AttentionHand: Text-driven Controllable Hand Image Generation for 3D Hand Reconstruction in the Wild

0

Sign in to get full access
Overview
- This paper presents a new method called AttentionHand for generating realistic hand images from text descriptions.
- The generated hand images can be used for 3D hand reconstruction in the wild, where hands are captured in unconstrained real-world environments.
- The method uses attention mechanisms to learn the relationship between text and hand poses, allowing it to generate diverse and controllable hand images.
Plain English Explanation
[object Object] The researchers developed a new way to generate realistic hand images based on text descriptions. This is useful for reconstructing 3D hand models from images captured in everyday, unconstrained environments, where hands can be in various poses and viewpoints.
The key idea is to use [object Object] to learn the relationship between the text description and the corresponding hand pose. This allows the system to generate diverse and controllable hand images that match the input text.
For example, you could provide a text description like "a hand making a thumbs up gesture," and the system would generate a realistic image of a hand in that pose. This generated image could then be used to reconstruct a 3D model of the hand, even in complex real-world scenes.
Technical Explanation
The [object Object] model uses an encoder-decoder architecture with attention mechanisms to translate text descriptions into realistic hand images. The encoder takes the text input and produces a latent representation, while the decoder generates the hand image conditioned on this representation.
The attention module learns to focus on the relevant parts of the text when generating each part of the hand image. This allows the model to capture the relationship between the text and the hand pose, enabling fine-grained control over the generated output.
The researchers trained and evaluated the model on a large dataset of hand images and corresponding text descriptions. They showed that AttentionHand outperforms previous methods in terms of both image quality and alignment with the text input. The generated hand images were also effective for [object Object] in the wild, demonstrating the practical utility of the approach.
Critical Analysis
The paper presents a compelling approach to text-driven hand image generation, but there are a few potential limitations and areas for further research:
-
The model was trained and evaluated on a limited dataset of hand images, so its performance on more diverse real-world data is unclear. [object Object] could help improve the model's generalization.
-
The paper does not provide a detailed analysis of the attention mechanism and its inner workings. A deeper understanding of how the attention module learns the text-to-image mapping could lead to further improvements.
-
While the generated hand images are realistic, the paper does not assess their usefulness for downstream tasks like hand gesture recognition or sign language interpretation. Evaluating the model's performance in these real-world applications would be valuable.
Overall, the AttentionHand method represents an exciting advance in text-driven image generation and 3D hand reconstruction, with the potential for significant impact in a variety of applications.
Conclusion
The [object Object] paper presents a novel approach for generating realistic hand images from text descriptions, which can be used to reconstruct 3D hand models in the wild. The key innovation is the use of attention mechanisms to learn the relationship between text and hand poses, enabling fine-grained control over the generated output.
The results demonstrate the effectiveness of the AttentionHand model for producing diverse and accurate hand images, which can be leveraged for 3D hand reconstruction in unconstrained real-world environments. This could have important applications in areas like gesture recognition, sign language interpretation, and human-computer interaction.
While the paper shows promise, there are opportunities for further research to address the limitations and explore the model's performance in real-world scenarios. Overall, the AttentionHand method represents an exciting advancement in the field of text-driven image generation and 3D hand modeling.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
AttentionHand: Text-driven Controllable Hand Image Generation for 3D Hand Reconstruction in the Wild
Junho Park, Kyeongbo Kong, Suk-Ju Kang
Recently, there has been a significant amount of research conducted on 3D hand reconstruction to use various forms of human-computer interaction. However, 3D hand reconstruction in the wild is challenging due to extreme lack of in-the-wild 3D hand datasets. Especially, when hands are in complex pose such as interacting hands, the problems like appearance similarity, self-handed occclusion and depth ambiguity make it more difficult. To overcome these issues, we propose AttentionHand, a novel method for text-driven controllable hand image generation. Since AttentionHand can generate various and numerous in-the-wild hand images well-aligned with 3D hand label, we can acquire a new 3D hand dataset, and can relieve the domain gap between indoor and outdoor scenes. Our method needs easy-to-use four modalities (i.e, an RGB image, a hand mesh image from 3D label, a bounding box, and a text prompt). These modalities are embedded into the latent space by the encoding phase. Then, through the text attention stage, hand-related tokens from the given text prompt are attended to highlight hand-related regions of the latent embedding. After the highlighted embedding is fed to the visual attention stage, hand-related regions in the embedding are attended by conditioning global and local hand mesh images with the diffusion-based pipeline. In the decoding phase, the final feature is decoded to new hand images, which are well-aligned with the given hand mesh image and text prompt. As a result, AttentionHand achieved state-of-the-art among text-to-hand image generation models, and the performance of 3D hand mesh reconstruction was improved by additionally training with hand images generated by AttentionHand.
Read more7/26/2024

0
HanDiffuser: Text-to-Image Generation With Realistic Hand Appearances
Supreeth Narasimhaswamy, Uttaran Bhattacharya, Xiang Chen, Ishita Dasgupta, Saayan Mitra, Minh Hoai
Text-to-image generative models can generate high-quality humans, but realism is lost when generating hands. Common artifacts include irregular hand poses, shapes, incorrect numbers of fingers, and physically implausible finger orientations. To generate images with realistic hands, we propose a novel diffusion-based architecture called HanDiffuser that achieves realism by injecting hand embeddings in the generative process. HanDiffuser consists of two components: a Text-to-Hand-Params diffusion model to generate SMPL-Body and MANO-Hand parameters from input text prompts, and a Text-Guided Hand-Params-to-Image diffusion model to synthesize images by conditioning on the prompts and hand parameters generated by the previous component. We incorporate multiple aspects of hand representation, including 3D shapes and joint-level finger positions, orientations and articulations, for robust learning and reliable performance during inference. We conduct extensive quantitative and qualitative experiments and perform user studies to demonstrate the efficacy of our method in generating images with high-quality hands.
Read more4/23/2024
0
Text2HOI: Text-guided 3D Motion Generation for Hand-Object Interaction
Junuk Cha, Jihyeon Kim, Jae Shin Yoon, Seungryul Baek
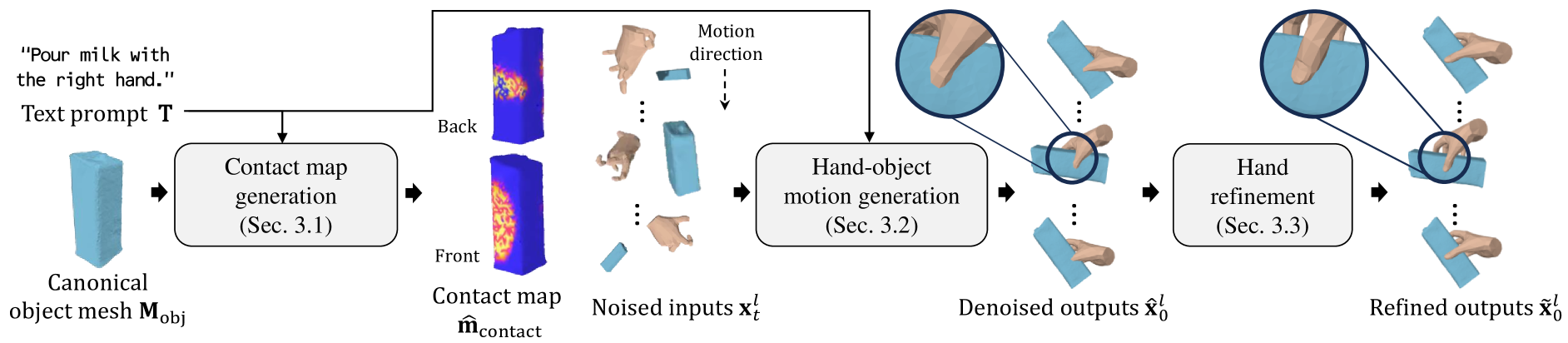
This paper introduces the first text-guided work for generating the sequence of hand-object interaction in 3D. The main challenge arises from the lack of labeled data where existing ground-truth datasets are nowhere near generalizable in interaction type and object category, which inhibits the modeling of diverse 3D hand-object interaction with the correct physical implication (e.g., contacts and semantics) from text prompts. To address this challenge, we propose to decompose the interaction generation task into two subtasks: hand-object contact generation; and hand-object motion generation. For contact generation, a VAE-based network takes as input a text and an object mesh, and generates the probability of contacts between the surfaces of hands and the object during the interaction. The network learns a variety of local geometry structure of diverse objects that is independent of the objects' category, and thus, it is applicable to general objects. For motion generation, a Transformer-based diffusion model utilizes this 3D contact map as a strong prior for generating physically plausible hand-object motion as a function of text prompts by learning from the augmented labeled dataset; where we annotate text labels from many existing 3D hand and object motion data. Finally, we further introduce a hand refiner module that minimizes the distance between the object surface and hand joints to improve the temporal stability of the object-hand contacts and to suppress the penetration artifacts. In the experiments, we demonstrate that our method can generate more realistic and diverse interactions compared to other baseline methods. We also show that our method is applicable to unseen objects. We will release our model and newly labeled data as a strong foundation for future research. Codes and data are available in: https://github.com/JunukCha/Text2HOI.
Read more4/3/2024
0
4DHands: Reconstructing Interactive Hands in 4D with Transformers
Dixuan Lin, Yuxiang Zhang, Mengcheng Li, Yebin Liu, Wei Jing, Qi Yan, Qianying Wang, Hongwen Zhang
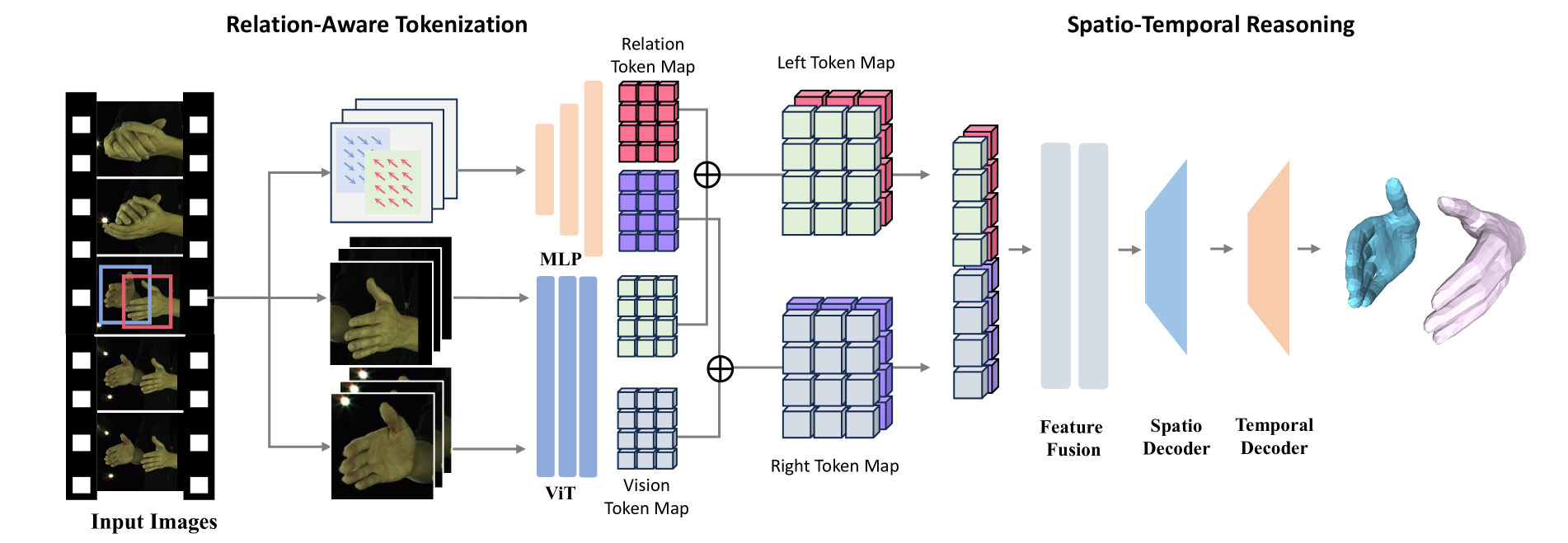
In this paper, we introduce 4DHands, a robust approach to recovering interactive hand meshes and their relative movement from monocular inputs. Our approach addresses two major limitations of previous methods: lacking a unified solution for handling various hand image inputs and neglecting the positional relationship of two hands within images. To overcome these challenges, we develop a transformer-based architecture with novel tokenization and feature fusion strategies. Specifically, we propose a Relation-aware Two-Hand Tokenization (RAT) method to embed positional relation information into the hand tokens. In this way, our network can handle both single-hand and two-hand inputs and explicitly leverage relative hand positions, facilitating the reconstruction of intricate hand interactions in real-world scenarios. As such tokenization indicates the relative relationship of two hands, it also supports more effective feature fusion. To this end, we further develop a Spatio-temporal Interaction Reasoning (SIR) module to fuse hand tokens in 4D with attention and decode them into 3D hand meshes and relative temporal movements. The efficacy of our approach is validated on several benchmark datasets. The results on in-the-wild videos and real-world scenarios demonstrate the superior performances of our approach for interactive hand reconstruction. More video results can be found on the project page: https://4dhands.github.io.
Read more6/3/2024