Attribute Based Interpretable Evaluation Metrics for Generative Models

0
🎲
Sign in to get full access
Overview
- Existing metrics do not provide interpretability beyond diversity for generative models
- Propose a new evaluation protocol to measure the divergence of generated images from the training set distribution
- Introduce Single-attribute Divergence (SaD) and Paired-attribute Divergence (PaD) to identify which attributes models struggle with
- Propose Heterogeneous CLIPScore (HCS) to measure attribute strengths in images
Plain English Explanation
Generative models are AI systems that can create new images, text, or other content by learning from a training dataset. When the training data has an equal number of dogs and cats, a good generative model should produce an equal number of dogs and cats as well. However, existing evaluation metrics don't tell us much about how well the model has captured the underlying distribution of the training data.
To address this, the researchers propose a new way to evaluate generative models. They introduce two new metrics: Single-attribute Divergence (SaD) and Paired-attribute Divergence (PaD). These metrics measure how much the distribution of attributes (like color, texture, or object size) in the generated images differs from the training data.
For example, if the training data has a wide range of colors but the generated images only have a few colors, the SaD metric would capture this mismatch. The PaD metric would look at how well the model captures relationships between attributes, like the size of an object and its color.
To measure these attribute strengths, the researchers also introduce a new method called Heterogeneous CLIPScore (HCS). This uses a neural network to compare the visual and textual representations of an image and assess how well they match.
By using SaD, PaD, and HCS, the researchers were able to uncover interesting insights about existing generative models. For instance, they found that Projected GAN can generate images with implausible attribute relationships, like a baby with a beard. They also discovered that diffusion models struggle to capture diverse colors and that larger sampling steps in latent diffusion models result in the generation of smaller objects like earrings and necklaces.
These new evaluation metrics provide a more detailed and interpretable way to assess the performance of generative models, going beyond just looking at overall image quality or diversity.
Technical Explanation
The researchers propose a new evaluation protocol to measure the divergence of a set of generated images from the training set regarding the distribution of attribute strengths. They introduce two new metrics:
- Single-attribute Divergence (SaD): Measures the divergence regarding the probability density functions (PDFs) of a single attribute, such as color or texture.
- Paired-attribute Divergence (PaD): Measures the divergence regarding the joint PDFs of a pair of attributes, such as the relationship between object size and color.
To measure the attribute strengths of an image, the researchers propose a new method called Heterogeneous CLIPScore (HCS). HCS measures the cosine similarity between image and text vectors with heterogeneous initial points, providing a way to assess how well the visual and textual representations of an image match.
Using SaD and PaD, the researchers reveal several insights about existing generative models:
- Projected GAN generates implausible attribute relationships, such as a baby with a beard, despite having competitive scores on existing metrics.
- Diffusion models struggle to capture diverse colors in the datasets.
- The larger sampling timesteps of latent diffusion models generate smaller objects, including earrings and necklaces.
- Stable Diffusion v1.5 better captures the attributes than v2.1.
Critical Analysis
The researchers have proposed a novel and promising approach to evaluating generative models that goes beyond traditional metrics like image quality and diversity. By focusing on the distribution of attribute strengths, their new metrics provide valuable insights into the specific strengths and weaknesses of different models.
However, one potential limitation of the approach is the reliance on the Heterogeneous CLIPScore (HCS) to measure attribute strengths. While CLIP-based methods have shown promise, they may still have biases or limitations that could impact the reliability of the results.
Additionally, the researchers only tested their approach on a limited set of generative models. It would be interesting to see how well the SaD and PaD metrics perform when applied to a broader range of models, including those from different architectures or training approaches.
Overall, the researchers have made a valuable contribution to the field of generative model evaluation. By shifting the focus towards interpretable metrics that capture the underlying distribution of attributes, they have laid the groundwork for more insightful and actionable assessments of these powerful AI systems.
Conclusion
The researchers have proposed a new evaluation protocol that measures the divergence of generated images from the training set distribution regarding the distribution of attribute strengths. This approach, consisting of the Single-attribute Divergence (SaD) and Paired-attribute Divergence (PaD) metrics, along with the Heterogeneous CLIPScore (HCS) for measuring attribute strengths, provides a more interpretable and comprehensive way to assess the performance of generative models.
By applying these new metrics, the researchers have uncovered interesting insights about the strengths and weaknesses of various generative models, such as the ability to capture diverse colors and the generation of plausible attribute relationships. This lays a foundation for more explainable evaluations of generative models, which can inform the development of improved AI systems in the future.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🎲
0
Attribute Based Interpretable Evaluation Metrics for Generative Models
Dongkyun Kim, Mingi Kwon, Youngjung Uh
When the training dataset comprises a 1:1 proportion of dogs to cats, a generative model that produces 1:1 dogs and cats better resembles the training species distribution than another model with 3:1 dogs and cats. Can we capture this phenomenon using existing metrics? Unfortunately, we cannot, because these metrics do not provide any interpretability beyond diversity. In this context, we propose a new evaluation protocol that measures the divergence of a set of generated images from the training set regarding the distribution of attribute strengths as follows. Single-attribute Divergence (SaD) measures the divergence regarding PDFs of a single attribute. Paired-attribute Divergence (PaD) measures the divergence regarding joint PDFs of a pair of attributes. They provide which attributes the models struggle. For measuring the attribute strengths of an image, we propose Heterogeneous CLIPScore (HCS) which measures the cosine similarity between image and text vectors with heterogeneous initial points. With SaD and PaD, we reveal the following about existing generative models. ProjectedGAN generates implausible attribute relationships such as a baby with a beard even though it has competitive scores of existing metrics. Diffusion models struggle to capture diverse colors in the datasets. The larger sampling timesteps of latent diffusion model generate the more minor objects including earrings and necklaces. Stable Diffusion v1.5 better captures the attributes than v2.1. Our metrics lay a foundation for explainable evaluations of generative models.
Read more7/18/2024
📊
0
Synthetic Tabular Data Validation: A Divergence-Based Approach
Patricia A. Apell'aniz, Ana Jim'enez, Borja Arroyo Galende, Juan Parras, Santiago Zazo
The ever-increasing use of generative models in various fields where tabular data is used highlights the need for robust and standardized validation metrics to assess the similarity between real and synthetic data. Current methods lack a unified framework and rely on diverse and often inconclusive statistical measures. Divergences, which quantify discrepancies between data distributions, offer a promising avenue for validation. However, traditional approaches calculate divergences independently for each feature due to the complexity of joint distribution modeling. This paper addresses this challenge by proposing a novel approach that uses divergence estimation to overcome the limitations of marginal comparisons. Our core contribution lies in applying a divergence estimator to build a validation metric considering the joint distribution of real and synthetic data. We leverage a probabilistic classifier to approximate the density ratio between datasets, allowing the capture of complex relationships. We specifically calculate two divergences: the well-known Kullback-Leibler (KL) divergence and the Jensen-Shannon (JS) divergence. KL divergence offers an established use in the field, while JS divergence is symmetric and bounded, providing a reliable metric. The efficacy of this approach is demonstrated through a series of experiments with varying distribution complexities. The initial phase involves comparing estimated divergences with analytical solutions for simple distributions, setting a benchmark for accuracy. Finally, we validate our method on a real-world dataset and its corresponding synthetic counterpart, showcasing its effectiveness in practical applications. This research offers a significant contribution with applicability beyond tabular data and the potential to improve synthetic data validation in various fields.
Read more8/1/2024
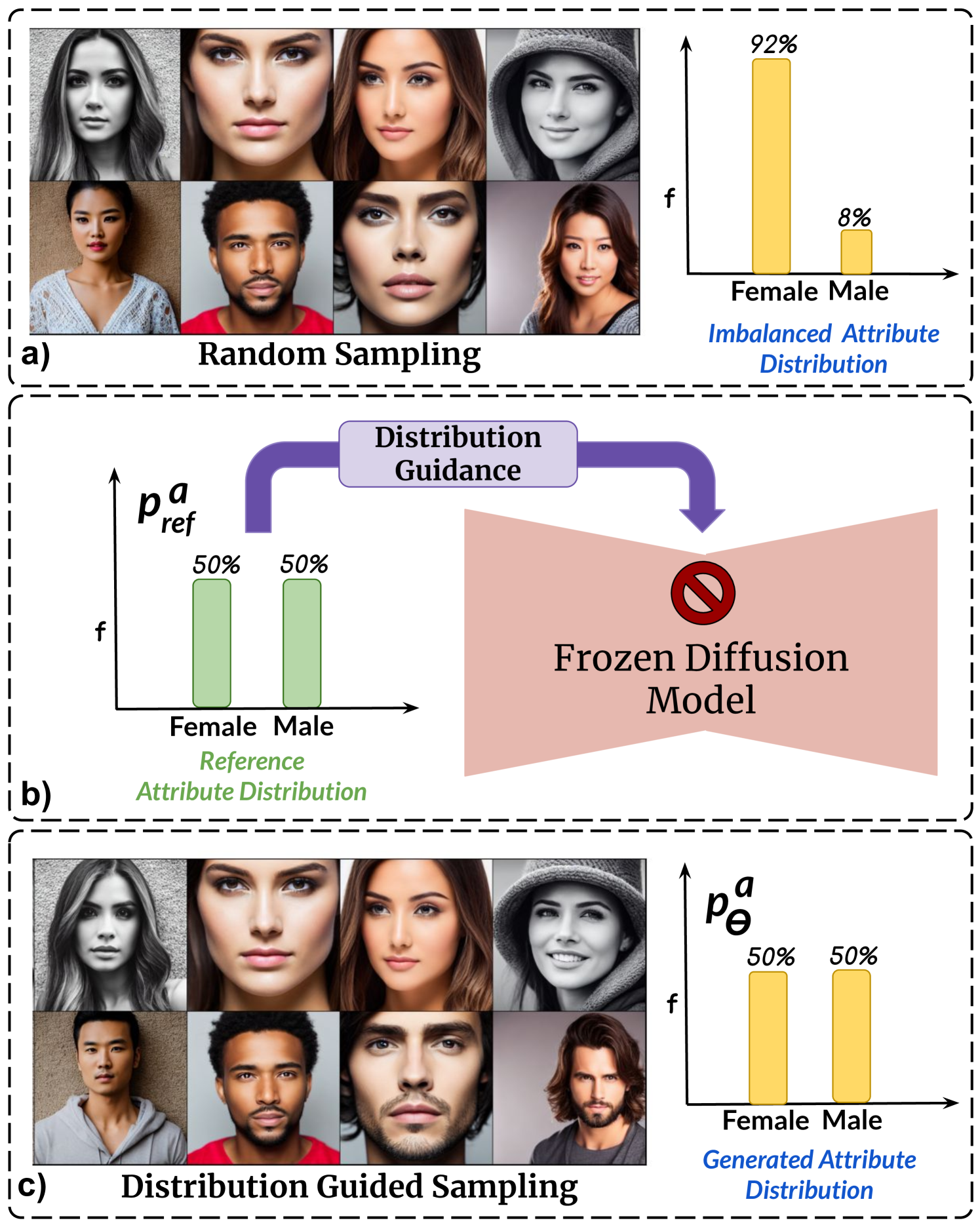
0
Balancing Act: Distribution-Guided Debiasing in Diffusion Models
Rishubh Parihar, Abhijnya Bhat, Abhipsa Basu, Saswat Mallick, Jogendra Nath Kundu, R. Venkatesh Babu
Diffusion Models (DMs) have emerged as powerful generative models with unprecedented image generation capability. These models are widely used for data augmentation and creative applications. However, DMs reflect the biases present in the training datasets. This is especially concerning in the context of faces, where the DM prefers one demographic subgroup vs others (eg. female vs male). In this work, we present a method for debiasing DMs without relying on additional data or model retraining. Specifically, we propose Distribution Guidance, which enforces the generated images to follow the prescribed attribute distribution. To realize this, we build on the key insight that the latent features of denoising UNet hold rich demographic semantics, and the same can be leveraged to guide debiased generation. We train Attribute Distribution Predictor (ADP) - a small mlp that maps the latent features to the distribution of attributes. ADP is trained with pseudo labels generated from existing attribute classifiers. The proposed Distribution Guidance with ADP enables us to do fair generation. Our method reduces bias across single/multiple attributes and outperforms the baseline by a significant margin for unconditional and text-conditional diffusion models. Further, we present a downstream task of training a fair attribute classifier by rebalancing the training set with our generated data.
Read more5/30/2024
📈
0
Semantic Approach to Quantifying the Consistency of Diffusion Model Image Generation
Brinnae Bent
In this study, we identify the need for an interpretable, quantitative score of the repeatability, or consistency, of image generation in diffusion models. We propose a semantic approach, using a pairwise mean CLIP (Contrastive Language-Image Pretraining) score as our semantic consistency score. We applied this metric to compare two state-of-the-art open-source image generation diffusion models, Stable Diffusion XL and PixArt-{alpha}, and we found statistically significant differences between the semantic consistency scores for the models. Agreement between the Semantic Consistency Score selected model and aggregated human annotations was 94%. We also explored the consistency of SDXL and a LoRA-fine-tuned version of SDXL and found that the fine-tuned model had significantly higher semantic consistency in generated images. The Semantic Consistency Score proposed here offers a measure of image generation alignment, facilitating the evaluation of model architectures for specific tasks and aiding in informed decision-making regarding model selection.
Read more4/16/2024