Audio-visual cross-modality knowledge transfer for machine learning-based in-situ monitoring in laser additive manufacturing

0
🔄
Sign in to get full access
Overview
- Various machine learning (ML) systems have been developed to detect defects in laser additive manufacturing (LAM) processes.
- Multimodal fusion, which combines data from multiple sensors, can improve in-situ monitoring performance.
- Multimodal fusion, however, increases hardware, computational, and operational costs.
- This paper proposes a cross-modality knowledge transfer (CMKT) methodology to address these limitations.
Plain English Explanation
The paper looks at how machine learning can be used to monitor and detect issues during the laser additive manufacturing (LAM) process. LAM is a type of 3D printing that uses lasers to fuse materials together. Defects or problems that occur during the LAM process can be difficult to detect, so the researchers developed ML-based systems to help.
One approach, called multimodal fusion, combines data from multiple sensors (like visual and audio) to get a more complete picture and improve monitoring performance. However, using multiple sensors increases the cost and complexity of the system.
To address this, the researchers propose a cross-modality knowledge transfer (CMKT) method. CMKT allows the system to learn from one type of sensor data (like visual) and then apply that knowledge to make predictions using just a single sensor (like just the audio data). This reduces the number of sensors required without sacrificing much accuracy.
The paper describes three different CMKT methods:
- Semantic alignment: Aligns the extracted features from different sensor modalities so they can be more easily shared between them.
- Fully supervised mapping: Directly learns how to derive features from one modality based on the other.
- Semi-supervised mapping: Does the mapping in a semi-supervised way, using both labeled and unlabeled data.
The researchers tested these CMKT methods on the LAM defect detection problem and found the semantic alignment approach achieved comparable accuracy to the full multimodal fusion approach, but with just a single sensor.
Technical Explanation
The paper proposes a cross-modality knowledge transfer (CMKT) methodology to address the high hardware, computational, and operational costs associated with multimodal fusion approaches for in-situ LAM monitoring.
The three CMKT methods introduced are:
-
Semantic Alignment: This establishes a shared encoded space between modalities to facilitate knowledge transfer. It uses a semantic alignment loss to align the distributions of the same classes (e.g., visual defective and audio defective) and a separation loss to separate the distributions of different classes (e.g., visual defective and audio defect-free).
-
Fully Supervised Mapping: This transfers knowledge by directly learning to derive the features of one modality from the other modality using supervised learning.
-
Semi-Supervised Mapping: This also transfers knowledge by learning to map between modalities, but uses both labeled and unlabeled data in a semi-supervised approach.
The researchers implemented and evaluated these CMKT methods in an LAM in-situ anomaly detection case study. They found that the semantic alignment method achieved 98.4% accuracy while removing the audio modality during the prediction phase, which was comparable to the 98.2% accuracy of the full multimodal fusion approach.
Critical Analysis
The paper presents a novel and promising approach to address the high costs associated with multimodal fusion for in-situ monitoring of LAM processes. The CMKT methods allow for knowledge transfer between modalities, enabling the use of a single sensor during prediction without significantly sacrificing accuracy.
However, the paper does not provide much discussion of the limitations or potential drawbacks of the CMKT approach. For example, it's unclear how the performance of the CMKT methods would scale to larger or more complex monitoring tasks, or how they would handle noisy or unreliable sensor data.
Additionally, the paper focuses solely on the LAM in-situ anomaly detection use case. Further research would be needed to assess the generalizability of the CMKT methods to other multimodal learning problems in manufacturing or other domains.
Overall, the paper makes a valuable contribution, but additional analysis of the approach's limitations and broader applicability would strengthen the work.
Conclusion
This paper presents a novel cross-modality knowledge transfer (CMKT) methodology to address the high costs associated with multimodal fusion for in-situ monitoring of laser additive manufacturing (LAM) processes. The CMKT approach allows for knowledge transfer between sensor modalities, enabling the use of a single sensor during prediction without significantly sacrificing accuracy.
The researchers evaluated three CMKT methods - semantic alignment, fully supervised mapping, and semi-supervised mapping - in an LAM in-situ anomaly detection case study. The semantic alignment method achieved comparable performance to the full multimodal fusion approach while removing the need for the additional sensor.
This work demonstrates the potential of CMKT to unlock the benefits of multimodal monitoring while reducing hardware, computational, and operational costs. Further research is needed to explore the broader applicability of this approach and address any limitations, but the results presented in this paper are a promising step forward.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔄
0
Audio-visual cross-modality knowledge transfer for machine learning-based in-situ monitoring in laser additive manufacturing
Jiarui Xie, Mutahar Safdar, Lequn Chen, Seung Ki Moon, Yaoyao Fiona Zhao
Various machine learning (ML)-based in-situ monitoring systems have been developed to detect laser additive manufacturing (LAM) process anomalies and defects. Multimodal fusion can improve in-situ monitoring performance by acquiring and integrating data from multiple modalities, including visual and audio data. However, multimodal fusion employs multiple sensors of different types, which leads to higher hardware, computational, and operational costs. This paper proposes a cross-modality knowledge transfer (CMKT) methodology that transfers knowledge from a source to a target modality for LAM in-situ monitoring. CMKT enhances the usefulness of the features extracted from the target modality during the training phase and removes the sensors of the source modality during the prediction phase. This paper proposes three CMKT methods: semantic alignment, fully supervised mapping, and semi-supervised mapping. Semantic alignment establishes a shared encoded space between modalities to facilitate knowledge transfer. It utilizes a semantic alignment loss to align the distributions of the same classes (e.g., visual defective and audio defective classes) and a separation loss to separate the distributions of different classes (e.g., visual defective and audio defect-free classes). The two mapping methods transfer knowledge by deriving the features of one modality from the other modality using fully supervised and semi-supervised learning. The proposed CMKT methods were implemented and compared with multimodal audio-visual fusion in an LAM in-situ anomaly detection case study. The semantic alignment method achieves a 98.4% accuracy while removing the audio modality during the prediction phase, which is comparable to the accuracy of multimodal fusion (98.2%).
Read more8/13/2024
0
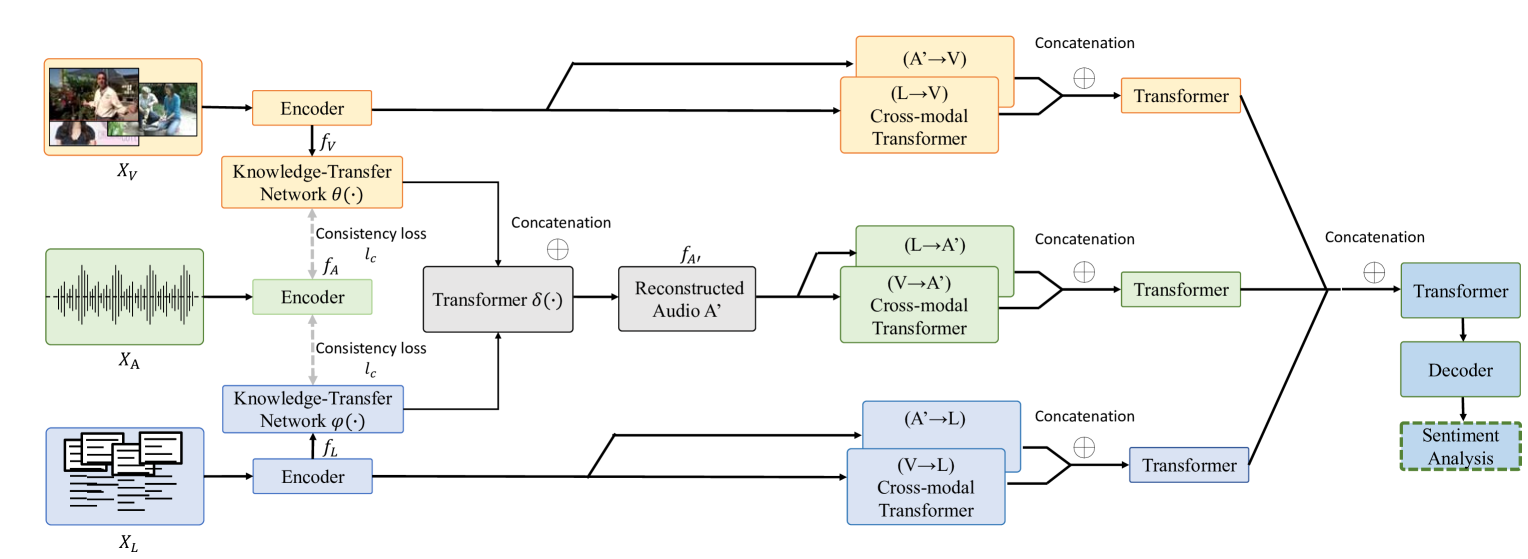
Multimodal Sentiment Analysis with Missing Modality: A Knowledge-Transfer Approach
Weide Liu, Huijing Zhan, Hao Chen, Fengmao Lv
Multimodal sentiment analysis aims to identify the emotions expressed by individuals through visual, language, and acoustic cues. However, most of the existing research efforts assume that all modalities are available during both training and testing, making their algorithms susceptible to the missing modality scenario. In this paper, we propose a novel knowledge-transfer network to translate between different modalities to reconstruct the missing audio modalities. Moreover, we develop a cross-modality attention mechanism to retain the maximal information of the reconstructed and observed modalities for sentiment prediction. Extensive experiments on three publicly available datasets demonstrate significant improvements over baselines and achieve comparable results to the previous methods with complete multi-modality supervision.
Read more7/12/2024
❗
0
Multimodal Industrial Anomaly Detection by Crossmodal Feature Mapping
Alex Costanzino, Pierluigi Zama Ramirez, Giuseppe Lisanti, Luigi Di Stefano
The paper explores the industrial multimodal Anomaly Detection (AD) task, which exploits point clouds and RGB images to localize anomalies. We introduce a novel light and fast framework that learns to map features from one modality to the other on nominal samples. At test time, anomalies are detected by pinpointing inconsistencies between observed and mapped features. Extensive experiments show that our approach achieves state-of-the-art detection and segmentation performance in both the standard and few-shot settings on the MVTec 3D-AD dataset while achieving faster inference and occupying less memory than previous multimodal AD methods. Moreover, we propose a layer-pruning technique to improve memory and time efficiency with a marginal sacrifice in performance.
Read more7/9/2024

0
Audio-Guided Fusion Techniques for Multimodal Emotion Analysis
Pujin Shi, Fei Gao
In this paper, we propose a solution for the semi-supervised learning track (MER-SEMI) in MER2024. First, in order to enhance the performance of the feature extractor on sentiment classification tasks,we fine-tuned video and text feature extractors, specifically CLIP-vit-large and Baichuan-13B, using labeled data. This approach effectively preserves the original emotional information conveyed in the videos. Second, we propose an Audio-Guided Transformer (AGT) fusion mechanism, which leverages the robustness of Hubert-large, showing superior effectiveness in fusing both inter-channel and intra-channel information. Third, To enhance the accuracy of the model, we iteratively apply self-supervised learning by using high-confidence unlabeled data as pseudo-labels. Finally, through black-box probing, we discovered an imbalanced data distribution between the training and test sets. Therefore, We adopt a prior-knowledge-based voting mechanism. The results demonstrate the effectiveness of our strategy, ultimately earning us third place in the MER-SEMI track.
Read more9/10/2024