We Care: Multimodal Depression Detection and Knowledge Infused Mental Health Therapeutic Response Generation
2406.10561
0
0

Abstract
The detection of depression through non-verbal cues has gained significant attention. Previous research predominantly centred on identifying depression within the confines of controlled laboratory environments, often with the supervision of psychologists or counsellors. Unfortunately, datasets generated in such controlled settings may struggle to account for individual behaviours in real-life situations. In response to this limitation, we present the Extended D-vlog dataset, encompassing a collection of 1, 261 YouTube vlogs. Additionally, the emergence of large language models (LLMs) like GPT3.5, and GPT4 has sparked interest in their potential they can act like mental health professionals. Yet, the readiness of these LLM models to be used in real-life settings is still a concern as they can give wrong responses that can harm the users. We introduce a virtual agent serving as an initial contact for mental health patients, offering Cognitive Behavioral Therapy (CBT)-based responses. It comprises two core functions: 1. Identifying depression in individuals, and 2. Delivering CBT-based therapeutic responses. Our Mistral model achieved impressive scores of 70.1% and 30.9% for distortion assessment and classification, along with a Bert score of 88.7%. Moreover, utilizing the TVLT model on our Multimodal Extended D-vlog Dataset yielded outstanding results, with an impressive F1-score of 67.8%
Create account to get full access
Overview
- This paper presents a novel approach for detecting depression and generating therapeutic responses using multimodal data and knowledge-infused language models.
- The researchers developed a system that can analyze text, audio, and visual inputs to identify signs of depression, and then generate personalized mental health support content.
- The system leverages large language models and external knowledge sources to provide contextualized and evidence-based therapeutic recommendations.
Plain English Explanation
The paper describes a system that aims to help people struggling with depression. The system can look at different types of information, like what someone writes, how they sound, and what they look like, to try to detect if they are showing signs of depression.
Once the system identifies someone as potentially depressed, it can then generate personalized messages to provide support and guidance. These messages draw on large language models, which are AI systems trained on huge amounts of text data, as well as other knowledge sources about mental health.
The goal is to create an intelligent system that can both identify when someone may be depressed and then provide thoughtful, tailored responses to help them. This could be useful for providing mental health support at scale, especially for people who may not have easy access to human therapists or counselors.
Technical Explanation
The paper presents a multimodal depression detection and therapeutic response generation system called "We Care". The system takes in text, audio, and visual inputs from a user and uses deep learning models to analyze these modalities and detect signs of depression.
For the depression detection task, the authors fine-tune large language models like BERT and XLNet on datasets of social media posts, interviews, and other data labeled for depression. They also incorporate audio and visual features extracted from speech and facial expressions.
To generate therapeutic responses, the system leverages knowledge-infused language models that have been pre-trained on mental health-related content from sources like clinical guidelines and patient forums. This allows the system to provide personalized, contextual recommendations grounded in established best practices.
The authors evaluate the system's performance on depression detection and response generation tasks, showing strong results compared to prior work. They also conduct qualitative analyses to assess the relevance and empathy of the generated responses.
Critical Analysis
The paper presents an impressive technical system that combines multimodal sensing, large language models, and external knowledge sources to address the important challenge of supporting people with depression. The authors demonstrate solid empirical results and thoughtful design choices.
However, some potential limitations or concerns are not fully addressed. For example, the system relies on datasets and knowledge bases that may encode societal biases, which could lead to problematic or insensitive response generation, especially for marginalized groups. The authors do not discuss potential privacy or ethical considerations around collecting and processing personal data for mental health applications.
Additionally, while the system's ability to generate personalized content is a strength, further research is needed to ensure the responses are truly empathetic and beneficial rather than generic or potentially harmful. Longitudinal studies would be valuable to understand the real-world impact of such a system on users' mental health outcomes.
Overall, the paper represents an important step forward, but continued innovation and rigorous testing will be crucial to responsibly deploy these types of AI-powered mental health tools at scale.
Conclusion
This paper presents an innovative approach to supporting people with depression using multimodal sensing, large language models, and external knowledge. By combining these techniques, the researchers have developed a system that can detect signs of depression and generate personalized therapeutic responses.
The system's ability to leverage diverse data sources and provide tailored support has significant potential to expand access to mental health resources, especially for those who may not have regular access to human clinicians. However, the authors acknowledge important limitations and ethical considerations that will need to be carefully addressed as this technology matures.
Ultimately, this research represents an important contribution to the growing field of AI-powered mental health solutions. As these technologies continue to evolve, it will be crucial to prioritize user privacy, avoid biases, and rigorously evaluate their real-world impact to ensure they provide meaningful and ethical support to those in need.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔎
New!LMVD: A Large-Scale Multimodal Vlog Dataset for Depression Detection in the Wild
Lang He, Kai Chen, Junnan Zhao, Yimeng Wang, Ercheng Pei, Haifeng Chen, Jiewei Jiang, Shiqing Zhang, Jie Zhang, Zhongmin Wang, Tao He, Prayag Tiwari
0
0
Depression can significantly impact many aspects of an individual's life, including their personal and social functioning, academic and work performance, and overall quality of life. Many researchers within the field of affective computing are adopting deep learning technology to explore potential patterns related to the detection of depression. However, because of subjects' privacy protection concerns, that data in this area is still scarce, presenting a challenge for the deep discriminative models used in detecting depression. To navigate these obstacles, a large-scale multimodal vlog dataset (LMVD), for depression recognition in the wild is built. In LMVD, which has 1823 samples with 214 hours of the 1475 participants captured from four multimedia platforms (Sina Weibo, Bilibili, Tiktok, and YouTube). A novel architecture termed MDDformer to learn the non-verbal behaviors of individuals is proposed. Extensive validations are performed on the LMVD dataset, demonstrating superior performance for depression detection. We anticipate that the LMVD will contribute a valuable function to the depression detection community. The data and code will released at the link: https://github.com/helang818/LMVD/.
7/2/2024
🔎
Diverse Perspectives, Divergent Models: Cross-Cultural Evaluation of Depression Detection on Twitter
Nuredin Ali, Charles Chuankai Zhang, Ned Mayo, Stevie Chancellor
0
0
Social media data has been used for detecting users with mental disorders, such as depression. Despite the global significance of cross-cultural representation and its potential impact on model performance, publicly available datasets often lack crucial metadata related to this aspect. In this work, we evaluate the generalization of benchmark datasets to build AI models on cross-cultural Twitter data. We gather a custom geo-located Twitter dataset of depressed users from seven countries as a test dataset. Our results show that depression detection models do not generalize globally. The models perform worse on Global South users compared to Global North. Pre-trained language models achieve the best generalization compared to Logistic Regression, though still show significant gaps in performance on depressed and non-Western users. We quantify our findings and provide several actionable suggestions to mitigate this issue.
6/26/2024
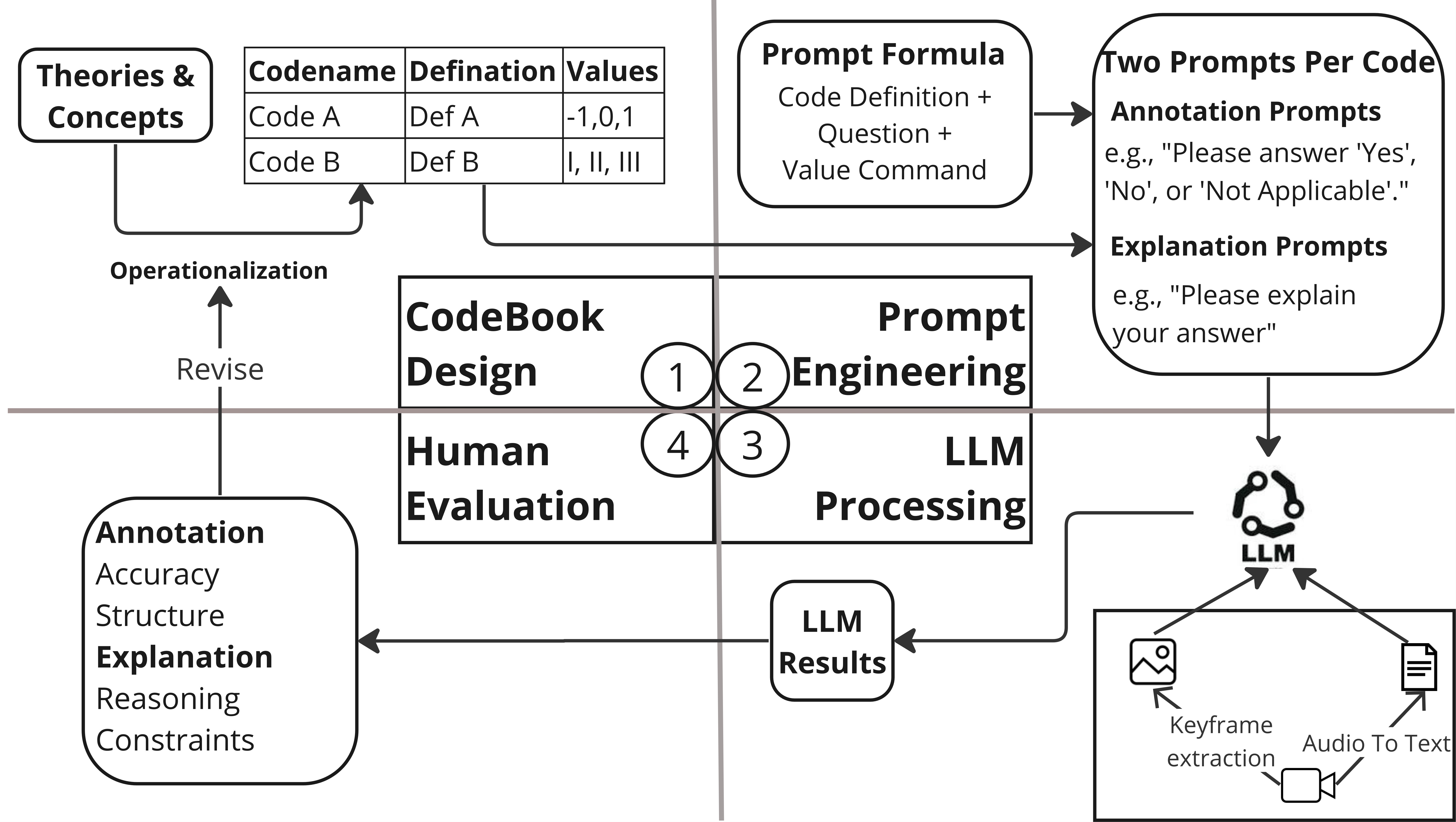
New!Using Large Language Models to Assist Video Content Analysis: An Exploratory Study of Short Videos on Depression
Jiaying Liu, Yunlong Wang, Yao Lyu, Yiheng Su, Shuo Niu, Xuhai Orson Xu, Yan Zhang
0
0
Despite the growing interest in leveraging Large Language Models (LLMs) for content analysis, current studies have primarily focused on text-based content. In the present work, we explored the potential of LLMs in assisting video content analysis by conducting a case study that followed a new workflow of LLM-assisted multimodal content analysis. The workflow encompasses codebook design, prompt engineering, LLM processing, and human evaluation. We strategically crafted annotation prompts to get LLM Annotations in structured form and explanation prompts to generate LLM Explanations for a better understanding of LLM reasoning and transparency. To test LLM's video annotation capabilities, we analyzed 203 keyframes extracted from 25 YouTube short videos about depression. We compared the LLM Annotations with those of two human coders and found that LLM has higher accuracy in object and activity Annotations than emotion and genre Annotations. Moreover, we identified the potential and limitations of LLM's capabilities in annotating videos. Based on the findings, we explore opportunities and challenges for future research and improvements to the workflow. We also discuss ethical concerns surrounding future studies based on LLM-assisted video analysis.
7/1/2024
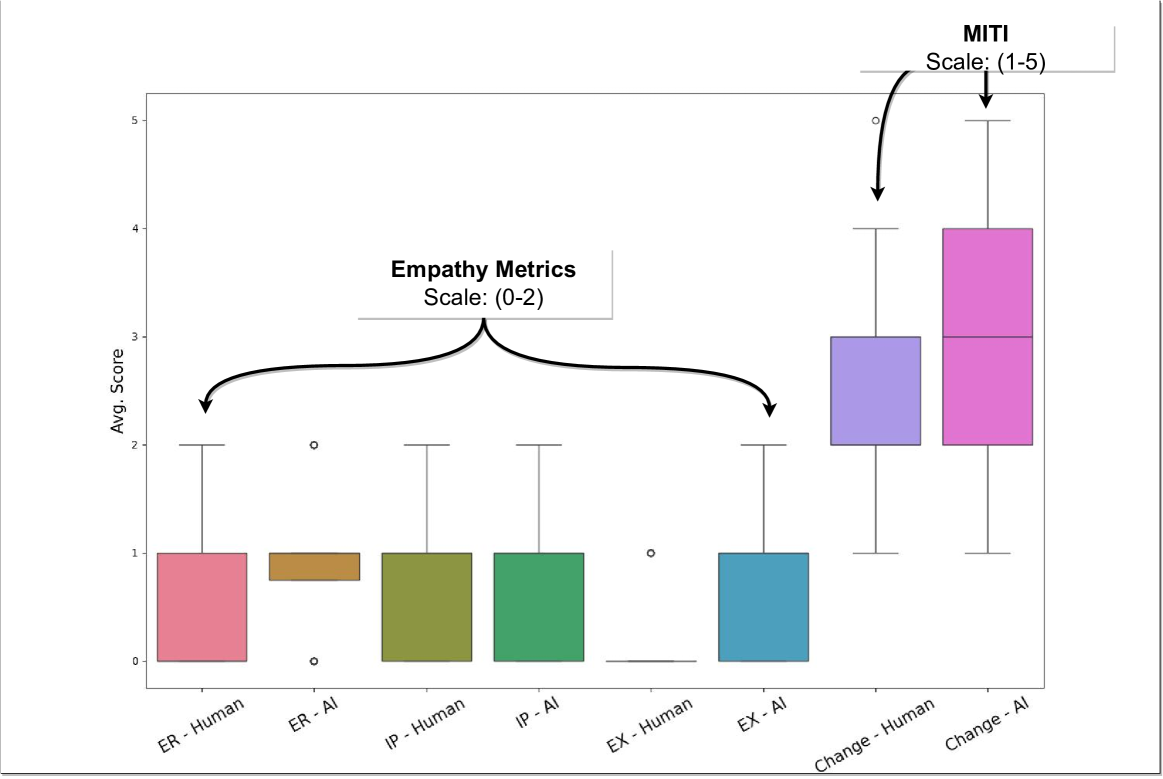
Can AI Relate: Testing Large Language Model Response for Mental Health Support
Saadia Gabriel, Isha Puri, Xuhai Xu, Matteo Malgaroli, Marzyeh Ghassemi
0
0
Large language models (LLMs) are already being piloted for clinical use in hospital systems like NYU Langone, Dana-Farber and the NHS. A proposed deployment use case is psychotherapy, where a LLM-powered chatbot can treat a patient undergoing a mental health crisis. Deployment of LLMs for mental health response could hypothetically broaden access to psychotherapy and provide new possibilities for personalizing care. However, recent high-profile failures, like damaging dieting advice offered by the Tessa chatbot to patients with eating disorders, have led to doubt about their reliability in high-stakes and safety-critical settings. In this work, we develop an evaluation framework for determining whether LLM response is a viable and ethical path forward for the automation of mental health treatment. Using human evaluation with trained clinicians and automatic quality-of-care metrics grounded in psychology research, we compare the responses provided by peer-to-peer responders to those provided by a state-of-the-art LLM. We show that LLMs like GPT-4 use implicit and explicit cues to infer patient demographics like race. We then show that there are statistically significant discrepancies between patient subgroups: Responses to Black posters consistently have lower empathy than for any other demographic group (2%-13% lower than the control group). Promisingly, we do find that the manner in which responses are generated significantly impacts the quality of the response. We conclude by proposing safety guidelines for the potential deployment of LLMs for mental health response.
5/21/2024