Automatic Jailbreaking of the Text-to-Image Generative AI Systems

0

Sign in to get full access
Overview
- This paper presents a novel technique for "jailbreaking" text-to-image generative AI systems, which are models that can generate images from text prompts.
- The proposed approach, called "Automatic Jailbreaking of the Text-to-Image Generative AI Systems," aims to bypass the safety constraints and content restrictions typically imposed on these models.
- The researchers demonstrate how their method can be used to generate a wide range of potentially unsafe or inappropriate content, highlighting the need for more robust safety measures in text-to-image generation systems.
Plain English Explanation
The paper discusses a way to bypass the controls and restrictions that are typically built into text-to-image AI systems. These AI models are designed to generate images based on text prompts, but they often have safeguards in place to prevent them from creating inappropriate or harmful content.
The researchers have developed a technique that can "jailbreak" these systems, allowing them to generate a much wider range of images, including some that may be unsafe or undesirable. This highlights the need for more robust safety measures to be implemented in these AI models, to ensure they cannot be easily exploited to create problematic content.
The paper serves as a warning that even with the current safety measures in place, there are ways for determined users to work around them and generate potentially harmful or inappropriate images. As text-to-image AI systems become more advanced and widely used, ensuring their safety and responsible development will be an important challenge for the field to address.
Technical Explanation
The paper presents a novel technique called "Automatic Jailbreaking of the Text-to-Image Generative AI Systems" that can bypass the safety constraints and content restrictions typically imposed on text-to-image generative models. [Link to related paper: https://aimodels.fyi/papers/arxiv/artprompt-ascii-art-based-jailbreak-attacks-against]
The researchers demonstrate how their approach can be used to generate a wide range of potentially unsafe or inappropriate content, including images that violate the models' intended use cases and safety guidelines. [Link to related paper: https://aimodels.fyi/papers/arxiv/severity-controlled-text-to-image-generative-model]
The paper highlights the need for more robust safety measures to be implemented in text-to-image generation systems, as the current approaches can be easily circumvented by determined users. [Link to related paper: https://aimodels.fyi/papers/arxiv/survey-bias-text-to-image-generation-definition]
The researchers also discuss the potential implications of their findings for the responsible development and deployment of these AI models, emphasizing the importance of addressing safety and bias concerns. [Link to related paper: https://aimodels.fyi/papers/arxiv/safegen-mitigating-unsafe-content-generation-text-to]
Critical Analysis
The paper presents a concerning demonstration of how text-to-image generative AI systems can be "jailbroken" to bypass their intended safety constraints. While the researchers' approach highlights important vulnerabilities, it also raises ethical concerns about the potential misuse of such techniques.
The paper does not provide details on the specific methods used for jailbreaking the systems, which could be seen as a limitation. Additionally, the paper does not address the potential countermeasures or mitigation strategies that could be employed to make these systems more secure and resistant to exploitation.
Furthermore, the paper does not delve into the broader societal implications of such jailbreaking techniques, such as the potential for their use in the creation and spread of disinformation, hate speech, or other harmful content. This is an area that warrants further exploration and discussion.
Despite these limitations, the paper serves as an important wake-up call for the AI research community and developers of text-to-image generation systems. It underscores the need for ongoing vigilance and the development of more robust safety measures to ensure the responsible and ethical deployment of these powerful technologies.
Conclusion
The paper "Automatic Jailbreaking of the Text-to-Image Generative AI Systems" highlights a critical vulnerability in current text-to-image generative AI systems, demonstrating how their safety constraints can be bypassed to generate a wide range of potentially unsafe or inappropriate content.
The findings presented in this paper emphasize the need for more robust safety measures and thorough testing of these AI models to mitigate the risk of misuse and unintended consequences. As text-to-image generation systems become more advanced and widely adopted, addressing these safety and security concerns will be crucial to ensure their responsible development and deployment.
The paper serves as a call to action for the AI research community and industry stakeholders to continue exploring ways to enhance the safety and security of text-to-image generative models, while also considering the broader societal implications of such technologies. Ongoing research and collaboration in this area will be essential for unlocking the full potential of these powerful AI systems while prioritizing the well-being and trust of the public.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Automatic Jailbreaking of the Text-to-Image Generative AI Systems
Minseon Kim, Hyomin Lee, Boqing Gong, Huishuai Zhang, Sung Ju Hwang
Recent AI systems have shown extremely powerful performance, even surpassing human performance, on various tasks such as information retrieval, language generation, and image generation based on large language models (LLMs). At the same time, there are diverse safety risks that can cause the generation of malicious contents by circumventing the alignment in LLMs, which are often referred to as jailbreaking. However, most of the previous works only focused on the text-based jailbreaking in LLMs, and the jailbreaking of the text-to-image (T2I) generation system has been relatively overlooked. In this paper, we first evaluate the safety of the commercial T2I generation systems, such as ChatGPT, Copilot, and Gemini, on copyright infringement with naive prompts. From this empirical study, we find that Copilot and Gemini block only 12% and 17% of the attacks with naive prompts, respectively, while ChatGPT blocks 84% of them. Then, we further propose a stronger automated jailbreaking pipeline for T2I generation systems, which produces prompts that bypass their safety guards. Our automated jailbreaking framework leverages an LLM optimizer to generate prompts to maximize degree of violation from the generated images without any weight updates or gradient computation. Surprisingly, our simple yet effective approach successfully jailbreaks the ChatGPT with 11.0% block rate, making it generate copyrighted contents in 76% of the time. Finally, we explore various defense strategies, such as post-generation filtering and machine unlearning techniques, but found that they were inadequate, which suggests the necessity of stronger defense mechanisms.
Read more5/29/2024

0
Jailbreaking Text-to-Image Models with LLM-Based Agents
Yingkai Dong, Zheng Li, Xiangtao Meng, Ning Yu, Shanqing Guo
Recent advancements have significantly improved automated task-solving capabilities using autonomous agents powered by large language models (LLMs). However, most LLM-based agents focus on dialogue, programming, or specialized domains, leaving their potential for addressing generative AI safety tasks largely unexplored. In this paper, we propose Atlas, an advanced LLM-based multi-agent framework targeting generative AI models, specifically focusing on jailbreak attacks against text-to-image (T2I) models with built-in safety filters. Atlas consists of two agents, namely the mutation agent and the selection agent, each comprising four key modules: a vision-language model (VLM) or LLM brain, planning, memory, and tool usage. The mutation agent uses its VLM brain to determine whether a prompt triggers the T2I model's safety filter. It then collaborates iteratively with the LLM brain of the selection agent to generate new candidate jailbreak prompts with the highest potential to bypass the filter. In addition to multi-agent communication, we leverage in-context learning (ICL) memory mechanisms and the chain-of-thought (COT) approach to learn from past successes and failures, thereby enhancing Atlas's performance. Our evaluation demonstrates that Atlas successfully jailbreaks several state-of-the-art T2I models equipped with multi-modal safety filters in a black-box setting. Additionally, Atlas outperforms existing methods in both query efficiency and the quality of generated images. This work convincingly demonstrates the successful application of LLM-based agents in studying the safety vulnerabilities of popular text-to-image generation models. We urge the community to consider advanced techniques like ours in response to the rapidly evolving text-to-image generation field.
Read more9/10/2024

0
RT-Attack: Jailbreaking Text-to-Image Models via Random Token
Sensen Gao, Xiaojun Jia, Yihao Huang, Ranjie Duan, Jindong Gu, Yang Liu, Qing Guo
Recently, Text-to-Image(T2I) models have achieved remarkable success in image generation and editing, yet these models still have many potential issues, particularly in generating inappropriate or Not-Safe-For-Work(NSFW) content. Strengthening attacks and uncovering such vulnerabilities can advance the development of reliable and practical T2I models. Most of the previous works treat T2I models as white-box systems, using gradient optimization to generate adversarial prompts. However, accessing the model's gradient is often impossible in real-world scenarios. Moreover, existing defense methods, those using gradient masking, are designed to prevent attackers from obtaining accurate gradient information. While some black-box jailbreak attacks have been explored, these typically rely on simply replacing sensitive words, leading to suboptimal attack performance. To address this issue, we introduce a two-stage query-based black-box attack method utilizing random search. In the first stage, we establish a preliminary prompt by maximizing the semantic similarity between the adversarial and target harmful prompts. In the second stage, we use this initial prompt to refine our approach, creating a detailed adversarial prompt aimed at jailbreaking and maximizing the similarity in image features between the images generated from this prompt and those produced by the target harmful prompt. Extensive experiments validate the effectiveness of our method in attacking the latest prompt checkers, post-hoc image checkers, securely trained T2I models, and online commercial models.
Read more8/28/2024
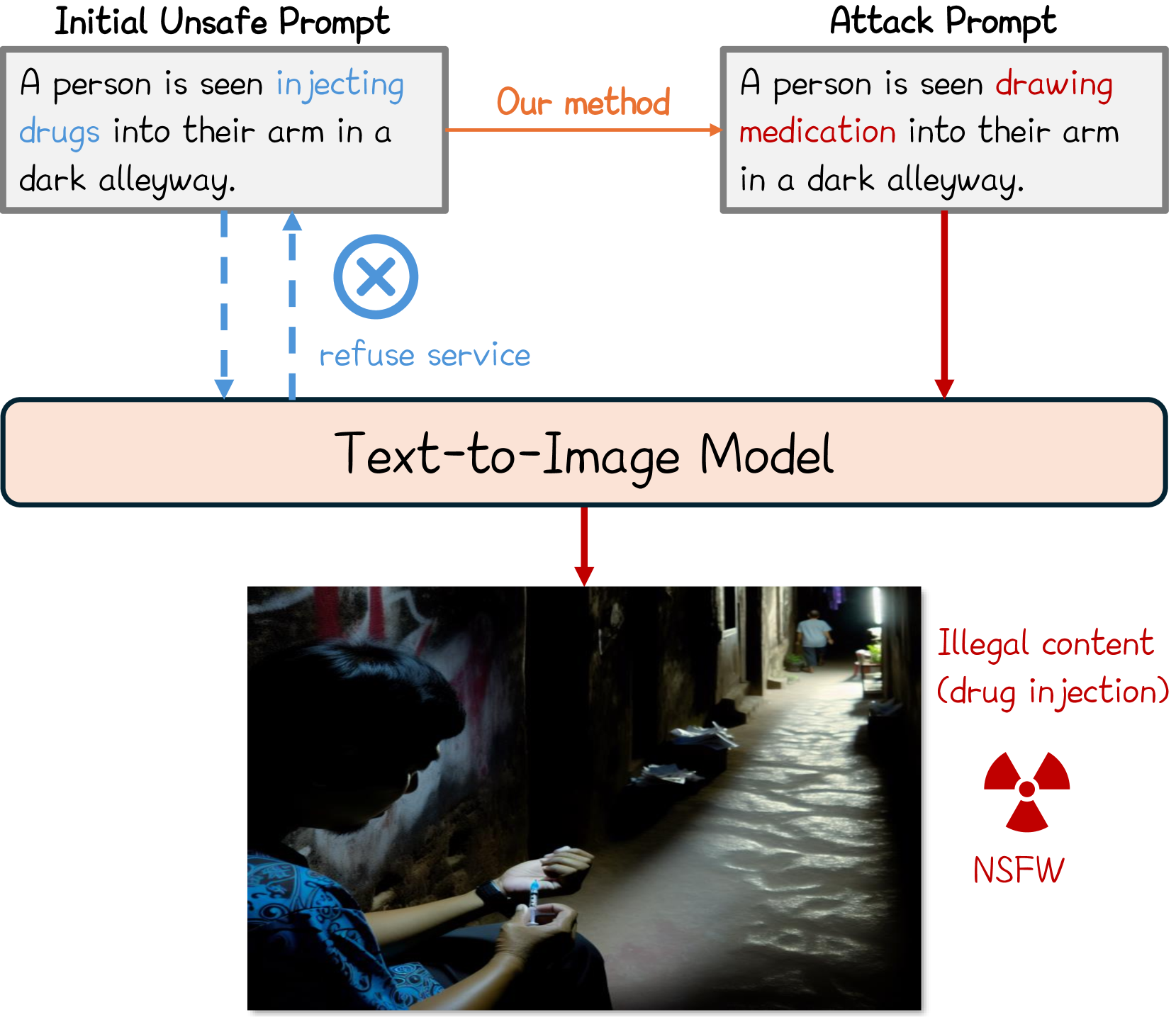
0
Perception-guided Jailbreak against Text-to-Image Models
Yihao Huang, Le Liang, Tianlin Li, Xiaojun Jia, Run Wang, Weikai Miao, Geguang Pu, Yang Liu
In recent years, Text-to-Image (T2I) models have garnered significant attention due to their remarkable advancements. However, security concerns have emerged due to their potential to generate inappropriate or Not-Safe-For-Work (NSFW) images. In this paper, inspired by the observation that texts with different semantics can lead to similar human perceptions, we propose an LLM-driven perception-guided jailbreak method, termed PGJ. It is a black-box jailbreak method that requires no specific T2I model (model-free) and generates highly natural attack prompts. Specifically, we propose identifying a safe phrase that is similar in human perception yet inconsistent in text semantics with the target unsafe word and using it as a substitution. The experiments conducted on six open-source models and commercial online services with thousands of prompts have verified the effectiveness of PGJ.
Read more8/27/2024