LLMs' Reading Comprehension Is Affected by Parametric Knowledge and Struggles with Hypothetical Statements

0

Sign in to get full access
Overview
- This research paper examines how large language models (LLMs) perform on reading comprehension tasks, and how their performance is affected by their parametric knowledge and ability to handle hypothetical statements.
- The study finds that LLMs struggle with certain types of reasoning, such as understanding hypotheticals, and that their performance is heavily influenced by the knowledge encoded in their parameters during training.
- The paper provides insights into the limitations of current LLMs and suggests areas for further research to improve their reasoning capabilities.
Plain English Explanation
Large language models (LLMs) are artificial intelligence systems that can understand and generate human-like text. Researchers wanted to see how well these models can comprehend and answer questions about what they read. They found that the models' performance is heavily influenced by the specific knowledge and information that was used to train them.
For example, the models were good at answering questions that involved factual information they had learned during training. But they struggled with questions that required more abstract reasoning, like understanding hypothetical scenarios. The researchers think this is because the models don't have a deep understanding of the meaning behind the text, and instead rely on patterns in the data they were trained on.
This suggests that current LLMs have limitations when it comes to truly understanding language and reasoning about complex topics. To improve their performance, researchers may need to find new ways to train these models that go beyond just memorizing data. They could try teaching the models to better grasp the underlying concepts and logical reasoning behind the text.
Technical Explanation
The paper examines the reading comprehension capabilities of large language models (LLMs) and how these are affected by the models' parametric knowledge and their ability to handle hypothetical statements.
The authors conducted experiments using several popular LLMs, including GPT-3, T5, and BERT, on a range of reading comprehension tasks. They found that the models' performance was heavily influenced by the specific knowledge encoded in their parameters during training. The models tended to excel at questions that aligned with their parametric knowledge, but struggled with questions that required more abstract reasoning, such as understanding hypotheticals.
This suggests that current LLMs rely more on their prior knowledge than on truly understanding the meaning and logical structure of the text. The authors argue that this limitation could prevent LLMs from reasoning about interventional scenarios or customizing their responses based on the specific context.
Critical Analysis
The paper provides valuable insights into the current limitations of large language models and highlights the need for further research to improve their reasoning capabilities. The authors acknowledge that the models' performance is heavily influenced by their parametric knowledge, which could lead to counter-intuitive behavior in certain situations.
One potential concern is that the study focused on a limited set of reading comprehension tasks and LLMs. It would be helpful to see the same analysis applied to a wider range of models and task types to better understand the generalizability of the findings.
Additionally, the paper does not delve into the specific mechanisms or architectural choices that may contribute to the LLMs' struggles with hypothetical reasoning. Further research could explore how the models' design and training process impact their ability to engage in more abstract and logical forms of reasoning.
Conclusion
This research paper sheds light on the limitations of current large language models when it comes to reading comprehension and reasoning about complex, hypothetical scenarios. The findings suggest that LLMs' performance is heavily influenced by the specific knowledge encoded in their parameters during training, rather than a deep understanding of the underlying meaning and logic of the text.
These insights highlight the need for continued advancements in language model architecture and training to improve their reasoning capabilities. By addressing these limitations, researchers may be able to develop LLMs that can more effectively understand and engage with the nuances of human language and thought.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
LLMs' Reading Comprehension Is Affected by Parametric Knowledge and Struggles with Hypothetical Statements
Victoria Basmov, Yoav Goldberg, Reut Tsarfaty
The task of reading comprehension (RC), often implemented as context-based question answering (QA), provides a primary means to assess language models' natural language understanding (NLU) capabilities. Yet, when applied to large language models (LLMs) with extensive built-in world knowledge, this method can be deceptive. If the context aligns with the LLMs' internal knowledge, it is hard to discern whether the models' answers stem from context comprehension or from LLMs' internal information. Conversely, using data that conflicts with the models' knowledge creates erroneous trends which distort the results. To address this issue, we suggest to use RC on imaginary data, based on fictitious facts and entities. This task is entirely independent of the models' world knowledge, enabling us to evaluate LLMs' linguistic abilities without the interference of parametric knowledge. Testing ChatGPT, GPT-4, LLaMA 2 and Mixtral on such imaginary data, we uncover a class of linguistic phenomena posing a challenge to current LLMs, involving thinking in terms of alternative, hypothetical scenarios. While all the models handle simple affirmative and negative contexts with high accuracy, they are much more prone to error when dealing with modal and conditional contexts. Crucially, these phenomena also trigger the LLMs' vulnerability to knowledge-conflicts again. In particular, while some models prove virtually unaffected by knowledge conflicts in affirmative and negative contexts, when faced with more semantically involved modal and conditional environments, they often fail to separate the text from their internal knowledge.
Read more4/10/2024
0
When Context Leads but Parametric Memory Follows in Large Language Models
Yufei Tao, Adam Hiatt, Erik Haake, Antonie J. Jetter, Ameeta Agrawal
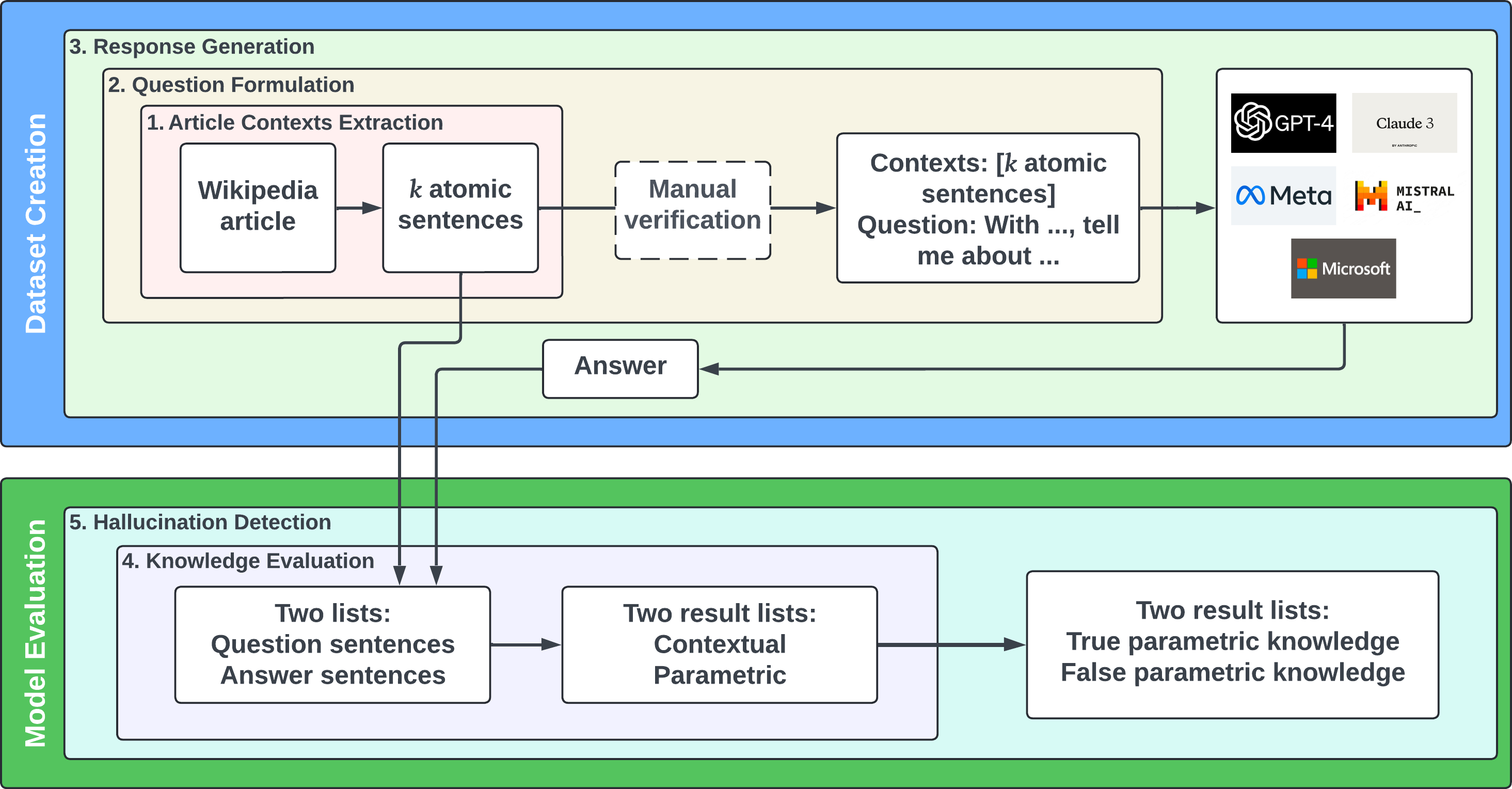
Large language models (LLMs) have demonstrated remarkable progress in leveraging diverse knowledge sources. This study investigates how nine widely used LLMs allocate knowledge between local context and global parameters when answering open-ended questions in knowledge-consistent scenarios. We introduce a novel dataset, WikiAtomic, and systematically vary context sizes to analyze how LLMs prioritize and utilize the provided information and their parametric knowledge in knowledge-consistent scenarios. Additionally, we also study their tendency to hallucinate under varying context sizes. Our findings reveal consistent patterns across models, including a consistent reliance on both contextual (around 70%) and parametric (around 30%) knowledge, and a decrease in hallucinations with increasing context. These insights highlight the importance of more effective context organization and developing models that use input more deterministically for robust performance.
Read more9/24/2024

0
Knowledge Conflicts for LLMs: A Survey
Rongwu Xu, Zehan Qi, Zhijiang Guo, Cunxiang Wang, Hongru Wang, Yue Zhang, Wei Xu
This survey provides an in-depth analysis of knowledge conflicts for large language models (LLMs), highlighting the complex challenges they encounter when blending contextual and parametric knowledge. Our focus is on three categories of knowledge conflicts: context-memory, inter-context, and intra-memory conflict. These conflicts can significantly impact the trustworthiness and performance of LLMs, especially in real-world applications where noise and misinformation are common. By categorizing these conflicts, exploring the causes, examining the behaviors of LLMs under such conflicts, and reviewing available solutions, this survey aims to shed light on strategies for improving the robustness of LLMs, thereby serving as a valuable resource for advancing research in this evolving area.
Read more6/26/2024

0
From Internal Conflict to Contextual Adaptation of Language Models
Sara Vera Marjanovi'c, Haeun Yu, Pepa Atanasova, Maria Maistro, Christina Lioma, Isabelle Augenstein
Knowledge-intensive language understanding tasks require Language Models (LMs) to integrate relevant context, mitigating their inherent weaknesses, such as incomplete or outdated knowledge. Nevertheless, studies indicate that LMs often ignore the provided context as it can conflict with the pre-existing LM's memory learned during pre-training. Moreover, conflicting knowledge can already be present in the LM's parameters, termed intra-memory conflict. Existing works have studied the two types of knowledge conflicts only in isolation. We conjecture that the (degree of) intra-memory conflicts can in turn affect LM's handling of context-memory conflicts. To study this, we introduce the DYNAMICQA dataset, which includes facts with a temporal dynamic nature where a fact can change with a varying time frequency and disputable dynamic facts, which can change depending on the viewpoint. DYNAMICQA is the first to include real-world knowledge conflicts and provide context to study the link between the different types of knowledge conflicts. With the proposed dataset, we assess the use of uncertainty for measuring the intra-memory conflict and introduce a novel Coherent Persuasion (CP) score to evaluate the context's ability to sway LM's semantic output. Our extensive experiments reveal that static facts, which are unlikely to change, are more easily updated with additional context, relative to temporal and disputable facts.
Read more7/25/2024