Automatic Generation and Evaluation of Reading Comprehension Test Items with Large Language Models
2404.07720
0
0
Abstract
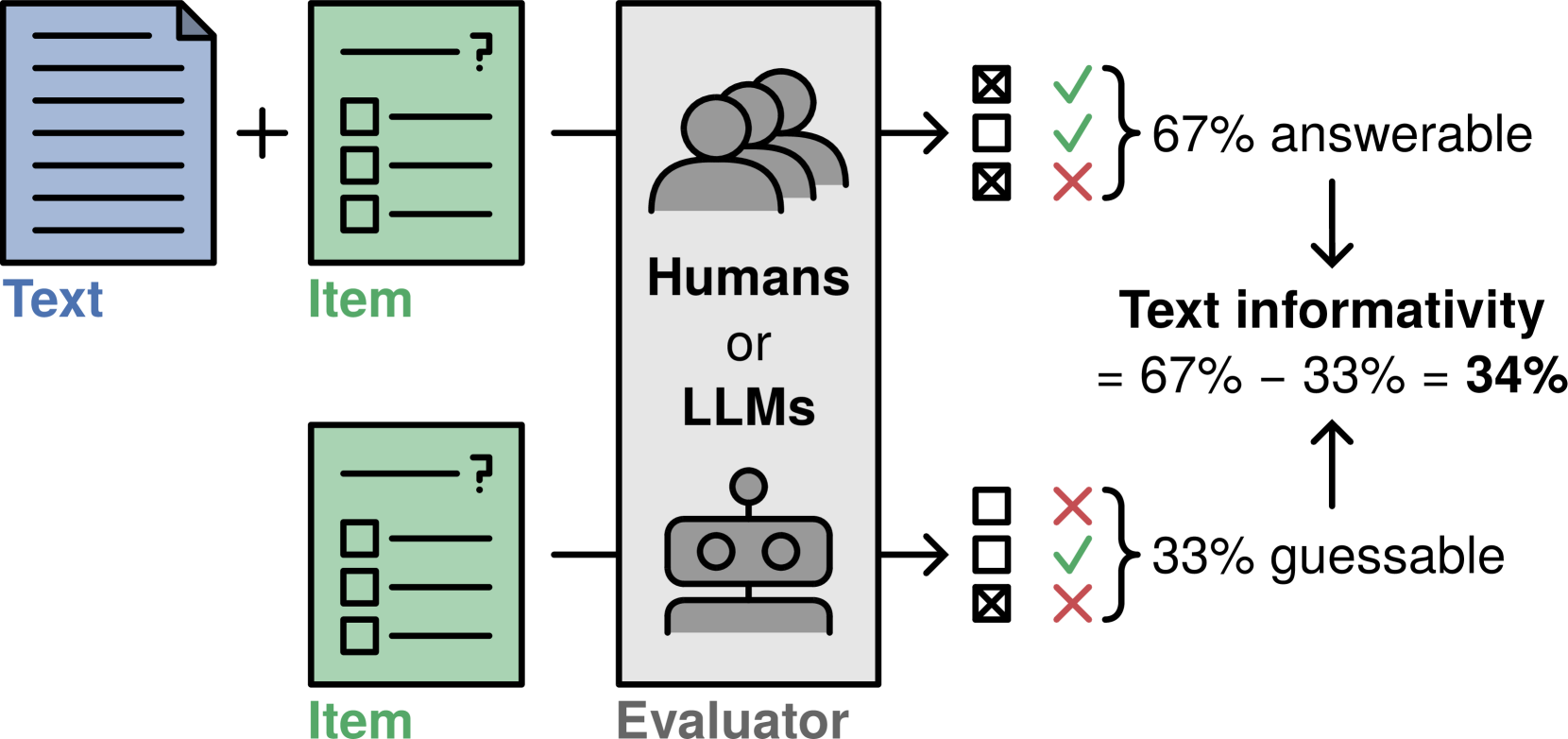
Reading comprehension tests are used in a variety of applications, reaching from education to assessing the comprehensibility of simplified texts. However, creating such tests manually and ensuring their quality is difficult and time-consuming. In this paper, we explore how large language models (LLMs) can be used to generate and evaluate multiple-choice reading comprehension items. To this end, we compiled a dataset of German reading comprehension items and developed a new protocol for human and automatic evaluation, including a metric we call text informativity, which is based on guessability and answerability. We then used this protocol and the dataset to evaluate the quality of items generated by Llama 2 and GPT-4. Our results suggest that both models are capable of generating items of acceptable quality in a zero-shot setting, but GPT-4 clearly outperforms Llama 2. We also show that LLMs can be used for automatic evaluation by eliciting item reponses from them. In this scenario, evaluation results with GPT-4 were the most similar to human annotators. Overall, zero-shot generation with LLMs is a promising approach for generating and evaluating reading comprehension test items, in particular for languages without large amounts of available data.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper explores the use of large language models (LLMs) to automatically generate and evaluate reading comprehension test items.
- The researchers developed a system that can generate multiple-choice questions and answers based on given passages, and then evaluate the quality of those test items.
- The goal is to streamline the process of creating high-quality reading comprehension assessments, which is typically a labor-intensive task.
Plain English Explanation
The paper investigates how powerful language AI models, known as large language models (LLMs), can be used to automatically create and assess reading comprehension test questions. Reading comprehension tests are an important way to evaluate how well people can understand and analyze written material. However, developing these tests is often a time-consuming and difficult task for human experts.
The researchers developed a system that can automatically generate multiple-choice questions and answers based on given passages of text. The system uses advanced language AI models to analyze the content and structure of the passages, and then generate relevant questions and answer choices. The system can also evaluate the quality of the generated test items, assessing factors like difficulty level, relevance, and clarity.
The key idea is to leverage the impressive language understanding capabilities of LLMs to streamline the process of creating high-quality reading comprehension assessments. This could save time and resources for educators and researchers, while also potentially improving the consistency and fairness of these important tests.
Technical Explanation
The paper presents a system for the automatic generation and evaluation of reading comprehension test items using large language models (LLMs). The researchers developed a pipeline that takes in a passage of text and generates multiple-choice questions and answers based on the content.
The generation process involves several steps:
- Passage Analysis: The system analyzes the given passage using LLMs to understand the key concepts, important details, and overall structure of the text.
- Question Generation: Based on the passage analysis, the system generates candidate questions that target different types of comprehension, such as literal understanding, inferencing, and reasoning.
- Answer Generation: For each question, the system generates multiple answer choices, including the correct answer and plausible distractors.
- Quality Evaluation: The system then evaluates the generated test items, assessing factors like question difficulty, answer relevance, and overall clarity.
The researchers tested their system on various datasets of reading comprehension passages and found that the automatically generated test items were comparable in quality to those created by human experts. This suggests that LLMs can be effectively leveraged for the task of reading comprehension assessment, potentially reducing the time and effort required for test development.
Critical Analysis
The paper presents a promising approach for automating the creation and evaluation of reading comprehension test items. However, it also acknowledges several limitations and areas for further research:
-
Generalization Across Domains: The current system was tested on a limited set of passages, primarily from the educational domain. Further research is needed to assess how well the approach generalizes to other genres and subject areas.
-
Contextual Understanding: While the LLMs used in the system have impressive language understanding capabilities, they may still struggle with some aspects of contextual reasoning and commonsense understanding required for high-quality reading comprehension assessments.
-
Human Evaluation: The paper primarily relies on automated metrics to evaluate the quality of the generated test items. Incorporating more human-based evaluations could provide additional insights and inform further improvements to the system.
-
Ethical Considerations: As with any AI-powered system, there are potential concerns around bias, fairness, and transparency that should be carefully considered, especially when deploying such a system in high-stakes educational contexts.
Overall, the research presented in this paper represents an important step towards leveraging large language models for the automation of educational assessments. However, continued development and rigorous evaluation will be crucial to ensure the system's robustness and suitability for real-world application.
Conclusion
This paper demonstrates the potential of large language models to streamline the process of creating and evaluating reading comprehension test items. By automating these tasks, the system has the ability to save time and resources for educators and researchers, while also potentially improving the consistency and fairness of these important assessments.
While the current approach shows promising results, further research is needed to address the limitations and explore the broader application of language models in materials science and other domains. As AI systems become increasingly capable, leveraging their strengths to enhance and augment human-driven educational practices could be a valuable direction for future work.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤖
Can LLMs Grade Short-Answer Reading Comprehension Questions : An Empirical Study with a Novel Dataset
Owen Henkel, Libby Hills, Bill Roberts, Joshua McGrane
0
0
Open-ended questions, which require students to produce multi-word, nontrivial responses, are a popular tool for formative assessment as they provide more specific insights into what students do and don't know. However, grading open-ended questions can be time-consuming leading teachers to resort to simpler question formats or conduct fewer formative assessments. While there has been a longstanding interest in automating of short-answer grading (ASAG), but previous approaches have been technically complex, limiting their use in formative assessment contexts. The newest generation of Large Language Models (LLMs) potentially makes grading short answer questions more feasible. This paper investigates the potential for the newest version of LLMs to be used in ASAG, specifically in the grading of short answer questions for formative assessments, in two ways. First, it introduces a novel dataset of short answer reading comprehension questions, drawn from a set of reading assessments conducted with over 150 students in Ghana. This dataset allows for the evaluation of LLMs in a new context, as they are predominantly designed and trained on data from high-income North American countries. Second, the paper empirically evaluates how well various configurations of generative LLMs grade student short answer responses compared to expert human raters. The findings show that GPT-4, with minimal prompt engineering, performed extremely well on grading the novel dataset (QWK 0.92, F1 0.89), reaching near parity with expert human raters. To our knowledge this work is the first to empirically evaluate the performance of generative LLMs on short answer reading comprehension questions using real student data, with low technical hurdles to attaining this performance. These findings suggest that generative LLMs could be used to grade formative literacy assessment tasks.
5/7/2024
💬
Can Large Language Models Make the Grade? An Empirical Study Evaluating LLMs Ability to Mark Short Answer Questions in K-12 Education
Owen Henkel, Adam Boxer, Libby Hills, Bill Roberts
0
0
This paper presents reports on a series of experiments with a novel dataset evaluating how well Large Language Models (LLMs) can mark (i.e. grade) open text responses to short answer questions, Specifically, we explore how well different combinations of GPT version and prompt engineering strategies performed at marking real student answers to short answer across different domain areas (Science and History) and grade-levels (spanning ages 5-16) using a new, never-used-before dataset from Carousel, a quizzing platform. We found that GPT-4, with basic few-shot prompting performed well (Kappa, 0.70) and, importantly, very close to human-level performance (0.75). This research builds on prior findings that GPT-4 could reliably score short answer reading comprehension questions at a performance-level very close to that of expert human raters. The proximity to human-level performance, across a variety of subjects and grade levels suggests that LLMs could be a valuable tool for supporting low-stakes formative assessment tasks in K-12 education and has important implications for real-world education delivery.
5/7/2024
🏋️
Evaluating Students' Open-ended Written Responses with LLMs: Using the RAG Framework for GPT-3.5, GPT-4, Claude-3, and Mistral-Large
Jussi S. Jauhiainen, Agust'in Garagorry Guerra
0
0
Evaluating open-ended written examination responses from students is an essential yet time-intensive task for educators, requiring a high degree of effort, consistency, and precision. Recent developments in Large Language Models (LLMs) present a promising opportunity to balance the need for thorough evaluation with efficient use of educators' time. In our study, we explore the effectiveness of LLMs ChatGPT-3.5, ChatGPT-4, Claude-3, and Mistral-Large in assessing university students' open-ended answers to questions made about reference material they have studied. Each model was instructed to evaluate 54 answers repeatedly under two conditions: 10 times (10-shot) with a temperature setting of 0.0 and 10 times with a temperature of 0.5, expecting a total of 1,080 evaluations per model and 4,320 evaluations across all models. The RAG (Retrieval Augmented Generation) framework was used as the framework to make the LLMs to process the evaluation of the answers. As of spring 2024, our analysis revealed notable variations in consistency and the grading outcomes provided by studied LLMs. There is a need to comprehend strengths and weaknesses of LLMs in educational settings for evaluating open-ended written responses. Further comparative research is essential to determine the accuracy and cost-effectiveness of using LLMs for educational assessments.
5/10/2024
UnibucLLM: Harnessing LLMs for Automated Prediction of Item Difficulty and Response Time for Multiple-Choice Questions
Ana-Cristina Rogoz, Radu Tudor Ionescu
0
0
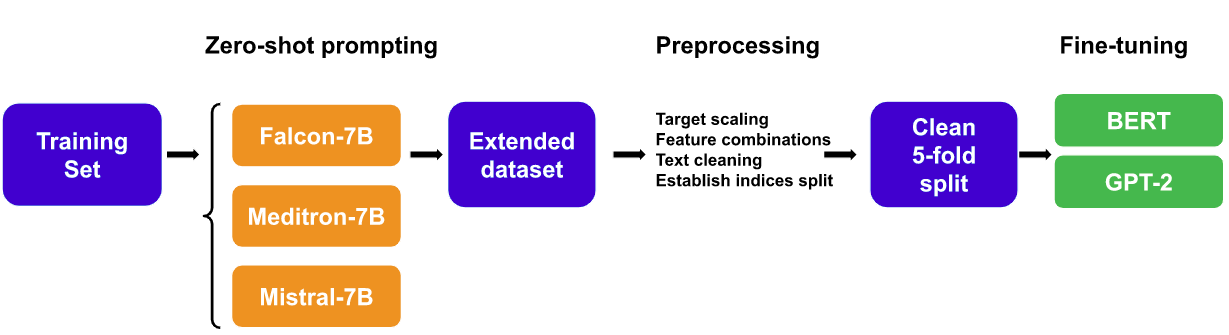
This work explores a novel data augmentation method based on Large Language Models (LLMs) for predicting item difficulty and response time of retired USMLE Multiple-Choice Questions (MCQs) in the BEA 2024 Shared Task. Our approach is based on augmenting the dataset with answers from zero-shot LLMs (Falcon, Meditron, Mistral) and employing transformer-based models based on six alternative feature combinations. The results suggest that predicting the difficulty of questions is more challenging. Notably, our top performing methods consistently include the question text, and benefit from the variability of LLM answers, highlighting the potential of LLMs for improving automated assessment in medical licensing exams. We make our code available https://github.com/ana-rogoz/BEA-2024.
4/23/2024