Attention Down-Sampling Transformer, Relative Ranking and Self-Consistency for Blind Image Quality Assessment

0

Sign in to get full access
Overview
- This paper proposes a new deep learning-based model for blind image quality assessment (IQA)
- The model uses an attention down-sampling transformer, relative ranking, and self-consistency to achieve state-of-the-art performance
- The authors evaluate the model on several standard IQA datasets and compare it to other leading approaches
Plain English Explanation
The researchers have developed a new AI model for evaluating the quality of images without having access to the original high-quality version. This is known as "blind image quality assessment."
The key innovations in their approach are:
-
Attention Down-Sampling Transformer: This component of the model focuses on the most important parts of the image by selectively downscaling less relevant regions. This helps the model better understand what aspects of the image are most important for assessing quality.
-
Relative Ranking: The model is trained not just to predict an absolute quality score, but also to rank images relative to each other. This relative comparison seems to be an effective way for the model to learn what high and low quality looks like.
-
Self-Consistency: The model is trained to be self-consistent, meaning it should produce similar quality predictions for the same image across multiple evaluations. This helps stabilize the model's outputs.
By combining these three techniques, the researchers were able to create a blind IQA model that outperforms other leading approaches on standard benchmark datasets. This could be useful for applications like image compression, enhancement, and retrieval, where automatically assessing image quality is important.
Technical Explanation
The proposed Attention Down-Sampling Transformer, Relative Ranking and Self-Consistency for Blind Image Quality Assessment model has three key components:
-
Attention Down-Sampling Transformer (ADST): This is the main backbone of the model, which uses an attention mechanism to selectively downscale less relevant regions of the input image. This allows the model to focus its capacity on the most important parts of the image for quality assessment.
-
Relative Ranking Module: In addition to predicting an absolute quality score, the model is trained to rank images relative to each other. This relative comparison seems to be an effective way for the model to learn what high and low quality looks like.
-
Self-Consistency Module: The model is trained to be self-consistent, meaning it should produce similar quality predictions for the same image across multiple evaluations. This helps stabilize the model's outputs and improve its robustness.
The researchers evaluated their model on several standard IQA datasets, including LIVE, TID2013, and KADID-10k. They showed that their approach outperforms other state-of-the-art blind IQA models in terms of correlation with human quality scores.
Critical Analysis
The paper provides a thorough evaluation of the proposed model and compares it to other leading blind IQA approaches. However, the authors do acknowledge some limitations:
- The model was only evaluated on standard benchmark datasets, and its performance on real-world, diverse image datasets is still unknown.
- The model's robustness to adversarial attacks was not tested, which is an important consideration for real-world deployment.
- The computational complexity of the model was not analyzed, which could be a concern for certain applications that require fast inference.
Further research could explore the model's generalization capabilities, robustness, and efficiency to better understand its practical implications and potential areas for improvement.
Conclusion
The Attention Down-Sampling Transformer, Relative Ranking and Self-Consistency for Blind Image Quality Assessment model proposed in this paper represents a significant advancement in the field of blind image quality assessment. By combining novel architectural components with relative ranking and self-consistency, the researchers have developed a highly effective model that outperforms other state-of-the-art approaches.
This work could have important implications for applications that rely on automatic image quality evaluation, such as image compression, enhancement, and retrieval. As the authors continue to explore the model's capabilities and limitations, it will be exciting to see how this technology develops and is applied in real-world scenarios.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Attention Down-Sampling Transformer, Relative Ranking and Self-Consistency for Blind Image Quality Assessment
Mohammed Alsaafin, Musab Alsheikh, Saeed Anwar, Muhammad Usman
The no-reference image quality assessment is a challenging domain that addresses estimating image quality without the original reference. We introduce an improved mechanism to extract local and non-local information from images via different transformer encoders and CNNs. The utilization of Transformer encoders aims to mitigate locality bias and generate a non-local representation by sequentially processing CNN features, which inherently capture local visual structures. Establishing a stronger connection between subjective and objective assessments is achieved through sorting within batches of images based on relative distance information. A self-consistency approach to self-supervision is presented, explicitly addressing the degradation of no-reference image quality assessment (NR-IQA) models under equivariant transformations. Our approach ensures model robustness by maintaining consistency between an image and its horizontally flipped equivalent. Through empirical evaluation of five popular image quality assessment datasets, the proposed model outperforms alternative algorithms in the context of no-reference image quality assessment datasets, especially on smaller datasets. Codes are available at href{https://github.com/mas94/ADTRS}{https://github.com/mas94/ADTRS}
Read more9/12/2024
🤷
0
Cross-IQA: Unsupervised Learning for Image Quality Assessment
Zhen Zhang
Automatic perception of image quality is a challenging problem that impacts billions of Internet and social media users daily. To advance research in this field, we propose a no-reference image quality assessment (NR-IQA) method termed Cross-IQA based on vision transformer(ViT) model. The proposed Cross-IQA method can learn image quality features from unlabeled image data. We construct the pretext task of synthesized image reconstruction to unsupervised extract the image quality information based ViT block. The pretrained encoder of Cross-IQA is used to fine-tune a linear regression model for score prediction. Experimental results show that Cross-IQA can achieve state-of-the-art performance in assessing the low-frequency degradation information (e.g., color change, blurring, etc.) of images compared with the classical full-reference IQA and NR-IQA under the same datasets.
Read more5/8/2024
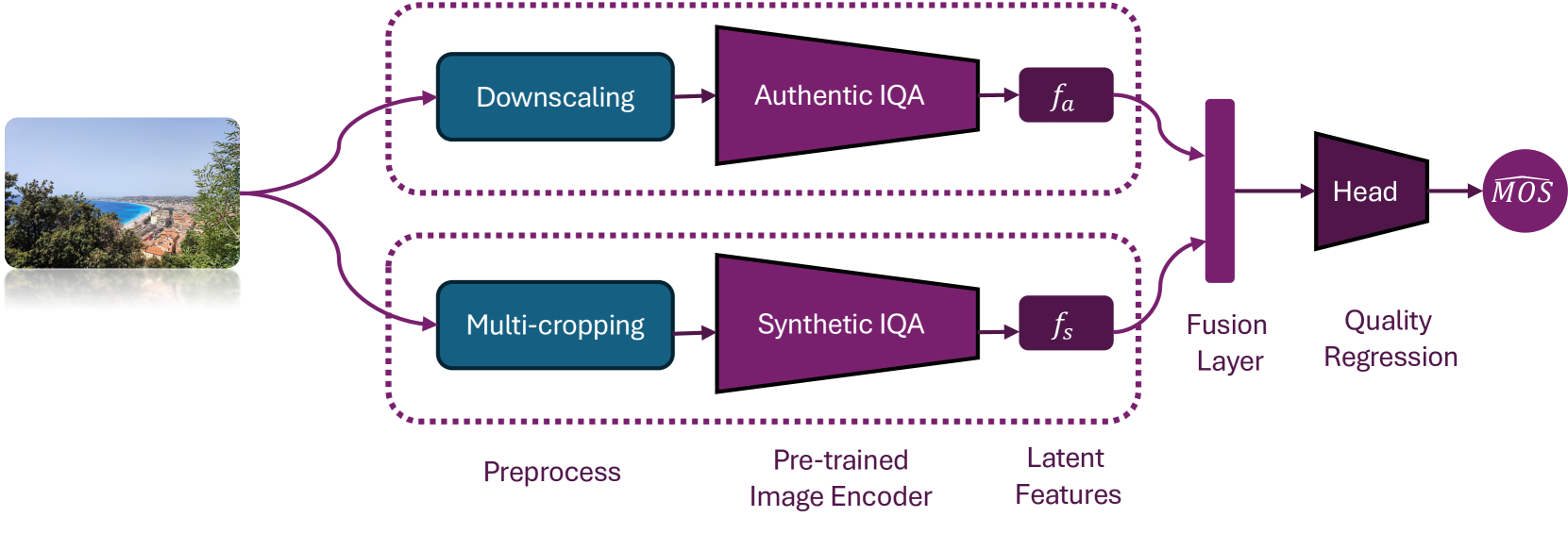
0
LAR-IQA: A Lightweight, Accurate, and Robust No-Reference Image Quality Assessment Model
Nasim Jamshidi Avanaki, Abhijay Ghildyal, Nabajeet Barman, Saman Zadtootaghaj
Recent advancements in the field of No-Reference Image Quality Assessment (NR-IQA) using deep learning techniques demonstrate high performance across multiple open-source datasets. However, such models are typically very large and complex making them not so suitable for real-world deployment, especially on resource- and battery-constrained mobile devices. To address this limitation, we propose a compact, lightweight NR-IQA model that achieves state-of-the-art (SOTA) performance on ECCV AIM UHD-IQA challenge validation and test datasets while being also nearly 5.7 times faster than the fastest SOTA model. Our model features a dual-branch architecture, with each branch separately trained on synthetically and authentically distorted images which enhances the model's generalizability across different distortion types. To improve robustness under diverse real-world visual conditions, we additionally incorporate multiple color spaces during the training process. We also demonstrate the higher accuracy of recently proposed Kolmogorov-Arnold Networks (KANs) for final quality regression as compared to the conventional Multi-Layer Perceptrons (MLPs). Our evaluation considering various open-source datasets highlights the practical, high-accuracy, and robust performance of our proposed lightweight model. Code: https://github.com/nasimjamshidi/LAR-IQA.
Read more9/9/2024

0
Exploring Vulnerabilities of No-Reference Image Quality Assessment Models: A Query-Based Black-Box Method
Chenxi Yang, Yujia Liu, Dingquan Li, Tingting Jiang
No-Reference Image Quality Assessment (NR-IQA) aims to predict image quality scores consistent with human perception without relying on pristine reference images, serving as a crucial component in various visual tasks. Ensuring the robustness of NR-IQA methods is vital for reliable comparisons of different image processing techniques and consistent user experiences in recommendations. The attack methods for NR-IQA provide a powerful instrument to test the robustness of NR-IQA. However, current attack methods of NR-IQA heavily rely on the gradient of the NR-IQA model, leading to limitations when the gradient information is unavailable. In this paper, we present a pioneering query-based black box attack against NR-IQA methods. We propose the concept of score boundary and leverage an adaptive iterative approach with multiple score boundaries. Meanwhile, the initial attack directions are also designed to leverage the characteristics of the Human Visual System (HVS). Experiments show our method outperforms all compared state-of-the-art attack methods and is far ahead of previous black-box methods. The effective NR-IQA model DBCNN suffers a Spearman's rank-order correlation coefficient (SROCC) decline of 0.6381 attacked by our method, revealing the vulnerability of NR-IQA models to black-box attacks. The proposed attack method also provides a potent tool for further exploration into NR-IQA robustness.
Read more4/29/2024