ASR Benchmarking: Need for a More Representative Conversational Dataset

0
Sign in to get full access
Overview
- This paper discusses the need for a more representative conversational dataset to benchmark automatic speech recognition (ASR) systems.
- Current ASR benchmarks often use read speech or scripted dialogues, which may not accurately reflect the challenges of real-world conversational speech.
- The authors argue that a diverse, representative dataset of spontaneous conversations is needed to better evaluate ASR performance and identify biases.
Plain English Explanation
The paper highlights an important issue with how automatic speech recognition (ASR) systems are typically evaluated and benchmarked. ASR benchmarking: need for a more representative conversational dataset
Most ASR benchmarks today use speech data that is read from a script or involves scripted dialogues. This type of data does not accurately reflect the challenges of real-world conversational speech, which can be more spontaneous, contain disfluencies, and have background noise. As a result, the performance of ASR systems on these benchmark tests may not translate to real-world use cases.
The authors argue that a more diverse and representative dataset of natural, spontaneous conversations is needed to properly evaluate ASR systems. This would help identify biases and limitations in the technology, and push development towards systems that can handle the complexities of everyday speech. By focusing on realistic conversational data, ASR benchmarks can become more meaningful and drive progress in the field.
Technical Explanation
The paper makes the case for the need to develop a more representative conversational dataset for benchmarking automatic speech recognition (ASR) systems. ASR benchmarking: need for a more representative conversational dataset
Current ASR benchmarks typically use datasets comprised of read speech or scripted dialogues, which do not capture the nuances and challenges of real-world conversational speech. Conversational speech can be more spontaneous, contain disfluencies, and have background noise, all of which can significantly impact ASR performance.
The authors argue that evaluating ASR systems on datasets that lack these realistic conversational characteristics can lead to inflated performance metrics that do not translate to practical deployments. A more diverse and representative dataset of natural conversations is needed to properly assess the capabilities and limitations of ASR technology, as well as identify potential biases.
The paper discusses the key attributes that a conversational dataset should possess, including:
- Spontaneity: Capturing natural, unscripted speech rather than read or scripted dialogues
- Diversity: Representing a wide range of speakers, accents, backgrounds, and conversation contexts
- Disfluencies: Incorporating common speech phenomena like hesitations, false starts, and interruptions
- Background noise: Accounting for real-world acoustic environments with ambient noise, music, and overlapping speech
By developing such a comprehensive conversational dataset, the authors believe the research community can establish more meaningful ASR benchmarks that drive the technology towards practical, real-world performance. This would enable better identification of biases, failures, and areas for improvement in current ASR systems.
Critical Analysis
The paper raises a valid and important concern about the limitations of current ASR benchmarking practices. ASR benchmarking: need for a more representative conversational dataset The authors make a compelling argument that evaluating ASR systems on read speech or scripted dialogues does not adequately reflect the challenges of real-world conversational speech.
One potential criticism is that creating a large, diverse, and representative conversational dataset may be a significant technical and logistical challenge. Collecting, transcribing, and curating such data at scale could require substantial resources and effort. The paper does not provide a detailed roadmap for how such a dataset could be developed and made accessible to the research community.
Additionally, the paper does not address the potential privacy and ethical concerns around collecting and using real-world conversational data, which may contain sensitive personal information. Careful consideration would be needed to ensure the dataset is properly anonymized and respects the privacy of the participants.
Despite these potential limitations, the core premise of the paper - that ASR benchmarking needs to evolve to better reflect real-world conversational scenarios - is a valuable and necessary contribution to the field. Pushing the research community to develop more representative datasets and benchmarks can help drive progress towards ASR systems that are truly capable of handling the complexities of natural human speech.
Conclusion
This paper highlights the need for a more representative conversational dataset to properly benchmark and evaluate automatic speech recognition (ASR) systems. ASR benchmarking: need for a more representative conversational dataset
The authors argue that current ASR benchmarks, which often use read speech or scripted dialogues, do not accurately capture the nuances and challenges of real-world conversational speech. This can lead to inflated performance metrics that do not translate to practical deployments of ASR technology.
By developing a diverse and representative dataset of natural, spontaneous conversations, the research community can establish more meaningful ASR benchmarks. This would enable better identification of biases, failures, and areas for improvement in current ASR systems, ultimately driving progress towards systems that can handle the complexities of everyday speech.
While creating such a dataset may present technical and logistical challenges, the potential benefits for advancing ASR technology and ensuring it is inclusive and representative of diverse users make it a worthwhile pursuit for the research community.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
New!ASR Benchmarking: Need for a More Representative Conversational Dataset
Gaurav Maheshwari, Dmitry Ivanov, Th'eo Johannet, Kevin El Haddad
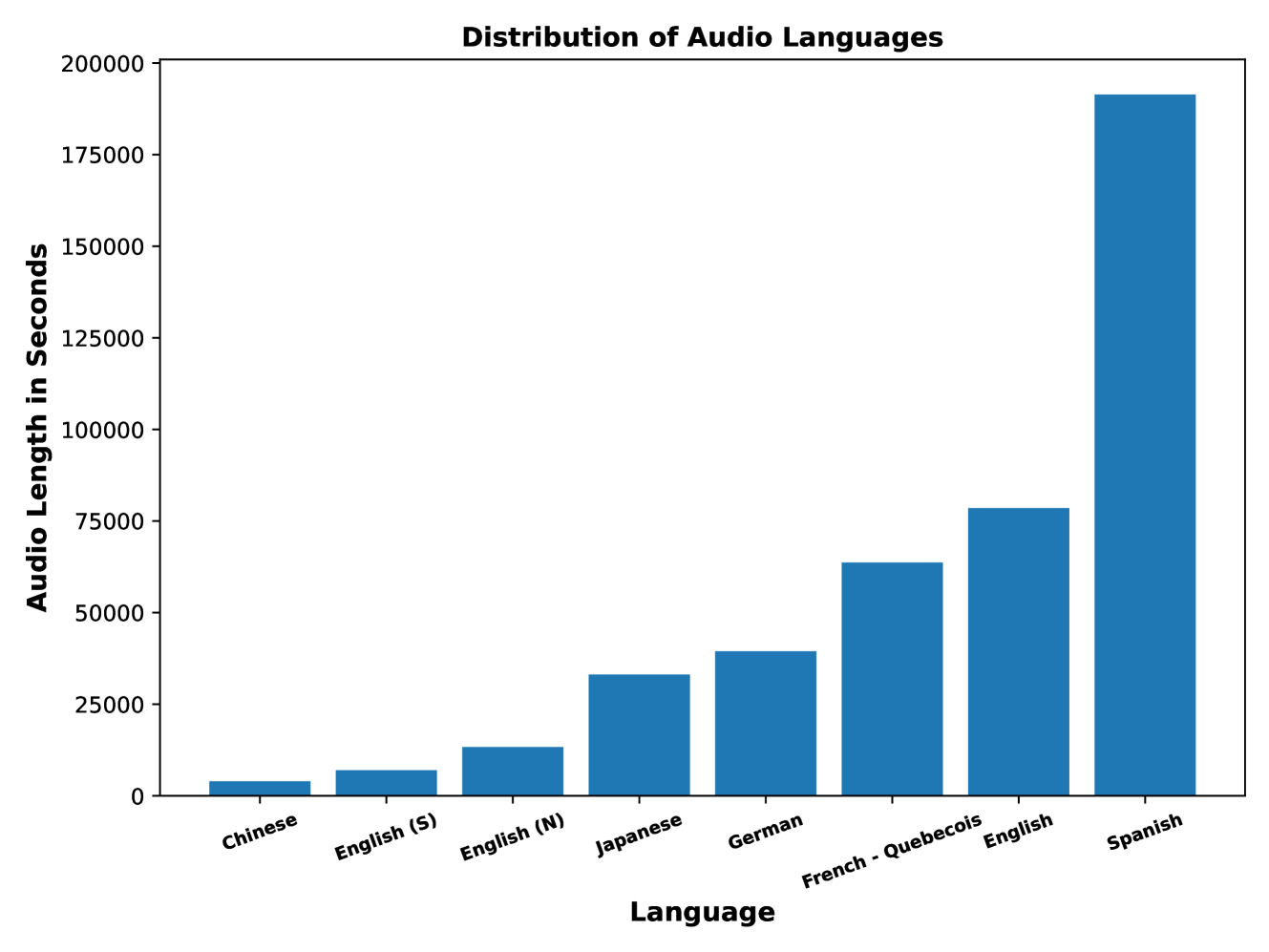
Automatic Speech Recognition (ASR) systems have achieved remarkable performance on widely used benchmarks such as LibriSpeech and Fleurs. However, these benchmarks do not adequately reflect the complexities of real-world conversational environments, where speech is often unstructured and contains disfluencies such as pauses, interruptions, and diverse accents. In this study, we introduce a multilingual conversational dataset, derived from TalkBank, consisting of unstructured phone conversation between adults. Our results show a significant performance drop across various state-of-the-art ASR models when tested in conversational settings. Furthermore, we observe a correlation between Word Error Rate and the presence of speech disfluencies, highlighting the critical need for more realistic, conversational ASR benchmarks.
Read more9/19/2024
0
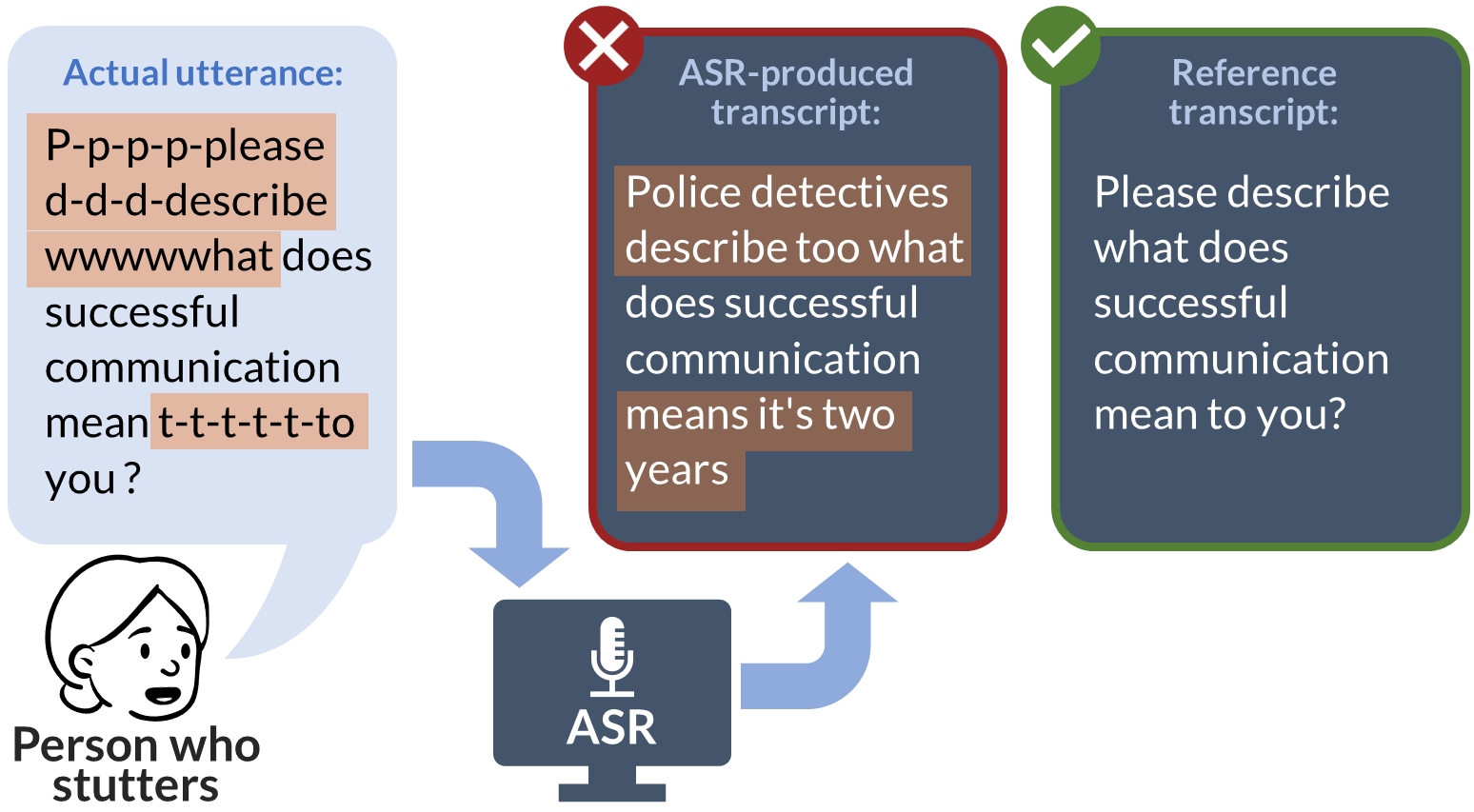
Lost in Transcription: Identifying and Quantifying the Accuracy Biases of Automatic Speech Recognition Systems Against Disfluent Speech
Dena Mujtaba, Nihar R. Mahapatra, Megan Arney, J. Scott Yaruss, Hope Gerlach-Houck, Caryn Herring, Jia Bin
Automatic speech recognition (ASR) systems, increasingly prevalent in education, healthcare, employment, and mobile technology, face significant challenges in inclusivity, particularly for the 80 million-strong global community of people who stutter. These systems often fail to accurately interpret speech patterns deviating from typical fluency, leading to critical usability issues and misinterpretations. This study evaluates six leading ASRs, analyzing their performance on both a real-world dataset of speech samples from individuals who stutter and a synthetic dataset derived from the widely-used LibriSpeech benchmark. The synthetic dataset, uniquely designed to incorporate various stuttering events, enables an in-depth analysis of each ASR's handling of disfluent speech. Our comprehensive assessment includes metrics such as word error rate (WER), character error rate (CER), and semantic accuracy of the transcripts. The results reveal a consistent and statistically significant accuracy bias across all ASRs against disfluent speech, manifesting in significant syntactical and semantic inaccuracies in transcriptions. These findings highlight a critical gap in current ASR technologies, underscoring the need for effective bias mitigation strategies. Addressing this bias is imperative not only to improve the technology's usability for people who stutter but also to ensure their equitable and inclusive participation in the rapidly evolving digital landscape.
Read more5/13/2024
🛸
0
Enabling ASR for Low-Resource Languages: A Comprehensive Dataset Creation Approach
Ara Yeroyan (Data Science Department, American University of Armenia), Nikolay Karpov (Nvidia, NeMo Conversational AI team)
In recent years, automatic speech recognition (ASR) systems have significantly improved, especially in languages with a vast amount of transcribed speech data. However, ASR systems tend to perform poorly for low-resource languages with fewer resources, such as minority and regional languages. This study introduces a novel pipeline designed to generate ASR training datasets from audiobooks, which typically feature a single transcript associated with hours-long audios. The common structure of these audiobooks poses a unique challenge due to the extensive length of audio segments, whereas optimal ASR training requires segments ranging from 4 to 15 seconds. To address this, we propose a method for effectively aligning audio with its corresponding text and segmenting it into lengths suitable for ASR training. Our approach simplifies data preparation for ASR systems in low-resource languages and demonstrates its application through a case study involving the Armenian language. Our method, which is portable to many low-resource languages, not only mitigates the issue of data scarcity but also enhances the performance of ASR models for underrepresented languages.
Read more6/4/2024
🤯
0
You don't understand me!: Comparing ASR results for L1 and L2 speakers of Swedish
Ronald Cumbal, Birger Moell, Jose Lopes, Olof Engwall
The performance of Automatic Speech Recognition (ASR) systems has constantly increased in state-of-the-art development. However, performance tends to decrease considerably in more challenging conditions (e.g., background noise, multiple speaker social conversations) and with more atypical speakers (e.g., children, non-native speakers or people with speech disorders), which signifies that general improvements do not necessarily transfer to applications that rely on ASR, e.g., educational software for younger students or language learners. In this study, we focus on the gap in performance between recognition results for native and non-native, read and spontaneous, Swedish utterances transcribed by different ASR services. We compare the recognition results using Word Error Rate and analyze the linguistic factors that may generate the observed transcription errors.
Read more5/24/2024