Large Language Models in Healthcare: A Comprehensive Benchmark
2405.00716
0
0
Abstract
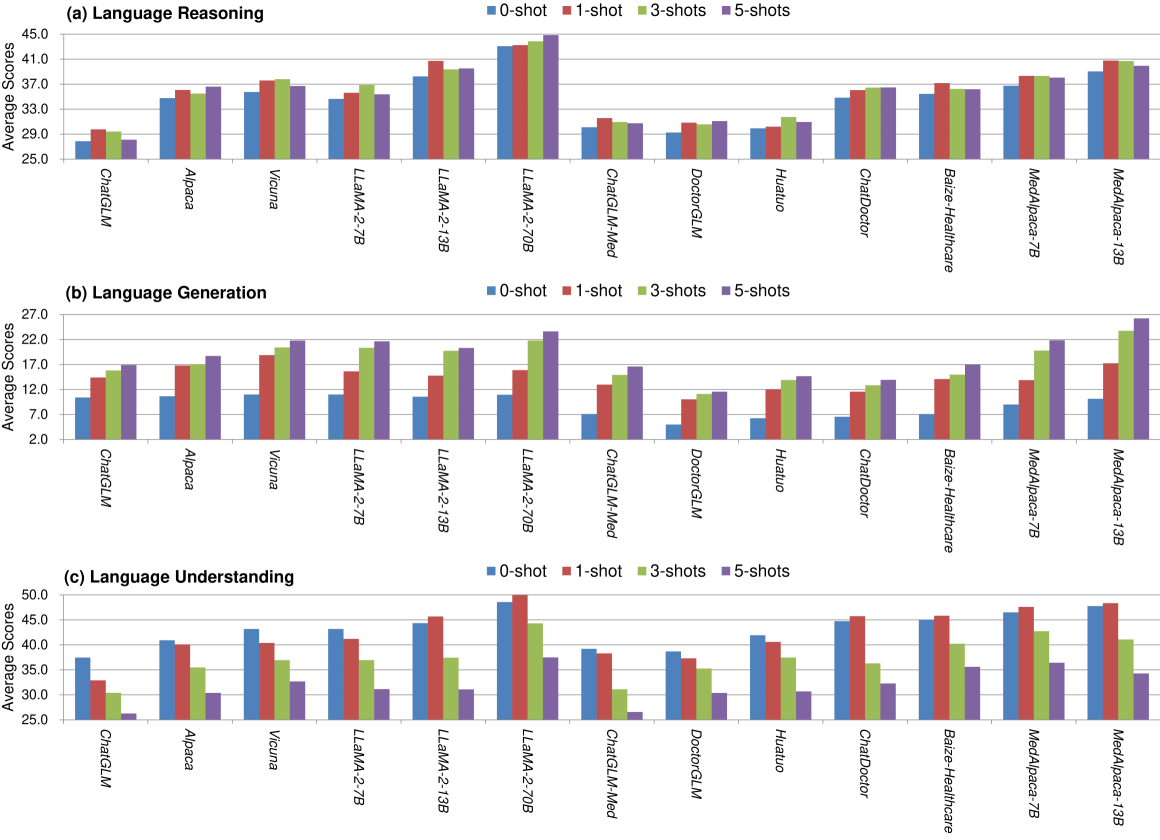
The adoption of large language models (LLMs) to assist clinicians has attracted remarkable attention. Existing works mainly adopt the close-ended question-answering (QA) task with answer options for evaluation. However, many clinical decisions involve answering open-ended questions without pre-set options. To better understand LLMs in the clinic, we construct a benchmark ClinicBench. We first collect eleven existing datasets covering diverse clinical language generation, understanding, and reasoning tasks. Furthermore, we construct six novel datasets and complex clinical tasks that are close to real-world practice, i.e., referral QA, treatment recommendation, hospitalization (long document) summarization, patient education, pharmacology QA and drug interaction for emerging drugs. We conduct an extensive evaluation of twenty-two LLMs under both zero-shot and few-shot settings. Finally, we invite medical experts to evaluate the clinical usefulness of LLMs.
Create account to get full access
Overview
- This paper presents a comprehensive benchmark for evaluating the performance of large language models (LLMs) in healthcare applications.
- The benchmark covers a wide range of tasks, including medical question answering, clinical language understanding, and bias patterns in clinical decision support.
- The researchers also explore zero-shot and few-shot learning capabilities of LLMs, as well as the performance of adapted LLMs compared to domain-specific models.
Plain English Explanation
The paper looks at how well large language models, which are powerful AI systems that can understand and generate human-like text, perform on a variety of healthcare-related tasks. These tasks include answering medical questions, understanding clinical language, and identifying potential biases in how these models could be used to support clinical decision-making.
The researchers create a broad set of benchmarks, or standardized tests, to evaluate the capabilities of these language models. They examine how well the models can learn new tasks without any prior training (zero-shot learning) or with only a small amount of training data (few-shot learning). They also investigate whether language models that have been specifically adapted for healthcare applications can outperform more general-purpose models.
By evaluating the strengths and weaknesses of these language models across a range of healthcare-related tasks, the researchers aim to provide a comprehensive understanding of how well these powerful AI systems can be applied in the medical field. This can help guide the development and deployment of these technologies to ensure they are safe, effective, and beneficial for both healthcare providers and patients.
Technical Explanation
The paper proposes a comprehensive benchmark for evaluating the performance of large language models (LLMs) in healthcare applications. The benchmark covers a diverse set of tasks, including medical question answering, clinical language understanding, and bias patterns in clinical decision support.
To assess the capabilities of LLMs, the researchers investigate their zero-shot and few-shot learning abilities, as well as the performance of adapted LLMs compared to domain-specific models. The zero-shot and few-shot experiments evaluate how well LLMs can perform on new tasks without or with limited training data, respectively. The adapted LLM experiments assess whether models fine-tuned on healthcare data can outperform more general-purpose LLMs.
The researchers collect a diverse set of datasets and design standardized evaluation protocols to ensure a comprehensive assessment of LLM capabilities in the healthcare domain. The benchmark covers a wide range of tasks, from factual question answering to clinical language understanding and bias detection, providing a thorough evaluation of the potential and limitations of these models in healthcare applications.
Critical Analysis
The paper provides a comprehensive and rigorous evaluation of LLM performance in healthcare, addressing several important limitations and potential issues with the use of these models in medical applications.
One key limitation discussed is the potential for LLMs to exhibit biases, which could lead to unfair or potentially harmful decisions in clinical settings. The researchers' analysis of bias patterns in clinical decision support is an important step in understanding and mitigating these biases.
Additionally, the paper highlights the importance of adapted LLMs and the need for further research to improve the performance of these models in specialized healthcare domains. While the results suggest that adapted LLMs can outperform general-purpose models, there is still room for improvement in terms of accuracy and robustness.
The researchers also acknowledge the limitations of their zero-shot and few-shot learning experiments, noting that these capabilities may be task-dependent and require further investigation.
Overall, the paper presents a comprehensive and thoughtful analysis of LLM performance in healthcare, highlighting both the potential benefits and the important challenges that must be addressed before these models can be safely and effectively deployed in medical settings.
Conclusion
This paper provides a comprehensive benchmark for evaluating the performance of large language models (LLMs) in healthcare applications. The researchers assess a wide range of tasks, including medical question answering, clinical language understanding, and bias patterns in clinical decision support. They also explore the zero-shot and few-shot learning capabilities of LLMs, as well as the performance of adapted LLMs compared to domain-specific models.
The findings of this study offer valuable insights into the strengths and limitations of LLMs in the healthcare domain. The benchmarks developed can serve as a valuable resource for researchers and developers working to improve the application of these powerful AI systems in medical settings. By addressing important challenges such as bias, task-specific performance, and the need for adaptation, this work lays the groundwork for the safe and effective deployment of LLMs in healthcare, ultimately benefiting both healthcare providers and patients.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
A Survey of Large Language Models for Healthcare: from Data, Technology, and Applications to Accountability and Ethics
Kai He, Rui Mao, Qika Lin, Yucheng Ruan, Xiang Lan, Mengling Feng, Erik Cambria
0
0
The utilization of large language models (LLMs) in the Healthcare domain has generated both excitement and concern due to their ability to effectively respond to freetext queries with certain professional knowledge. This survey outlines the capabilities of the currently developed LLMs for Healthcare and explicates their development process, with the aim of providing an overview of the development roadmap from traditional Pretrained Language Models (PLMs) to LLMs. Specifically, we first explore the potential of LLMs to enhance the efficiency and effectiveness of various Healthcare applications highlighting both the strengths and limitations. Secondly, we conduct a comparison between the previous PLMs and the latest LLMs, as well as comparing various LLMs with each other. Then we summarize related Healthcare training data, training methods, optimization strategies, and usage. Finally, the unique concerns associated with deploying LLMs in Healthcare settings are investigated, particularly regarding fairness, accountability, transparency and ethics. Our survey provide a comprehensive investigation from perspectives of both computer science and Healthcare specialty. Besides the discussion about Healthcare concerns, we supports the computer science community by compiling a collection of open source resources, such as accessible datasets, the latest methodologies, code implementations, and evaluation benchmarks in the Github. Summarily, we contend that a significant paradigm shift is underway, transitioning from PLMs to LLMs. This shift encompasses a move from discriminative AI approaches to generative AI approaches, as well as a shift from model-centered methodologies to data-centered methodologies. Also, we determine that the biggest obstacle of using LLMs in Healthcare are fairness, accountability, transparency and ethics.
6/12/2024
💬
Evaluating large language models in medical applications: a survey
Xiaolan Chen, Jiayang Xiang, Shanfu Lu, Yexin Liu, Mingguang He, Danli Shi
0
0
Large language models (LLMs) have emerged as powerful tools with transformative potential across numerous domains, including healthcare and medicine. In the medical domain, LLMs hold promise for tasks ranging from clinical decision support to patient education. However, evaluating the performance of LLMs in medical contexts presents unique challenges due to the complex and critical nature of medical information. This paper provides a comprehensive overview of the landscape of medical LLM evaluation, synthesizing insights from existing studies and highlighting evaluation data sources, task scenarios, and evaluation methods. Additionally, it identifies key challenges and opportunities in medical LLM evaluation, emphasizing the need for continued research and innovation to ensure the responsible integration of LLMs into clinical practice.
5/14/2024

A Survey on Large Language Models from General Purpose to Medical Applications: Datasets, Methodologies, and Evaluations
Jinqiang Wang, Huansheng Ning, Yi Peng, Qikai Wei, Daniel Tesfai, Wenwei Mao, Tao Zhu, Runhe Huang
0
0
Large Language Models (LLMs) have demonstrated surprising performance across various natural language processing tasks. Recently, medical LLMs enhanced with domain-specific knowledge have exhibited excellent capabilities in medical consultation and diagnosis. These models can smoothly simulate doctor-patient dialogues and provide professional medical advice. Most medical LLMs are developed through continued training of open-source general LLMs, which require significantly fewer computational resources than training LLMs from scratch. Additionally, this approach offers better protection of patient privacy compared to API-based solutions. This survey systematically explores how to train medical LLMs based on general LLMs. It covers: (a) how to acquire training corpus and construct customized medical training sets, (b) how to choose a appropriate training paradigm, (c) how to choose a suitable evaluation benchmark, and (d) existing challenges and promising future research directions are discussed. This survey can provide guidance for the development of LLMs focused on various medical applications, such as medical education, diagnostic planning, and clinical assistants.
6/18/2024

Are Large Language Models True Healthcare Jacks-of-All-Trades? Benchmarking Across Health Professions Beyond Physician Exams
Zheheng Luo, Chenhan Yuan, Qianqian Xie, Sophia Ananiadou
0
0
Recent advancements in Large Language Models (LLMs) have demonstrated their potential in delivering accurate answers to questions about world knowledge. Despite this, existing benchmarks for evaluating LLMs in healthcare predominantly focus on medical doctors, leaving other critical healthcare professions underrepresented. To fill this research gap, we introduce the Examinations for Medical Personnel in Chinese (EMPEC), a pioneering large-scale healthcare knowledge benchmark in traditional Chinese. EMPEC consists of 157,803 exam questions across 124 subjects and 20 healthcare professions, including underrepresented occupations like Optometrists and Audiologists. Each question is tagged with its release time and source, ensuring relevance and authenticity. We conducted extensive experiments on 17 LLMs, including proprietary, open-source models, general domain models and medical specific models, evaluating their performance under various settings. Our findings reveal that while leading models like GPT-4 achieve over 75% accuracy, they still struggle with specialized fields and alternative medicine. Surprisingly, general-purpose LLMs outperformed medical-specific models, and incorporating EMPEC's training data significantly enhanced performance. Additionally, the results on questions released after the models' training cutoff date were consistent with overall performance trends, suggesting that the models' performance on the test set can predict their effectiveness in addressing unseen healthcare-related queries. The transition from traditional to simplified Chinese characters had a negligible impact on model performance, indicating robust linguistic versatility. Our study underscores the importance of expanding benchmarks to cover a broader range of healthcare professions to better assess the applicability of LLMs in real-world healthcare scenarios.
6/18/2024