Assessing ML Classification Algorithms and NLP Techniques for Depression Detection: An Experimental Case Study
2404.04284
0
0
Abstract
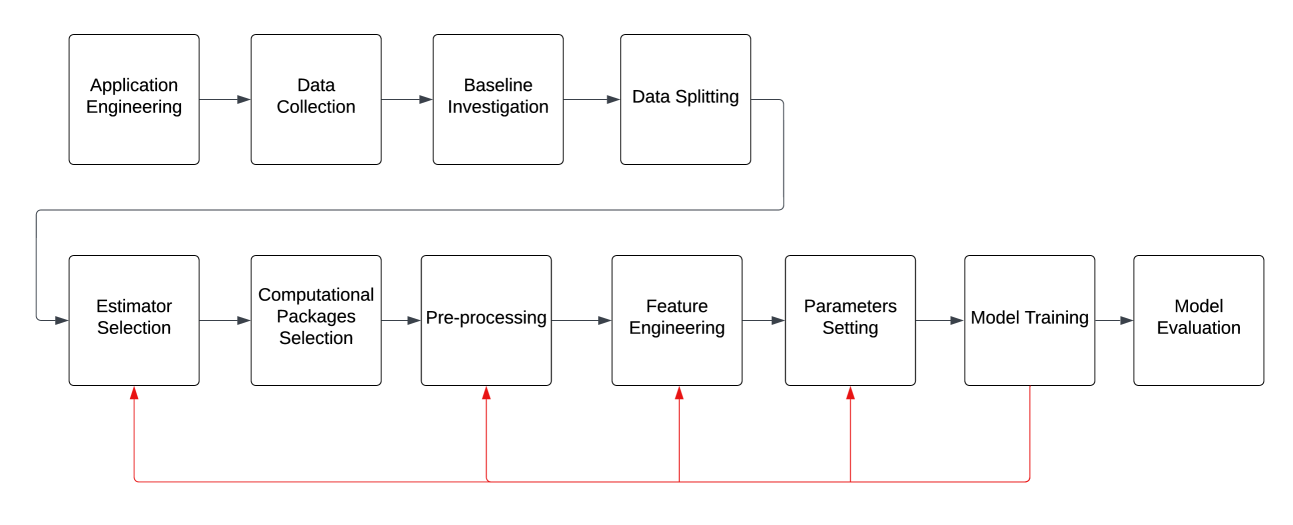
Depression has affected millions of people worldwide and has become one of the most common mental disorders. Early mental disorder detection can reduce costs for public health agencies and prevent other major comorbidities. Additionally, the shortage of specialized personnel is very concerning since Depression diagnosis is highly dependent on expert professionals and is time-consuming. Recent research has evidenced that machine learning (ML) and Natural Language Processing (NLP) tools and techniques have significantly bene ted the diagnosis of depression. However, there are still several challenges in the assessment of depression detection approaches in which other conditions such as post-traumatic stress disorder (PTSD) are present. These challenges include assessing alternatives in terms of data cleaning and pre-processing techniques, feature selection, and appropriate ML classification algorithms. This paper tackels such an assessment based on a case study that compares different ML classifiers, specifically in terms of data cleaning and pre-processing, feature selection, parameter setting, and model choices. The case study is based on the Distress Analysis Interview Corpus - Wizard-of-Oz (DAIC-WOZ) dataset, which is designed to support the diagnosis of mental disorders such as depression, anxiety, and PTSD. Besides the assessment of alternative techniques, we were able to build models with accuracy levels around 84% with Random Forest and XGBoost models, which is significantly higher than the results from the comparable literature which presented the level of accuracy of 72% from the SVM model.
Create account to get full access
Overview
- Explores the use of machine learning (ML) classification algorithms and natural language processing (NLP) techniques for detecting depression from text data
- Conducts an experimental case study to assess the performance of various ML models and NLP approaches
- Aims to identify the most effective methods for accurately identifying depression symptoms
Plain English Explanation
This research paper investigates the use of machine learning (ML) and natural language processing (NLP) to automatically detect signs of depression from text data, such as social media posts or online conversations. The researchers conducted an experimental case study to evaluate the performance of different ML classification algorithms and NLP techniques in identifying depression symptoms.
The core idea is that by analyzing the language and patterns of expression in text, we may be able to develop systems that can accurately identify individuals who are experiencing depression. This could be valuable for early intervention, providing support, and improving mental health outcomes. The researchers wanted to explore which specific ML and NLP approaches work best for this task.
The paper doesn't focus on developing a new ML or NLP model from scratch, but rather assesses the effectiveness of various existing techniques that have been used for depression detection. By comparing the performance of different methods, the researchers aim to identify the most reliable and accurate approaches for this important real-world application.
Technical Explanation
The researchers carried out a series of experiments to evaluate the suitability of different ML classification algorithms and NLP techniques for detecting depression from text data. They utilized a publicly available dataset of social media posts labeled with depression diagnoses to train and test their models.
The team experimented with a range of popular ML classifiers, including logistic regression, decision trees, random forests, and support vector machines. They also explored various NLP approaches, such as sentiment analysis, topic modeling, and word embedding techniques, to extract relevant features from the text data.
Through rigorous testing and evaluation, the researchers were able to identify the most effective combinations of ML models and NLP methods for accurately identifying depression symptoms. They analyzed the performance metrics, such as accuracy, precision, recall, and F1-score, to determine the most reliable and practical solutions for real-world depression detection.
The findings of this study provide valuable insights into the state-of-the-art in using ML and NLP for mental health applications. The researchers also discuss the limitations of their approach and highlight areas for further research, such as incorporating additional data sources, exploring deep learning techniques, and addressing ethical considerations in deploying such systems.
Critical Analysis
The researchers have conducted a thorough and well-designed experimental case study to assess the performance of various ML and NLP techniques for depression detection. The use of a publicly available dataset with labeled depression diagnoses is a strength, as it allows for a more objective and reproducible evaluation of the methods.
However, the paper does not delve into the potential biases or limitations of the dataset itself, which could impact the generalizability of the results. For example, the dataset may not be representative of the broader population or may reflect certain demographic or cultural biases. Additionally, the accuracy of the depression diagnoses used as ground truth labels is not discussed in detail.
Another potential limitation is the reliance on text data from social media platforms, which may not capture the full range of symptoms or experiences associated with depression. Incorporating additional data sources, such as clinical records or self-reported assessments, could provide a more comprehensive understanding of depression and its detection.
The paper also lacks a thorough discussion of the ethical implications of using ML and NLP for mental health applications. Issues around privacy, data security, and the potential for misdiagnosis or stigmatization should be carefully addressed, especially when deploying such systems in real-world settings.
Despite these caveats, the research presented in this paper contributes valuable insights to the field of mental health technology and provides a solid foundation for further developments in this important area of study.
Conclusion
The experimental case study described in this paper demonstrates the potential of using machine learning and natural language processing techniques to detect depression from text data. By evaluating the performance of various ML classification algorithms and NLP approaches, the researchers have identified promising methods that can reliably identify depression symptoms.
The findings of this study have significant implications for the development of systems that can assist in early intervention, provide targeted support, and improve mental health outcomes. As the use of technology in healthcare continues to grow, research like this can help shape the design and implementation of more accurate and ethical depression detection tools.
However, the limitations and ethical considerations discussed in the paper suggest that further research and careful implementation are necessary to ensure these technologies are used responsibly and effectively. Continued collaboration between researchers, clinicians, and the broader community will be crucial in advancing this important field of study.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Multi Class Depression Detection Through Tweets using Artificial Intelligence
Muhammad Osama Nusrat, Waseem Shahzad, Saad Ahmed Jamal
0
0
Depression is a significant issue nowadays. As per the World Health Organization (WHO), in 2023, over 280 million individuals are grappling with depression. This is a huge number; if not taken seriously, these numbers will increase rapidly. About 4.89 billion individuals are social media users. People express their feelings and emotions on platforms like Twitter, Facebook, Reddit, Instagram, etc. These platforms contain valuable information which can be used for research purposes. Considerable research has been conducted across various social media platforms. However, certain limitations persist in these endeavors. Particularly, previous studies were only focused on detecting depression and the intensity of depression in tweets. Also, there existed inaccuracies in dataset labeling. In this research work, five types of depression (Bipolar, major, psychotic, atypical, and postpartum) were predicted using tweets from the Twitter database based on lexicon labeling. Explainable AI was used to provide reasoning by highlighting the parts of tweets that represent type of depression. Bidirectional Encoder Representations from Transformers (BERT) was used for feature extraction and training. Machine learning and deep learning methodologies were used to train the model. The BERT model presented the most promising results, achieving an overall accuracy of 0.96.
4/23/2024
🔎
Diverse Perspectives, Divergent Models: Cross-Cultural Evaluation of Depression Detection on Twitter
Nuredin Ali, Charles Chuankai Zhang, Ned Mayo, Stevie Chancellor
0
0
Social media data has been used for detecting users with mental disorders, such as depression. Despite the global significance of cross-cultural representation and its potential impact on model performance, publicly available datasets often lack crucial metadata related to this aspect. In this work, we evaluate the generalization of benchmark datasets to build AI models on cross-cultural Twitter data. We gather a custom geo-located Twitter dataset of depressed users from seven countries as a test dataset. Our results show that depression detection models do not generalize globally. The models perform worse on Global South users compared to Global North. Pre-trained language models achieve the best generalization compared to Logistic Regression, though still show significant gaps in performance on depressed and non-Western users. We quantify our findings and provide several actionable suggestions to mitigate this issue.
6/26/2024

CASE: Curricular Data Pre-training for Building Generative and Discriminative Assistive Psychology Expert Models
Sarthak Harne, Monjoy Narayan Choudhury, Madhav Rao, TK Srikanth, Seema Mehrotra, Apoorva Vashisht, Aarushi Basu, Manjit Sodhi
0
0
The limited availability of psychologists necessitates efficient identification of individuals requiring urgent mental healthcare. This study explores the use of Natural Language Processing (NLP) pipelines to analyze text data from online mental health forums used for consultations. By analyzing forum posts, these pipelines can flag users who may require immediate professional attention. A crucial challenge in this domain is data privacy and scarcity. To address this, we propose utilizing readily available curricular texts used in institutes specializing in mental health for pre-training the NLP pipelines. This helps us mimic the training process of a psychologist. Our work presents CASE-BERT that flags potential mental health disorders based on forum text. CASE-BERT demonstrates superior performance compared to existing methods, achieving an f1 score of 0.91 for Depression and 0.88 for Anxiety, two of the most commonly reported mental health disorders. Our code is publicly available.
6/18/2024

We Care: Multimodal Depression Detection and Knowledge Infused Mental Health Therapeutic Response Generation
Palash Moon, Pushpak Bhattacharyya
0
0
The detection of depression through non-verbal cues has gained significant attention. Previous research predominantly centred on identifying depression within the confines of controlled laboratory environments, often with the supervision of psychologists or counsellors. Unfortunately, datasets generated in such controlled settings may struggle to account for individual behaviours in real-life situations. In response to this limitation, we present the Extended D-vlog dataset, encompassing a collection of 1, 261 YouTube vlogs. Additionally, the emergence of large language models (LLMs) like GPT3.5, and GPT4 has sparked interest in their potential they can act like mental health professionals. Yet, the readiness of these LLM models to be used in real-life settings is still a concern as they can give wrong responses that can harm the users. We introduce a virtual agent serving as an initial contact for mental health patients, offering Cognitive Behavioral Therapy (CBT)-based responses. It comprises two core functions: 1. Identifying depression in individuals, and 2. Delivering CBT-based therapeutic responses. Our Mistral model achieved impressive scores of 70.1% and 30.9% for distortion assessment and classification, along with a Bert score of 88.7%. Moreover, utilizing the TVLT model on our Multimodal Extended D-vlog Dataset yielded outstanding results, with an impressive F1-score of 67.8%
6/18/2024