQA: Multilingual Benchmarking of Large Language Models for Medical Question Answering
I~nigo Alonso, Maite Oronoz, Rodrigo Agerri
0
0
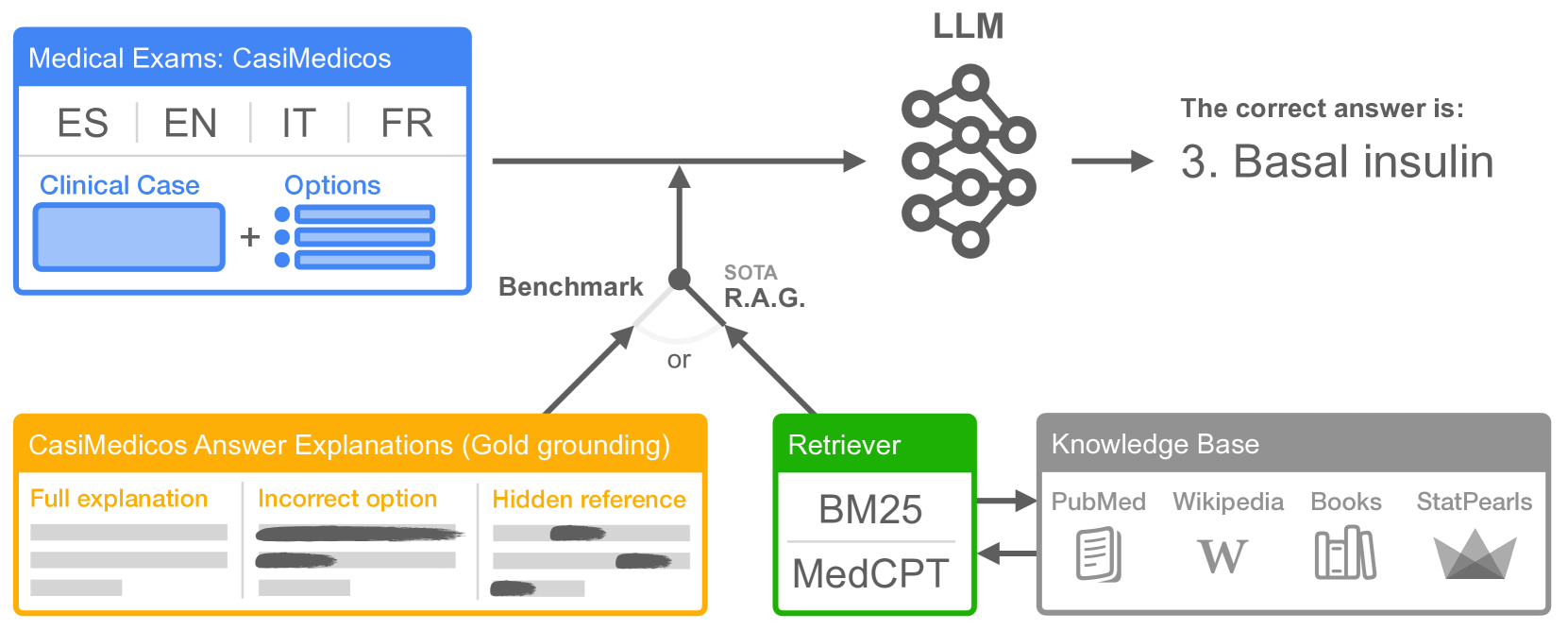
Large Language Models (LLMs) have the potential of facilitating the development of Artificial Intelligence technology to assist medical experts for interactive decision support, which has been demonstrated by their competitive performances in Medical QA. However, while impressive, the required quality bar for medical applications remains far from being achieved. Currently, LLMs remain challenged by outdated knowledge and by their tendency to generate hallucinated content. Furthermore, most benchmarks to assess medical knowledge lack reference gold explanations which means that it is not possible to evaluate the reasoning of LLMs predictions. Finally, the situation is particularly grim if we consider benchmarking LLMs for languages other than English which remains, as far as we know, a totally neglected topic. In order to address these shortcomings, in this paper we present MedExpQA, the first multilingual benchmark based on medical exams to evaluate LLMs in Medical Question Answering. To the best of our knowledge, MedExpQA includes for the first time reference gold explanations written by medical doctors which can be leveraged to establish various gold-based upper-bounds for comparison with LLMs performance. Comprehensive multilingual experimentation using both the gold reference explanations and Retrieval Augmented Generation (RAG) approaches show that performance of LLMs still has large room for improvement, especially for languages other than English. Furthermore, and despite using state-of-the-art RAG methods, our results also demonstrate the difficulty of obtaining and integrating readily available medical knowledge that may positively impact results on downstream evaluations for Medical Question Answering. So far the benchmark is available in four languages, but we hope that this work may encourage further development to other languages.
4/9/2024